

Ist dir das auch schon passiert? Du siehst den Bericht “Crawl-Fehler” in der Google Search Console (früher bekannt als Webmaster Tools) und siehst so viele Crawl-Fehler, dass du nicht weißt, wo du anfangen sollst. Jede Menge 404er, 500er, “Soft 404er”, 400er und viele mehr... Hier erfährst du, wie ich mit großen Mengen von Crawl-Fehlern umgehe.
Wichtiger Hinweis: Dieser Artikel ist nicht mehr aktuell, da er sich mit Fehlerberichten aus der alten Google Search Console befasst, die es nicht mehr gibt. Kommentare sind geschlossen.
Dieser Leitfaden wurde erstmals 2015 auf rebelytics.com veröffentlicht und seitdem mehrmals aktualisiert und in diesen Blog verschoben.
Inhalt
Hier ist ein Überblick darüber, was du in diesem Artikel finden wirst:
- Keine Panik!
- Markiere zunächst alle Crawl-Fehler als behoben
- Überprüfe deinen Crawl-Fehlerbericht einmal pro Woche
- Der klassische 404 Crawl-Fehler
- 404-Fehler, die durch fehlerhafte Links von anderen Websites verursacht werden
- 404-Fehler, die durch fehlerhafte interne Links oder Sitemap-Einträge verursacht werden
- 404-Fehler, die dadurch verursacht werden, dass Google JavaScript crawlt und es durcheinander bringt ????
- Mysteriöse 404-Fehler
- Was sind “Soft 404”-Fehler?
- Was tun bei 500 Serverfehlern?
- Andere Crawl-Fehler: 400, 503, etc.
- Liste aller Krabbelfehler, die mir im “echten Leben” begegnet sind”
- Crawl-Fehlerspitze nach einer Website-Migration
- Zusammenfassung
Also lass uns loslegen. Zuallererst:
Keine Panik!
Crawl-Fehler sind etwas, das du normalerweise nicht vermeiden kannst, und sie haben nicht unbedingt eine unmittelbare negative Auswirkung auf deine SEO-Leistung. Dennoch sind sie ein Problem, das du angehen solltest. Eine niedrige Anzahl von Crawl-Fehlern in der Search Console ist ein positives Signal für Google, denn es zeigt, dass deine Website insgesamt gut funktioniert. Wenn der Google-Bot weniger Crawl-Fehler auf deiner Seite findet, ist es auch weniger wahrscheinlich, dass die Nutzer/innen Website- und Serverfehler sehen.
Markiere zunächst alle Crawl-Fehler als behoben
Das mag auf den ersten Blick wie ein dummer Ratschlag klingen, aber er hilft dir tatsächlich, deine Crawl-Fehler strukturierter anzugehen. Wenn du zum ersten Mal einen Blick auf deinen Crawl-Fehlerbericht wirfst, siehst du vielleicht Hunderte und Tausende von Crawl-Fehlern, die schon lange zurückliegen. Es wird sehr schwer für dich sein, dich in diesen langen Fehlerlisten zurechtzufinden.
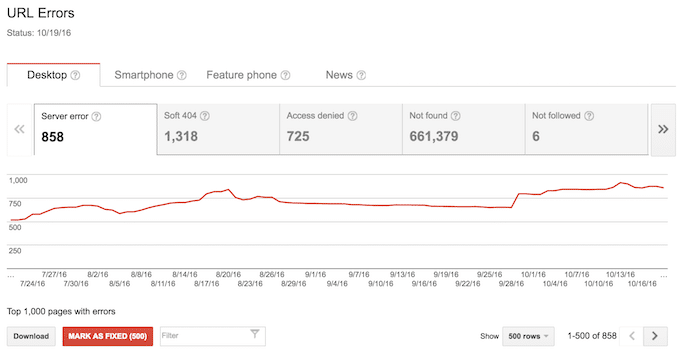
Fühlst du dich mit diesem Screenshot besser? Ich wette, du bist besser dran als dieser Webmaster ????
Mein Ansatz ist, alles als behoben zu markieren und dann von vorne anzufangen: Unwichtige Crawl-Fehler werden nicht mehr auftauchen und die, die wirklich behoben werden müssen, werden bald wieder in deinem Bericht auftauchen. Nachdem du also deinen Bericht bereinigt hast, kannst du folgendermaßen vorgehen:
Überprüfe deinen Crawl-Fehlerbericht einmal pro Woche
Wähle jede Woche einen festen Tag aus und rufe deinen Crawl-Fehlerbericht auf. Jetzt wirst du eine überschaubare Anzahl von Crawl-Fehlern finden. Da sie in der Vorwoche noch nicht da waren, weißt du, dass der Google-Bot erst kürzlich auf sie gestoßen ist. So gehst du damit um, was du einmal pro Woche in deinem Crawl-Fehlerbericht findest:
Der klassische 404 Crawl-Fehler
Dies ist wahrscheinlich der häufigste Crawl-Fehler bei Websites und auch der am einfachsten zu behebende. Für jeden 404-Fehler, auf den der Google-Bot stößt, teilt Google dir mit, woher er verlinkt ist: eine andere Website, eine andere URL auf deiner Website oder deine Sitemaps. Klicke einfach auf einen Crawl-Fehler im Bericht und eine Lightbox wie diese wird geöffnet:
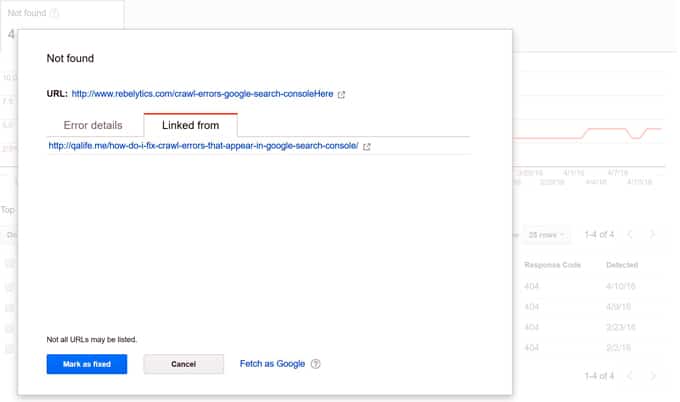
Bitte beachte, dass die Informationen auf der Registerkarte “Verknüpft von” nicht immer aktuell sind. Sie kann URLs enthalten, die es nicht mehr gibt oder die nicht mehr auf die Fehler-URL verlinken. Das liegt daran, dass Google uns in diesem Reiter mitteilt, wo es die Fehler-URL gefunden hat, und nicht, wo sie sich befindet derzeit verbunden (wie der Name schon sagt).
Wusstest du, dass du einen Bericht mit allen Crawl-Fehlern herunterladen kannst und von wo aus sie verlinkt sind? Auf diese Weise musst du nicht jeden einzelnen Crawl-Fehler manuell überprüfen. Schau dir dieser Link zum Google API-Explorer. Die meisten Felder sind bereits vorausgefüllt, so dass du nur noch die URL deiner Website (die genaue URL der Search Console-Eigenschaft, um die es geht) hinzufügen und auf “Autorisieren und ausführen” klicken musst. Lass es mich wissen, wenn du Fragen dazu hast!
Jetzt wollen wir sehen, was du gegen die verschiedenen Arten von 404-Fehlern tun kannst.
404-Fehler, die durch fehlerhafte Links von anderen Websites verursacht werden
Wenn die falsche URL von einer anderen Website verlinkt wird, solltest du einfach eine 301-Weiterleitung von der falschen URL auf ein korrektes Ziel einrichten. Vielleicht kannst du den Webmaster der verlinkenden Seite um eine Anpassung bitten, aber in den meisten Fällen lohnt sich der Aufwand nicht.
404-Fehler, die durch fehlerhafte interne Links oder Sitemap-Einträge verursacht werden
Wenn die falsche URL, die den 404-Fehler für den Google-Bot verursacht hat, von einer deiner eigenen Seiten oder von einer Sitemap verlinkt ist, solltest du den Link oder den Sitemap-Eintrag korrigieren. In diesem Fall ist es auch eine gute Idee, die 404-URL per 301-Redirect auf das richtige Ziel umzuleiten, damit sie aus dem Google-Index verschwindet und die Linkpower, die sie möglicherweise hat, weitergegeben wird.
404-Fehler, die dadurch verursacht werden, dass Google JavaScript crawlt und es durcheinander bringt ????
Manchmal stößt du auf seltsame 404-Fehler, auf die laut Google Search Console mehrere oder alle deine Seiten verlinken. Wenn du im Quellcode nach den Links suchst, wirst du feststellen, dass es sich in Wirklichkeit um relative URLs handelt, die in Skripten wie diesem hier enthalten sind (nur ein zufälliges Beispiel, das ich in einer meiner Google Search Console Eigenschaften gesehen habe):
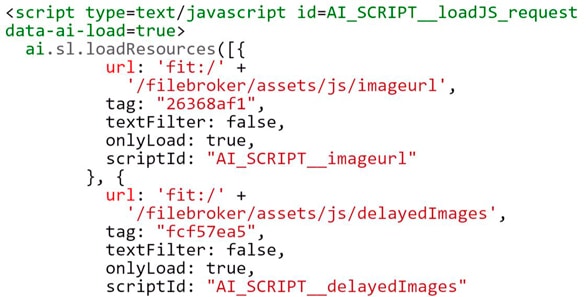
Laut Google ist das überhaupt kein Problem und diese Art von 404-Fehler kann einfach ignoriert werden. Lies Absatz 3) dieses Beitrags von John Mueller von Google für weitere Informationen (und auch den Rest, denn er ist sehr hilfreich):
Mysteriöse 404-Fehler
In manchen Fällen bleibt die Quelle des Links ein Geheimnis. Die Daten, die Google in den Crawl-Fehlerberichten bereitstellt, sind nicht immer 100% zuverlässig. Zum Beispiel sind die Informationen im Reiter “Verlinkt von” nicht immer aktuell und können URLs enthalten, die es schon seit vielen Jahren nicht mehr gibt oder die nicht mehr auf die Fehler-URLs verlinken. In solchen Fällen kannst du trotzdem eine 301-Weiterleitung für die falsche URL einrichten.
Denke daran, alle 404-Crawl-Fehler, die du behoben hast, in deinem Crawl-Fehlerbericht als behoben zu markieren. Wenn es 404-Crawl-Fehler gibt, bei denen du nicht weißt, was du tun sollst, kannst du sie trotzdem als behoben markieren und in einer “Geheimliste” sammeln. Sollten sie immer wieder auftauchen, weißt du, dass du dem Problem auf den Grund gehen musst. Wenn sie nicht mehr auftauchen, ist das umso besser.
Wenn du einen Fall von mysteriösen 404-Fehlern hast, kannst du mir gerne einen Kommentar am Ende dieses Artikels hinterlassen. Ich werde mir dein Problem gerne ansehen.
Schauen wir uns jetzt die seltsame Spezies der “Soft 404-Fehler” an.
Was sind “Soft 404”-Fehler?
Das ist etwas, das Google erfunden hat, oder? Zumindest habe ich nirgendwo sonst von “Soft 404”-Fehlern gehört. Ein “Soft 404”-Fehler ist eine leere Seite, auf die der Google-Bot gestoßen ist und die einen 200-Statuscode zurückgegeben hat.
Es handelt sich also um eine Seite, von der Google DENKT, dass sie eine 404-Seite sein sollte, die es aber nicht ist. Seit 2014 erhalten Webmaster/innen “Soft 404”-Fehler für einige ihrer eigentlichen Inhaltsseiten. Das ist Googles Art, uns mitzuteilen, dass wir “dünnen Inhalt” auf unseren Seiten haben.
Der Umgang mit “Soft 404”-Fehlern ist genauso einfach wie der mit normalen 404-Fehlern:
- Wenn die URL des “Soft 404”-Fehlers nicht existieren soll, leite sie per 301 auf eine bestehende Seite um. Achte auch darauf, dass du das Problem der nicht existierenden URLs behebst, die keinen korrekten 404-Fehlercode zurückgeben.
- Wenn die URL der “Soft 404”-Seite eine deiner eigentlichen Inhaltsseiten ist, bedeutet das, dass Google sie als “dünnen Inhalt” betrachtet. In diesem Fall solltest du sicherstellen, dass du deiner Website wertvolle Inhalte hinzufügst.
Nachdem du deine “Soft 404”-Fehler abgearbeitet hast, denke daran, sie alle als behoben zu markieren. Als Nächstes werfen wir einen Blick auf die wilden Arten von 500 Serverfehlern.
Was tun bei 500 Serverfehlern?
500 Serverfehler sind wahrscheinlich die einzige Art von Crawl-Fehlern, über die du dir ein wenig Sorgen machen solltest. Wenn der Google-Bot regelmäßig auf Serverfehler auf deiner Seite stößt, ist das ein sehr starkes Signal für Google, dass etwas mit deiner Seite nicht stimmt, und es wird letztendlich zu schlechteren Rankings führen.
Diese Art von Crawl-Fehler kann aus verschiedenen Gründen auftreten. Manchmal ist es eine bestimmte Subdomain, ein bestimmtes Verzeichnis oder eine Dateierweiterung, die dazu führt, dass dein Server statt einer Seite einen 500er Statuscode zurückgibt. Dein/e Website-Entwickler/in kann das Problem beheben, wenn du ihm/ihr eine Liste der letzten 500 Serverfehler aus den Google Webmaster Tools schickst.
Manchmal tauchen 500 Serverfehler in der Google Search Console auf, weil es ein vorübergehendes Problem gibt. Es kann sein, dass der Server aufgrund von Wartungsarbeiten, Überlastung oder höherer Gewalt eine Zeit lang nicht erreichbar war. Normalerweise kannst du das herausfinden, indem du deine Logdateien überprüfst und mit deinem Entwickler oder Website-Hoster sprichst. In einem solchen Fall solltest du versuchen, dafür zu sorgen, dass ein solches Problem in Zukunft nicht mehr auftritt.
Achte auf die Serverfehler, die in deinen Google Webmaster Tools angezeigt werden, und versuche, ihr Auftreten so weit wie möglich zu begrenzen. Der Google-Bot sollte immer in der Lage sein, ohne technische Hindernisse auf deine Seiten zuzugreifen.
Werfen wir einen Blick auf einige andere Crawl-Fehler, über die du in deinen Google Webmaster Tools stolpern könntest.
Andere Crawl-Fehler: 400, 503, etc.
Wir haben uns in diesem Artikel mit den wichtigsten und häufigsten Crawl-Fehlern beschäftigt: 404, “Soft 404” und 500. Hin und wieder kannst du auch andere Crawl-Fehler finden, wie 400, 503, “Zugriff verweigert”, “Fehlerhafte Weiterleitungen” (für Smartphones) und so weiter.
In vielen Fällen bietet Google einige Erklärungen und Ideen, wie du mit den verschiedenen Arten von Fehlern umgehen kannst.
Generell ist es eine gute Idee, jede Art von Crawl-Fehler, die du findest, zu bearbeiten und zu vermeiden, dass sie in Zukunft wieder auftauchen. Je weniger Crawl-Fehler der Google-Bot feststellt, desto mehr Vertrauen hat Google in den Zustand deiner Website. Bei Seiten, die ständig Crawl-Fehler verursachen, wird davon ausgegangen, dass sie ein schlechtes Nutzererlebnis bieten und schlechter gerankt werden als gesunde Websites.
Mehr Informationen über die verschiedenen Arten von Crawl-Fehlern findest du im nächsten Teil dieses Artikels:
Liste aller Krabbelfehler, die mir im “echten Leben” begegnet sind”
Ich dachte, es wäre vielleicht interessant, eine Liste aller Arten von Crawl-Fehlern zu erstellen, die ich in der Google Search Console gesehen habe, an der ich gearbeitet habe. Ich habe nicht viele Informationen zu allen Fehlern (außer den oben genannten), aber hier sind sie:
Server-Fehler (500)
In diesem Bericht listet Google URLs auf, die einen 500-Fehler zurückgegeben haben, als der Google-Bot versucht hat, die Seite zu crawlen. Siehe über für weitere Details.
Weich 404
Das sind URLs, die einen 200-Statuscode zurückgegeben haben, aber laut Google einen 400-Fehler zurückgeben sollten. Ich habe einige Lösungen für dieses Problem vorgeschlagen über.
Zugriff verweigert (403)
Hier listet Google alle URLs auf, die einen 403-Fehler zurückgegeben haben, als der Google-Bot versucht hat, sie zu crawlen. Achte darauf, dass du nicht auf URLs verlinkst, die eine Authentifizierung erfordern. Du kannst “Zugriff verweigert”-Fehler für Seiten ignorieren, die du in deine robots.txt-Datei aufgenommen hast, weil du nicht willst, dass Google auf sie zugreift. Es könnte jedoch eine gute Idee sein, nofollow Links zu verwenden, wenn du auf diese Seiten verlinkst, damit Google nicht immer wieder versucht, sie zu crawlen.
Nicht gefunden (404 / 410)
“Nicht gefunden” ist der klassische 404-Fehler, der diskutiert wurde über. Lies die Kommentare für einige interessante Informationen über 404 und 410 Fehler.
Nicht befolgt (301)
Der Fehler “not followed” bezieht sich auf URLs, die auf eine andere URL umleiten, aber die Umleitung funktioniert nicht. Repariere diese Weiterleitungen!
Sonstiges (400 / 405 / 406)
Hier fasst Google alles zusammen, wofür es keinen Namen hat: Ich habe 400, 405 und 406 Fehler in diesem Bericht gesehen und Google sagt, dass es die URLs “aufgrund eines unbestimmten Problems” nicht crawlen konnte. Ich schlage vor, dass du diese Fehler genauso behandelst wie normale 404 Fehler.
Flash-Inhalte (Smartphone)
Dieser Bericht listet einfach Seiten mit vielen Flash-Inhalten auf, die auf den meisten Smartphones nicht funktionieren. Mach Schluss mit Flash!
Blockiert (Smartphone)
Dieser Fehler bezieht sich auf Seiten, auf die der Google-Bot zugreifen könnte, die aber für den mobilen Google-Bot in deiner robots.txt-Datei gesperrt wurden. Stelle sicher, dass alle Google-Bots auf die Inhalte zugreifen können, die du indiziert haben möchtest!
Bitte lass mich wissen, wenn du Fragen oder zusätzliche Informationen zu den oben genannten Crawl-Fehlern oder anderen Arten von Crawl-Fehlern hast.
Crawl-Fehlerspitze nach einer Website-Migration
Nach einer Website-Migration kannst du mit einem Anstieg der Crawl-Fehler rechnen. Selbst wenn du alles in deiner Macht stehende getan hast, um deine Migration aus der SEO-Perspektive vorbereiten, ist es sehr wahrscheinlich, dass der Google-Bot nach dem Relaunch auf eine große Anzahl von 404-Fehlern stoßen wird.
Wenn die Anzahl der Crawl-Fehler in deinen Google Webmaster Tools nach einer Migration ansteigt, gibt es keinen Grund zur Panik. Befolge einfach die oben beschriebenen Schritte und versuche, in den Wochen nach der Migration so viele Crawl-Fehler wie möglich zu beheben.
Zusammenfassung
- Markiere alle Crawl-Fehler als behoben.
- Gehe einmal pro Woche zu deinem Bericht zurück.
- Behebe 404-Fehler, indem du falsche URLs umleitest oder deine internen Links und Sitemap-Einträge änderst.
- Versuche, Serverfehler zu vermeiden und bitte deinen Entwickler und Server-Host um Hilfe.
- Kümmere dich um die anderen Arten von Fehlern und verwende Googles Ressourcen für Hilfe.
- Rechne nach einer Website-Migration mit einem Anstieg der Crawl-Fehler.
Wichtiger Hinweis: Dieser Artikel ist nicht mehr aktuell, da er sich mit Fehlerberichten aus der alten Google Search Console befasst, die es nicht mehr gibt. Kommentare sind geschlossen.
340 Antworten
Guter Beitrag! Ich habe ein ähnliches Problem und weiß einfach nicht, wie ich es angehen soll. Die Google-Suchkonsole zeigt an, dass 69 Seiten Fehler haben und ich habe herausgefunden, dass die 404-Fehler immer dann auftauchen, wenn ein ‘/’ nach der URL hinzugefügt wird.
Hallo Ossai,
Google crawlt nur URLs, die irgendwo verlinkt sind. Du solltest also zunächst versuchen, die Quelle des Problems zu finden. In der Search Console findest du Informationen darüber, woher die fehlerhaften URLs verlinkt sind. Es ist sehr wahrscheinlich, dass du irgendwo auf deiner Seite oder in deiner Sitemap auf die URLs mit dem abschließenden Schrägstrich verlinkst, die 404er zurückgeben. Du solltest diese Links korrigieren.
Als Nächstes kannst du dafür sorgen, dass alle URLs, die mit einem Schrägstrich enden, auf dieselbe URL ohne nachgestellten Schrägstrich umgeleitet werden. Das solltest du nur tun, wenn alle deine URLs ohne abschließenden Schrägstrich funktionieren. Dafür brauchst du nur eine Zeile in deiner htaccess-Datei.
Wenn du weitere Fragen hast, helfe ich dir gerne weiter.
Ich habe im Moment genau dieses Problem. Kannst du mir den richtigen htaccess-Code erklären?
Hallo Chris,
Ich bin wirklich kein Experte für das Erstellen von Rewrite-Regeln in htaccess-Dateien, also verlass dich nicht darauf, aber bei mir funktioniert das:
RewriteRule ^(.*)/$ /$1 [R,L]
Stelle sicher, dass du sie nur für die URLs verwendest, für die du sie verwenden willst, indem du eine Rewrite-Bedingung einstellst.
Ich hoffe, das hilft!
Hallo
Guter Beitrag! Ich bekomme viele 500 Fehler in GWT, weil ich meine Feeds deaktiviert habe! Was soll ich damit machen?
Ich habe Feeds deaktiviert, weil andere Websites meine Inhalte klauen!
Kannst du mir helfen?
Danke
Hallo Artin, ich bin mir nicht ganz sicher, ob ich dein Problem richtig verstehe. Welche URLs geben 500 Fehler zurück? Die URLs deiner Feeds? Verlinkst du noch auf sie? Wenn ja, solltest du die Links auf jeden Fall entfernen. Du kannst auch prüfen, ob es möglich ist, für deine Feed-URLs eine 404 statt einer 500 zurückzugeben. Das wäre ein besseres Signal für Google. Es könnte sogar eine gute Idee sein, die URLs deiner Feeds per 301 auf Seiten auf deiner Website umzuleiten, wenn du für jede Feed-URL eine gute Übereinstimmung findest. Wenn du dein Problem genauer erklärst, helfe ich dir gerne weiter.
Hey Eoghan
Danke für deine Antwort! Ich habe ein Plugin mit dem Namen ”disable feeds” gefunden, das alle Feeds auf die Homepage umleitet. Damit bin ich diese 500 Fehler los!.
Hallo Artin, vielen Dank, dass du die Infos über das Plugin geteilt hast. Klingt nützlich!
Ich habe eine neue Website gestartet und aus irgendeinem Grund erhalte ich eine Fehlermeldung 500 für eine Reihe von URLs in den Webmaster-Tools, einschließlich der Sitemap selbst. Wenn ich meine Protokolle für den Zugriff auf das Sitemap-Beispiel überprüfe, zeigt es, dass Google auf die Sitemap zugegriffen hat und keine Fehler zurückgegeben wurden:
66.249.64.210 - - [29/Oct/2015:02:19:31 +0000] “GET /sitemap.php HTTP/1.1” - 10322 “-” “Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)”
Auch wenn ich eine dieser URLs aufrufe, erscheinen sie einwandfrei.
Danke
Hallo Greg, das sieht für mich nach einem vorübergehenden Problem aus. Ich würde vorschlagen, dass du die entsprechenden Fehler im Crawl-Fehlerbericht als behoben markierst und schaust, ob sie wieder auftauchen. Wenn sie nicht mehr auftauchen, ist alles in Ordnung.
Hi....Eoghan Henn
Ich weiß nicht, was ich mit euren Tipps machen soll. Ich werde die Fehler als behoben markieren, weil diese URLs auf meiner Website nicht verfügbar sind. Ich habe diese URLs entfernt, aber das Problem ist, dass eine Landing Page den Fehlercode 521 erhält. Ich habe darüber gegoogelt, aber ich habe keine gute Lösung gefunden. Das große Problem ist, dass meine Startseite nur von Google gecrawlt wird, während andere Seiten nicht gecrawlt werden, obwohl ich Sitemaps eingereicht habe und Google Fetch us verwendet. Bitte hilf mir und überprüfe die Fehlerdetails meiner Website unten......
hammer-testing-training-in-chennai.php
521
11/2/15
2
blog/?p=37
500
12/27/15
8
blog/?m=201504
500
12/7/15
13
userfiles/zyn2593-reys-kar-1623-moskva-rodos-ros6764.xml
521
11/2/15
14
userfiles/cez3214-aviabileti-kompanii-aer-astana-myv9933.xml
521
11/3/15
17
userfiles/wyz5836-bileti-saratov-simferopol-tsena-gif9086.xml
521
11/3/15
Hallo Arun,
Zunächst einmal möchte ich mich für meine späte Antwort entschuldigen. Ich war in letzter Zeit sehr beschäftigt und habe keine Zeit gefunden, auf die Kommentare hier zu antworten.
Du hast das Richtige getan, indem du die Fehler als behoben markiert und abgewartet hast, ob sie wieder auftreten. Vor allem 5xx-Fehler sind normalerweise vorübergehend. Ist einer dieser Fehler erneut aufgetreten?
Das andere Problem, dass wichtige Seiten nicht indiziert werden, hängt wahrscheinlich nicht mit dem Crawl-Fehlerproblem zusammen. Ich bin nicht in der Lage, die Ursache für dieses Problem ohne weitere Nachforschungen zu bestimmen, aber ich habe ein sehr wichtiges Problem auf deiner Website gefunden, das du lösen musst, wenn du willst, dass deine Seiten richtig indiziert werden:
In deiner Hauptnavigation sind einige wichtige Seiten nicht direkt verlinkt, sondern über URLs, die eine 302-Weiterleitung zum Ziel haben. Beispiel:
/hammer-testing-training-in-chennai.php ist in der Hauptnavigation als /index.php?id=253 verlinkt.
/index.php?id=253 leitet zu /hammer-testing-training-in-chennai.php mit einem 302 Statuscode weiter. Es überrascht mich nicht, dass Google in diesem Fall keine der beiden Seiten indexiert. Du solltest darauf achten, dass du immer direkt auf die Ziel-URL verlinkst und Weiterleitungen in internen Links unbedingt vermeiden. Und im Allgemeinen gibt es nur sehr wenige Fälle, in denen ein 302-Redirect erforderlich ist. Normalerweise brauchst du eine 301-Weiterleitung, wenn du eine URL weiterleiten musst.
Ich bin mir nicht sicher, ob dies alle deine Probleme lösen wird, aber die Korrektur deiner internen Links ist definitiv ein wichtiger Punkt auf deiner To-Do-Liste. Bitte lass mich wissen, wenn du weitere Fragen hast.
Eoghan,,
Vielen Dank! Unser Entwicklungsteam nutzt deinen Rat, denn wir haben ganz ähnliche Probleme mit Crawl-Fehlern. In diesem Zusammenhang versuche ich, den Zusammenhang zwischen Crawl-Fehlern und indexierten URLs zu verstehen. Wenn unsere URLs indexiert sind, schneiden wir bei den organischen Suchanfragen sehr gut ab. Wir haben Millionen von URLs in unserer eingereichten Sitemap. In der Google Search Console ist die Zahl der indexierten URLs am 4. Januar von Null auf 100.000 gestiegen, aber seither ist sie ungefähr auf diesem Niveau geblieben. Sollten wir erwarten, dass die indexierten URLs steigen, wenn wir die Crawl-Fehler beheben?
Vielen Dank!,
Dermid
Hallo Dermid,
Vielen Dank für deinen Kommentar und deine interessante Frage.
Crawl-Fehler und indexierte URLs stehen nicht immer in direktem Zusammenhang. 404-Fehler treten normalerweise auf, wenn der Googlebot auf fehlerhafte URLs stößt, die gar nicht gecrawlt werden sollen, zum Beispiel durch defekte Links. Serverfehler hingegen können bei URLs auftreten, die eigentlich indexiert werden sollten. Wenn du diese Fehler behebst, kann das zu einer höheren Anzahl indexierter URLs führen.
Wenn du Millionen von URLs in deiner Sitemap hast, aber nur 100k davon indexiert sind, solltest du daran arbeiten, diese Lücke zu schließen. Zuallererst solltest du prüfen, ob du wirklich Millionen von URLs in deiner Sitemap haben willst oder ob viele dieser Seiten nicht relevante Einstiegsseiten für Nutzer sind, die in Google nach deinen Produkten oder Dienstleistungen suchen. Es ist besser, eine geringere Anzahl von qualitativ hochwertigen Seiten zu haben als eine höhere Anzahl von Seiten mit geringer Qualität für die Indexierung.
Prüfe als Nächstes, warum ein großer Teil der URLs, die du in deinen Sitemaps angegeben hast, nicht von Google indexiert wurde. Beachte, dass die Übermittlung einer URL in einer Sitemap allein normalerweise nicht zu einer Indexierung führt. Google braucht mehr Signale, um zu entscheiden, ob eine Seite indiziert wird. Wenn eine große Anzahl von Seiten auf deiner Domain nicht indiziert wird, liegt das normalerweise an einer schlechten internen Verlinkung der Seiten oder an schlechten Inhalten auf den Seiten. Vergewissere dich, dass alle Seiten, die in den Google-Index aufgenommen werden sollen, intern richtig verlinkt sind und dass sie alle Inhalte haben, die die Bedürfnisse der Nutzer/innen befriedigen, die nach den Keywords suchen, für die du ranken willst.
Ich hoffe, das hilft!
Eoghan
Eoghan,
Danke für den sehr guten Beitrag. Eine verwandte Frage: Ich erhalte drei verschiedene Zahlen für die von Google indexierten Seiten. 1) Wenn ich site:mysite.com eingebe, erhalte ich 200.000 Seiten, 2) wenn ich den Indexstatus in der Google Search Console anschaue, werden 117.000 Seiten angezeigt und 3) wenn ich die gecrawlte Sitemap anschaue, werden nur 67 indizierte Seiten angezeigt. Kannst du mir helfen, diese unterschiedlichen Indexzahlen zu verstehen? Vielen Dank!.
Dermid
Hallo nochmal! Du bekommst hier unterschiedliche Zahlen, weil du drei verschiedene Dinge betrachtest:
1) site:mysite.com zeigt dir alle Seiten deiner Domain an, die sich derzeit im Index befinden. Dazu gehören alle Subdomains (www, non-www, mobile Subdomain) und beide Protokolle (http und https).
2) zeigt dir alle indexierten Seiten innerhalb der Search Console-Eigenschaft an, die du betrachtest. Eine Search-Console-Eigenschaft kann nur URLs mit einer Kombination aus einem Protokoll und einer Subdomain enthalten, wenn also der Name deiner Search Console lautet https://www.mysite.com/, nur URLs, die mit https://www.mysite.com/ (und die indiziert sind) werden hier angezeigt.
3) zeigt dir alle URLs, die in genau dieser Sitemap enthalten sind und indiziert werden.
Ich habe https, http, www, non-www und m. (mobile subdomain) Seiten deiner Domain im Google-Index gefunden. Du solltest sicherstellen, dass alle deine Seiten nur mit https erreichbar sind und entscheiden, ob du www verwenden willst oder nicht (das ist eine Geschmacksfrage). Du kannst dies ganz einfach mit zwei 301-Weiterleitungsregeln einrichten: Eine, die jede http-URL auf ihr https-Äquivalent umleitet, und eine, die alle Nicht-www-URLs auf ihr www-Äquivalent umleitet (oder umgekehrt). Zu guter Letzt solltest du sicherstellen, dass du die richtige Search Console-Eigenschaft verwendest (also https://www.mysite.com/ oder https://mysite.com/, (je nachdem, wie du dich für www oder non-www entscheidest) und erstelle eine Sitemap mit allen URLs, die du indiziert haben möchtest.
Wenn du das befolgt hast, solltest du daran arbeiten, die Lücke zwischen 1), 2) und 3) zu schließen. Wenn du eine gesunde Website hast und die Kontrolle darüber hast, was Google indexiert, sollten alle drei Zahlen auf einem ähnlichen Niveau liegen.
Hey Eoghan - ich sehe, dass deine Website mit WordPress erstellt wurde, also habe ich gehofft, du könntest meine Frage beantworten.
Ich habe vor kurzem meine Sitemap erneut eingereicht (da ich dachte, es wäre eine gute Sache, nachdem ich /go/ in meiner robots.txt für Affiliate-Links verboten hatte) und ein paar Tage nach dem erneuten Crawling sehe ich jetzt einen neuen 500-Fehler:
/wp-content/themes/mytheme/
Andere Anmerkungen:
- Das war nicht der Fall, bevor ich meine Sitemap erneut eingereicht habe, und es ist der einzige 500-Fehler, den ich gesehen habe, seit ich meine Website vor ein oder zwei Monaten gestartet habe.
- Ich weiß auch, dass mein Webhost (Bluehost) dazu neigt, manchmal auszufallen. Vielleicht liegt es daran, dass Google versucht hat, die Seite zu crawlen, wenn sie ausgefallen ist?
- Ich habe mein Theme ein paar Tage vor dem Auftreten des 500-Fehlers aktualisiert.
Muss ich etwas unternehmen? Gibt es weitere Informationen, die ich geben kann?
Danke - ich weiß das zu schätzen.
Hallo Josh! Danke für deinen Kommentar.
Zuallererst: Das ist nichts, worüber du dir Sorgen machen solltest, aber wenn du Zeit hast, kannst du auch versuchen, es zu reparieren 😉 .
Anscheinend gibt die von dir erwähnte URL immer einen 500er Serverfehler zurück. Sieh dir das an: Ich verwende ein WP-Theme namens “Hardy” und genau dieselbe URL für meine Seite und mein Theme gibt auch einen 500er Serverfehler zurück: https://www.rebelytics.com/wp-content/themes/hardy/. Es ist also nicht die Schuld von Bluehost. (Spaßfakt: Wahrscheinlich bekomme ich jetzt eine 500er-Fehlermeldung, weil ich den Link gerade hier platziert habe).
Jetzt stellt sich die Frage: Warum hat der Google-Bot deine Themen-URL überhaupt erst gecrawlt? Verlinkt ihr in eurer neuen Sitemap auf sie? Wenn ja, solltest du den Link entfernen. Deine Sitemap sollte nur Links zu URLs enthalten, die du indexiert haben möchtest. Du kannst überprüfen, wo der Googlebot den Link zur URL gefunden hat (wie im Artikel oben erwähnt). Hier ist ein Screenshot davon:
Wenn du irgendwo einen Link zu dieser URL findest, entferne ihn einfach. Ansonsten kannst du diesen Crawl-Fehler einfach ignorieren. Es wäre interessant, ihn als behoben zu markieren und zu sehen, ob er wieder auftaucht. Lass mich wissen, wie es läuft! Und sag mir Bescheid, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Super - danke für die Antwort. Er ist in meiner Sitemap nicht verlinkt und wenn ich in GWT auf den Link klicke, wird nicht angezeigt, von wo aus er verlinkt ist. Es freut mich zu hören, dass es kein Problem ist.
Ich hatte noch 2 weitere kurze Fragen:
Muss ich mich generell nur um Crawl-Fehler/Warnungen für relevante Webseiten kümmern (Webseiten, die ich indiziert haben möchte, und Webseiten, die umgeleitet werden sollten, da sie angeklickt werden)? Es werden einige Warnungen angezeigt für:
/m
/Mobil
/Künftig
Keine Ahnung, wie sie erschienen sind, und es wird angezeigt, dass sie von meiner Homepage verlinkt sind, obwohl ich keine Ahnung habe, wie das möglich ist.
Außerdem wurden meine Amazon-Affiliate-Links (getarnt mit /go/) vor ein paar Wochen indexiert. Vor etwa einer Woche habe ich rel=”nofollow” für jeden Link gesetzt und außerdem “Disallow” hinzugefügt: /go/“ unter ”User-agent: *" in meiner robots.txt.
Es ist jetzt eine Woche her, und meine Affiliate-Links werden immer noch indiziert, wenn ich “site:mysite.com” eingebe. Glaubst du, dass ich etwas übersehe, und wie kann ich herausfinden, ob ich immer noch dafür bestraft werde?
Danke für die Hilfe - ich weiß das sehr zu schätzen.
Hallo Josh! Tut mir leid, dass ich so lange gebraucht habe, um dir zu antworten. Du hast Recht, du solltest dich mehr um Crawl-Fehler für relevante Seiten kümmern, die du indiziert haben möchtest. Trotzdem ist es immer eine gute Idee, auch alle anderen Crawl-Fehler unter die Lupe zu nehmen und zu versuchen, sie in Zukunft zu vermeiden. Manchmal kannst du allerdings nicht viel tun (wie bei dem JavaScript-Beispiel im Artikel).
Welche Art von Weiterleitungen verwendest du für deine Amazon-Partnerlinks? Achte darauf, dass du eine 301-Weiterleitung verwendest, damit sie nicht indiziert werden.
Ich hoffe, das hilft!
Ich habe das gleiche Problem wie Josh. Aber in meinem Fehlerbericht gibt es keinen Reiter für “verlinkt von”. Das verwirrt mich. Warum versucht Google, wp-content/themes/blabla zu indexieren, obwohl nirgendwo ein “linked from” steht 😀 .
Ich denke, ich markiere einfach als repariert und schaue, was als nächstes passiert. Danke Eoghan Henn
Beste Grüße aus Indonesien
Hallo Jimmy,
Im Reiter “Verlinkt von” sind nicht immer Informationen verfügbar. In WordPress wird die URL des Themas auf den meisten Websites in irgendeinem Kontext im Quellcode angezeigt, und Google folgt einfach diesen “Links”. Diese Art von Fehler ist wirklich nichts, worüber du dir Sorgen machen musst.
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan,
Gibt es eine Idee, wie größere Kleinanzeigenseiten mit der Suchkonsole umgehen?
Zum Beispiel Immobilien mit mehreren Anzeigen, die nach einem bestimmten Datum ablaufen und etwa 30k “404” oder so haben. Was würdest du vorschlagen, um mit einer solchen Menge an abgelaufenen Inhalten umzugehen?
Vielen Dank im Voraus,
Hallo Daniel,
Vielen Dank für deine interessante Frage. Ich habe keine praktische Erfahrung mit einem solchen Fall, aber ich möchte dir ein paar Gedanken dazu mitteilen:
Ich hoffe, das hilft!
Google behandelt eine 410 wie eine 404. https://support.google.com/webmasters/answer/35120?hl=en unter URL-Fehlertypen > Allgemeine URL-Fehler > 404: “Wenn du Inhalte dauerhaft löschst, ohne sie durch neuere, verwandte Inhalte ersetzen zu wollen, lass die alte URL eine 404 oder 410 zurückgeben. Derzeit behandelt Google 410 (Gone) genauso wie 404 (Not found).”
Hallo Jules,
Danke für den Link zu dieser Quelle. Trotzdem denke ich, dass ein 410-Fehlercode die bessere Wahl ist, wenn Inhalte absichtlich entfernt werden. Wir haben keinen Einfluss darauf, wie Google unsere Signale interpretiert, aber wir sollten alles tun, um sie so konsistent wie möglich zu gestalten.
Hallo Eoghan,
Ich wollte dir nur einen Daumen hoch geben! Toller Beitrag und super nützlich für mich, als ich heute einen Haufen 404er auf der Website eines Kunden entdeckte, der gerade von einer HTML-Site auf eine Wordpress-Site umgestiegen ist, und zwar für einige der Seiten, für die sie früher gerankt haben, z.B. somepage.html.
Ich habe SEMRush verwendet, um so viele Seiten wie möglich zu finden, für die sie zuvor gerankt hatten, und sie auf eine bestimmte, relevante Seite umgeleitet und, wenn das nicht möglich war, auf Kategorie- oder allgemeine Themenseiten.
Die verbleibenden Crawl-Fehler (404s) in Search Console sind einige Seiten, die in SEMRush nicht auftauchten, und natürlich Dinge wie “http://myclientsite.com/swf/images.swf”. Da wir vernünftigerweise kein Flash mehr verwenden, denke ich, dass ich mir darüber keine Sorgen mache? Ich bin mir nicht ganz sicher.
Vielen Dank für den tollen Beitrag!
Hallo Chris,
Danke für deine netten Worte! Ich freue mich, dass dieser Artikel dir geholfen hat.
Ja, du kannst die Fehler in der swf-Datei einfach ignorieren. Wenn du sie als behoben markierst, werden sie wohl nicht mehr auftauchen.
Hallo Eoghan Henn,
Ich habe über 1000 "404 nicht gefunden"-Fehler in der Google-Suchkonsole für gelöschte Produkte. Was muss ich tun, um diese Fehler zu beheben? Kannst du mir bitte einen Vorschlag machen, wie ich sie beheben kann?.
Danke
Vicky
Hallo Vicky,
Wenn du eine Produktseite löschen musst, hast du ein paar Möglichkeiten:
Ich hoffe, das hilft!
Hallo Eoghan,
Danke für deine Antwort,
Ich habe sie als repariert markiert, damit Google sie nicht mehr crawlt. Ja, es gibt einige gelöschte Seiten, die intern und extern verlinkt sind. Ich werde diese gelöschten Produkte auf ähnliche Produkte umleiten.
Ich werde dich bald über das Update informieren.
Nochmals danke für die Antwort!
Hallo Vicky,
Nur zur Klarstellung: Wenn du die Fehler als behoben markierst, wird Google nicht aufhören, sie zu crawlen. Das kann nur erreicht werden, indem alle Links zu den URLs entfernt werden.
Ich freue mich darauf zu hören, wie es bei dir gelaufen ist!
Hallo Eoghan.
Danke für die tollen Informationen in diesem Artikel! Ich habe ein (für mich) interessantes Problem mit einigen Crawl-Fehlern auf unserer Website. Die Gesamtzahl der 404-Fehler liegt unter 200 und einige davon kann ich mit deiner obigen Information abgleichen. Aber es gibt eine ganze Reihe von URLs, die nicht richtig aufgelöst werden, weil “ChiefStrategyOfficer” an die URLs angehängt wurde. Zum Beispiel endet die URL mit “...personal-information-augmented-reality-systems/ChiefStrategyOfficer” und die verlinkte von URL ist der Link auf unserer Seite.
Ich werde alles als “behoben” markieren und sehen, was passiert, aber ich frage mich, ob du eine Idee hast, wie das passiert sein könnte?
Danke y ¡Saludos! aus BCN...
Steven
Hallo Steven,
Danke für deinen Kommentar! Ich habe deine Website gefunden, sie gecrawlt und einige interessante Dinge gefunden, die dir helfen könnten. Ich werde dir eine E-Mail darüber schicken.
Mit freundlichen Grüßen,
Eoghan
Hi,
Nach einer Fehlkonfiguration einer anderen meiner Websites hat Google eine Menge nicht existierender Seiten indexiert und jetzt erscheinen alle diese Seiten in Crawl-Fehlern.
Ich habe versucht, sie als 410-Fehler einzustellen, um zu sagen, dass es sie nicht mehr gibt, aber Google behält sie in der Crawl-Fehlerliste.
Weißt du, was in diesem Fall am besten zu tun ist? Und ganz allgemein für jede Seite, die dauerhaft gelöscht wird.
Hallo Dr. Emixam,
Vielen Dank für deinen Kommentar und Entschuldigung für meine späte Antwort.
Nach dem, was du beschrieben hast, hast du alles richtig gemacht. Vergiss nur nicht, die Fehler als behoben zu markieren, sobald du Änderungen an deiner Seite vorgenommen hast. Auf diese Weise sollten sie nicht mehr auftauchen.
Lass mich wissen, wenn du weitere Fragen hast.
Nur um das klarzustellen: Das Zurückgeben eines 410-Codes allein verhindert nicht, dass die URLs in den 404-Fehlerberichten auftauchen - Google zeigt 410-Fehler derzeit als 404-Fehler an. Um zu verhindern, dass die URLs in den Berichten auftauchen, müssen auch alle Links zu den URLs entfernt werden. Andernfalls wird Google den Links weiter folgen, die URLs crawlen und die Fehler in den Berichten anzeigen. Wenn es externe Links zu den URLs gibt, die nicht entfernt werden können, ist es vielleicht besser, eine 301-Weiterleitung zu verwenden, die auf eine andere URL zeigt, die für den Link relevant ist.
Update: 410-Fehler werden jetzt als 410-Fehler in der Google Search Console angezeigt und nicht mehr als 404-Fehler markiert.
Ich mag diese Strategie.
Gibt es eine Möglichkeit, die “verlinkt von”-Informationen im 404-Bericht herunterzuladen? Das würde es viel einfacher machen, die vollständigen Details an mein IT-Team zu schicken.
Hallo Chris,
Nein, nicht dass ich wüsste. Ich überprüfe die Links manuell, was manchmal eine Menge Arbeit sein kann 🙁
Hallo Chris,
Ich habe ein wenig recherchiert und herausgefunden, dass du diese Informationen tatsächlich über die Search Console API erhalten kannst. Schau dir das an:
https://developers.google.com/apis-explorer/#p/webmasters/v3/webmasters.urlcrawlerrorssamples.get?fields=urlDetails%252FlinkedFromUrls&_h=1&
Ich habe es für einzelne URLs getestet und es funktioniert. Jetzt versuche ich, einen einfachen Weg zu finden, um es für eine Reihe von URLs zu machen. Wenn ich etwas Zeit habe, werde ich versuchen, damit voranzukommen und dich auf dem Laufenden halten.
Das sind tolle Neuigkeiten. Danke, dass du das mit uns geteilt hast, Eoghan. Halt mich auf dem Laufenden!
-Chris
Hallo Chris,
Für den Moment empfehle ich dir, den Search Console API Explorer von Google zu verwenden. Wenn du diesem Link folgst, sind die Felder für eine Liste deiner 404-Fehler mit zusätzlichen Informationen über die Sitemaps, in denen die falschen URLs enthalten sind, und die Seiten, von denen sie verlinkt werden, bereits vorausgefüllt:
https://developers.google.com/apis-explorer/#p/webmasters/v3/webmasters.urlcrawlerrorssamples.list
Du musst nur die URL deiner Website eingeben (achte darauf, dass du die genaue URL deines GSC-Grundstücks im richtigen Format verwendest). Du kannst die Ausgabe dann kopieren und einfügen und sie an deine IT weiterleiten. Ich möchte ein kleines Tool entwickeln, mit dem der Export einfacher und schöner wird, aber das wird noch eine Weile dauern 🙂 .
Ich hoffe, das hilft dir erst einmal! Lass es mich wissen, wenn du noch Fragen hast.
Eoghan,
Das funktioniert perfekt. Vielen Dank für die ausführliche Antwort und die angepasste URL. Ich hoffe, ich kann mich eines Tages revanchieren 🙂 .
Nochmals vielen Dank,
Chris
Es gibt eine böse Website, die eine Weiterleitung auf unsere Seite eingeschleust hat. Wir haben die Schadsoftware gefunden und entfernt, aber ihre Seite verlinkt immer noch zu vielen URLs auf unserer Seite, die nicht existieren, und verursacht dadurch Crawler-Fehler.
Was schlägst du vor, wie wir das lösen können?
DANKE!
Jennifer
Hallo Jennifer,
Das klingt wirklich fies :/
Es ist nicht einfach, diese Situation mit den wenigen Informationen, die ich habe, zu analysieren, aber ich denke, dass du dir über die Crawl-Fehler keine allzu großen Sorgen machen musst. Sieh es doch mal so: Jemand (ein Spammer) schickt den Googlebot zu URLs auf deiner Website, die es nicht gibt und nie gegeben hat. Google ist schlau genug, um herauszufinden, dass das nicht deine Schuld ist.
Wenn du magst, kannst du mir weitere Informationen per E-Mail schicken, damit ich sie mir genauer ansehen kann.
Ich erhalte einen HTTP-Fehler: 302-Fehler im Bereich Sitemaps. Alle anderen Sitemap-URLs funktionieren einwandfrei, aber ich erhalte einen Fehler in der Hauptsitemap.xml. Wie kann ich das Problem beheben?
Hallo Ajay,
vielen Dank für deinen Kommentar. Ich bin mir nicht sicher, ob ich deine Frage richtig verstanden habe. Ich schicke dir eine E-Mail, damit du mir einen Screenshot schicken kannst, wenn du möchtest.
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan, ich würde gerne wissen, ob du das ‘302’-Problem gelöst hast
Ich habe das Problem, dass ich durch die Wayback Machine auf eine Website gelange, aber wenn ich dann auf den gewünschten Link klicke, werde ich mit der Meldung begrüßt: ‘Got an HTTP 302 response at crawl time’ und werde auf die aktuelle Website umgeleitet, auf der meine Informationen nicht mehr vorhanden sind.
Ich wäre dir sehr dankbar, wenn du mir eine E-Mail schicken könntest.
internetuser52@gmail.com
Hallo Ray,
Ich schicke dir eine E-Mail.
Eoghan
Ich habe das gleiche Problem (HTTP-Fehler 302). Kannst du mir auch eine E-Mail schicken?.
Danke!,
Drake
Hallo Drake,
Ja, ich schicke dir eine E-Mail 🙂 .
Bitte hilf mir, diesen Fehler zu beheben.
Screenshot: http://i.imgur.com/ydZo4Wv.jpg
Ich habe die Beispielseite gelöscht und die zweite Url umgeleitet.
Hallo Saud,
Leider funktioniert die Screenshot-URL nicht (mehr). Ich werde mich per E-Mail mit dir in Verbindung setzen und sehen, ob ich dir helfen kann.
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan Henn,
Das ist Kevin, kannst du mir sagen, wie viele Tage nach dem Entfernen der Seite von den Webmastern die Seite entfernt werden kann.
Hallo Kevin,
Vielen Dank für deinen Kommentar. Ich bin mir nicht sicher, ob ich deine Frage richtig verstanden habe. Ich werde dir eine E-Mail schicken, damit wir das besprechen können.
Mit freundlichen Grüßen,
Eoghan
Henn,
Wir haben Crawl-Fehler in den Webmastern. Wenn wir solche Seiten aus den Webmastern entfernen, wie viele Tage dauert es dann, bis die Seite aus den Google Webmastern entfernt werden kann?.
Hallo Kevin,
Für mich gibt es zwei Szenarien, in denen ich einen Crawl-Fehler aus dem Bericht entfernen würde:
1. Wenn ich weiß, dass der Fehler nicht wieder auftreten wird, weil ich ihn entweder behoben habe oder weiß, dass es eine einmalige Sache war.
2. Wenn ich nicht weiß, warum der Fehler aufgetreten ist (d.h. warum Google diese URL gecrawlt hat oder warum die URL einen Fehlercode zurückgegeben hat) und ich sehen möchte, ob er wieder auftritt.
WANN du das tust, ist wirklich nicht so wichtig. Ich hoffe, das hilft dir! Lass es mich wissen, wenn du weitere Fragen hast.
Wie kann ich diesen Fehler 500 beheben? http://imgur.com/a/qE4i3
Hallo Michael,
Du kannst dein Verzeichnis /wp-includes/ für den Google-Bot sperren, indem du es in deine robots.txt-Datei aufnimmst. Ich empfehle dir, das Yoast SEO Plugin für WordPress zu installieren. Soweit ich weiß, macht es das automatisch.
Ich hoffe, das hilft.
Eoghan
In meiner Antwort auf Donalds Kommentar (oben) findest du ein Update zu diesem Thema.
Ich habe das gleiche Problem wie Michael. .
Wie kann ich diesen Fehler 500 beheben? http://imgur.com/a/qE4i3
Dadurch habe ich jedes einzelne Keyword verloren, für das ich gerankt habe, und je mehr ich versuche, sie zu entfernen, desto mehr tauchen sie wieder auf. Sobald ich die URL abrufe, steigen die Suchergebnisse für viele Keywords wieder auf #2-Positionen, aber nach ein paar Stunden sieht es so aus, als ob Google sie erneut crawlt, Fehler findet und die Seite auf die 10. Sobald der 500-Server-Fehler auf Webmaster entdeckt wurde, gingen die Suchergebnisse nach und nach verloren.
Jetzt habe ich darüber nachgedacht, /wp-includes/ zu blockieren, aber ich glaube, dass man es aufgrund von css und js nicht mehr blockieren kann, was dem Ranking noch mehr schaden könnte.
Für jede Hilfe wären wir dankbar.
Hallo Donald,
Du hast völlig recht, /wp-includes/ enthält einige .js-Dateien, die Google crawlen soll. Dein CSS befindet sich aber normalerweise in /wp-content/.
Außerdem wird /wp-includes/ von Yoast nicht mehr standardmäßig blockiert (Quelle: https://yoast.com/wordpress-robots-txt-example/)
Trotzdem ist es wahrscheinlich eine gute Idee, alle URLs zu blockieren, die vom Google-Bot einen 500-Fehler zurückgeben. Bisher hatte ich noch nie Probleme damit, das gesamte Verzeichnis /wp-includes/ zu blockieren (auf dieser Website tue ich das immer noch), aber es könnte sich lohnen, das Verzeichnis durchzugehen und nur URLs zu blockieren, die einen 500er Serverfehler zurückgeben.
Ich hoffe, das hilft!
Ich erhalte viele Fehlermeldungen, dass die Seite nicht gefunden wurde, und wenn ich die Links von der Info überprüfe und auf die Links klicke, gehen sie eindeutig auf die eigentliche Seite, die nicht kaputt ist? Das ist wirklich ärgerlich, weil die Fehler immer wieder auftauchen.
d.h.
Dieser Fehler
/Orte/white-horse-inn/
ist hier verlinkt
http://www.seanthecyclist.co.uk/places/white-horse-inn/
Hast du eine Idee, was die Ursache dafür sein könnte?
Danke
Hallo Sean,
Ich glaube, ich brauche noch ein paar mehr Informationen, um dir helfen zu können. Ich werde dir jetzt eine E-Mail schicken.
Mit freundlichen Grüßen,
Eoghan
Hallo Herr!
Ich habe gerade eine Website erstellt und Google kann sie nicht crawlen und erlaubt mir auch nicht, eine Sitemap hochzuladen. Es werden nur 2 Links angezeigt, wenn ich site:acousticimagery.net eingebe, und einer davon zeigt einen 500-Fehler an. Außerdem mag Google meine robots.txt-Datei nicht, wenn ich versuche, sie zu crawlen. Ich habe versucht, sie zu ändern oder ganz zu entfernen, aber nichts hilft. Mein Website-Host ist wertlos und ich versuche schon seit 2 Wochen, das Problem zu lösen. Für jeden Hinweis wäre ich dankbar!
Hallo Mick! Vielen Dank für deinen Kommentar.
Ein wichtiges Problem, das ich feststellen konnte, ist, dass dein Server immer einen 500-Fehler statt eines 404-Fehlers zurückgibt, wenn eine Seite nicht existiert. Fällt dir eine Möglichkeit ein, das zu beheben?
Wenn du deine Seiten schnell in den Index bringen willst, empfehle ich dir, in der Google Search Console auf “Crawl > Als Google holen” zu gehen. Hier kannst du jede Seite abrufen, die noch nicht im Index ist, und dann, nachdem sie abgerufen wurde, auf “An den Index übermitteln” klicken. Dadurch wird der Indexierungsprozess beschleunigt.
Ich konnte weder eine robots.txt-Datei noch eine XML-Sitemap auf deinem Server finden. Die robots.txt sollte sich befinden unter http://acousticimagery.net/robots.txt. Im Moment gibt diese URL einen 500er Fehlercode zurück, also nehme ich an, dass die Datei nicht existiert oder sich nicht an diesem Ort befindet. Du kannst entscheiden, wie du deine XM-Sitemap nennen willst, aber ich würde empfehlen, sie hier abzulegen: http://acousticimagery.net/sitemap.xml.
Allerdings brauchst du für eine Website mit nur 4 Seiten nicht unbedingt eine robots.txt-Datei und eine XML-Sitemap (schaden können sie aber auch nicht). Achte nur darauf, dass du das Ding mit den falschen Fehlercodes änderst.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan,
Danke für die Antwort! Google lässt mich die Seite nicht crawlen, da ich immer wieder die Fehlermeldung erhalte, dass die robots.txt-Datei nicht gefunden werden kann. Ich habe den Inhalt der Datei entfernt und es erneut versucht, aber es geht immer noch nicht. Außerdem bekomme ich jedes Mal, wenn ich versuche, eine XML-Datei hochzuladen, die Meldung, dass die Datei ein ungültiges Format hat. Ich sehe die 500 Fehler, kann sie aber nicht beheben. Irgendwelche anderen Ideen? Das alles begann, als ich die Website mit einem Website-Builder von Fat Cow aktualisiert habe. Es tut mir sehr leid, dass ich überhaupt versucht habe, die Seite zu aktualisieren, denn ich erhalte keinerlei Unterstützung von ihnen. Ich überlege, ob ich die Website einfach zurückziehen und mein Fat Cow-Konto kündigen soll. Du hast erwähnt, dass du jede Seite mit Fetch übermittelst. Wie machst du das?
Hallo Mick,
OK, danke für die zusätzlichen Informationen. Jetzt verstehe ich besser, was los ist. Der Google-Bot versucht, auf deine robots.txt-Datei unter http://acousticimagery.net/robots.txt und erhält einen 500er Serverfehler, also beschließt er, die Seite nicht zu crawlen und später wiederzukommen. Du kannst das Problem beheben, indem du den Fehlercode behebst, den ich zuvor beschrieben habe. Wenn http://acousticimagery.net/robots.txt einen 404-Fehler zurückgibt, ist alles in Ordnung und Google crawlt deine Seite.
Ich weiß nicht, wie das bei Fat Cow funktioniert, aber vielleicht hilft dir diese Seite weiter: http://www.fatcow.com/knowledgebase/beta/article.bml?ArticleID=620
Hier erfährst du, wie du jede Seite in der Google Search Console an den Google-Index übermitteln kannst:
1. Gehe in der linken Navigation auf Crawl > Fetch as Google:
2. Gib den Pfad der Seite ein, die du übermitteln möchtest, und klicke auf "Abrufen":
3. Wenn der Abruf abgeschlossen ist, klicke auf “Indizierung anfordern”:
4. Vervollständige den Dialog, der sich wie folgt öffnet:
5. Wiederhole diesen Vorgang für jede Seite, die du in den Index aufnehmen willst. Hier sind die Pfade der Seiten, die du übermitteln willst:
cd-übertragungen
Audio-Aufnahme
Kontakt-uns
Ich hoffe, das hilft! Es wird eine Weile dauern, bis die Seiten in den Suchergebnissen auftauchen. Lass mich wissen, wenn ich noch etwas für dich tun kann.
Eoghan
Hallo Herr
(ich habe schlechtes Englisch)
Kannst du mir helfen, dieses Problem zu lösen?
Meine Seite wurde wegen des Yandex-Bots gesperrt (ich verstehe nicht wirklich, wie das funktioniert).
http://imgur.com/a/W1JKK
Ich habe meine Website bei Yandex registriert, konnte aber die Crawl-Einstellung nicht finden.
http://imgur.com/a/297Mu
Was soll ich tun?
Hallo und danke, dass du diesen interessanten Fall mit uns teilst. Ich will versuchen, dir zu helfen, obwohl ich noch nie von einem solchen Fall gehört habe.
Yandex hat im FAQ-Bereich eine Frage zu genau diesem Problem: https://yandex.com/support/webmaster/robot-workings/robot-workings-faq.xml#server-overload
Die Crawl-Delay-Direktive in der robots.txt-Datei (die Google im Übrigen ignoriert) sollte dabei helfen: https://yandex.com/support/webmaster/controlling-robot/robots-txt.xml#crawl-delay
Ich glaube, dass es hier noch ein paar wichtigere Dinge zu beachten gibt:
1. Wenn dein Server oder dein Hosting-Anbieter das normale Crawling durch Suchmaschinen nicht bewältigen kann, brauchst du einen anderen Server oder Hosting-Anbieter.
2. Ein Bot, der deine Seite crawlt und behauptet, er sei der Yandex-Bot, könnte ein “böser Bot” sein, der den Yandex-Bot imitiert. Diese bösen Bots ignorieren einfach deine robots.txt-Datei und crawlen deine Seite weiter. Hier ist eine weitere Frage in den FAQs von Yandex zu genau diesem Problem: https://yandex.com/support/webmaster/robot-workings/robot-workings-faq.xml#checking-yandex-robots
Das ist alles, was mir im Moment einfällt. Ich hoffe, es hilft dir und lass mich bitte wissen, wie es läuft und ob du weitere Fragen hast.
Hallo mirotic,
Benutzt du eine Wordpress-Plattform? Wenn ja, dann überprüfe, ob du das SEO Search Term Tagging 2 Plugin verwendest...Wenn ja, dann deaktiviere das Plugin einfach...die letzten Updates haben Bugs...und zeigen solche Fehler an....Ich hatte eine ähnliche Situation auf meiner Seite....Das Deaktivieren des Plugins hat mein Problem gelöst...probiere das aus.
Hey Eoghan,
Danke fürs Teilen. Für eine E-Commerce-Website schlägt mein Freund einen Weg vor, wie man mit 400 Seiten umgehen kann.
1. Lade die Suche crawl error-404 herunter,
2. Füge die 404-URL in eine txt-Datei ein,
3. Lege die 404.txt im ftp ab,
4.404.txt an Sitemap hinzufügen/testen senden
google webmaster-crawl-sitemap-Schaltfläche zum Hinzufügen/Testen der Sitemap
http://www.xxxxx.com/404.txt
Da wir in letzter Zeit rund 4k Url löschen werden, ist es sehr wichtig, wie wir damit umgehen.
Behebe 404-Fehler, indem du falsche URLs umleitest oder deine internen Links und Sitemap-Einträge änderst.
für diese, Schritte wie folgt, richtig?
1. 301-Umleitung aller 404-Fehler-Url auf die Homepage,
2. die Sitemap aktualisieren
3. Fasse die Sitemap zusammen,
Welche ist richtig?
Ja, genau so würde ich es vorschlagen. Überlege dir nur, ob es bessere Ziele für deine 301-Weiterleitungen gibt als die Startseite. Ich würde nicht empfehlen, einfach jede alte URL auf die Startseite umzuleiten, ohne darüber nachzudenken. Für die meisten URLs gibt es wahrscheinlich bessere Ziele als die Startseite.
Hallo Leanin,
Ich weiß nicht, warum dein Freund diese Schritte empfiehlt, aber von dieser Lösung habe ich noch nie gehört.
Hallo Herr, dies ist meine Website, bitte helfen Sie mir, dass meine Suchkonsole analytisch nicht funktioniert, was das Problem ist. http://www.subkuchsell.com Website
Hallo Ali,
Ich bin mir nicht sicher, ob ich dir bei dieser Frage helfen kann. Wenn du keine Daten in der Google Search Console siehst, kann es daran liegen, dass du dein Grundstück erst kürzlich verifiziert hast. Es dauert ein paar Tage, bis die Daten angezeigt werden.
Wenn du keine Fehler siehst, kann das auch damit zusammenhängen, dass es einfach keine Fehler gibt.
Stelle sicher, dass du die richtige Website-Version überprüfst. Die URL, die du für deine Search Console-Eigenschaft eingibst, sollte lauten http://www.subkuchsell.com/.
Lass mich wissen, wenn ich noch etwas für dich tun kann.
Eoghan
Ich habe gerade eine E-Mail-Benachrichtigung von GSC über einen starken Anstieg von Soft-404-Fehlern erhalten. Es hat sich herausgestellt, dass Spammer von .cn-Domains auf Suchanfragen in meinem WordPress-Blog verlinken, die in einer anderen Sprache (vermutlich Chinesisch) gestellt werden, und die Zahlen sind seit dem 5. Januar, als es anfing, jeden Tag fast linear gestiegen. Ich nehme an, ich könnte Suchlinks von .cn-Domains blockieren, aber hast du eine bessere Idee?
Hallo Jacob,
Zunächst einmal: Entschuldige meine späte Antwort. Ich habe es in den letzten Tagen nicht geschafft, mit all den Kommentaren Schritt zu halten.
Vielen Dank, dass du diesen interessanten Fall teilst, auch wenn er für dich sehr ärgerlich ist. Hast du schon alle deine Suchergebnisseiten auf “noindex” gesetzt? Das sollte ohnehin jede Website tun, um eine unkontrollierte Indexierung der Suchergebnisseiten zu vermeiden. Du kannst das Yoast SEO Plugin verwenden, um dies einzurichten.
Das wird zwar nicht verhindern, dass die Seiten als weiche 404-Fehler angezeigt werden, aber zumindest lässt es Google wissen, dass du nicht willst, dass diese Seiten indexiert werden. Das sollte ausreichen, um sicherzustellen, dass diese Seiten dir nicht schaden.
Außerdem solltest du die Domains, die auf dich verlinken, daraufhin überprüfen, ob sie möglicherweise schädlich sind. Es könnte eine gute Idee sein, das Disavow-Tool zu verwenden, um diese Links auszuschließen. Bitte beachte jedoch, dass ich kein Experte für Linkentfernung und -bereinigung bin und dass du mehr recherchieren solltest, bevor du dich zu diesem Thema entscheidest.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Keine Sorge, das Leben ist beschäftigt, ich bin nur froh, dass du überhaupt geantwortet hast 🙂 .
Ja, meine Suchseiten werden über das AIOSEO WordPress Plugin nicht indiziert.
Ich habe versucht, mich zu einer Seite durchzuklicken. Es ist ein Blog mit einer Vielzahl von Links, die meist auf andere, ähnlich formatierte Müllseiten verweisen. Die Links zu meiner Seite sind verschwunden, und soweit ich das beurteilen kann, wird die Seite im Handumdrehen (oder regelmäßig) erneuert, wobei alte Links durch neue ersetzt werden, um so viele Seiten wie möglich zu spammen.
Es sieht so aus, als ob sie nur auf Besuche von neugierigen Webmastern wie dir aus sind, um damit Werbeeinnahmen zu generieren. Ähnlich wie diejenigen, die Google Analytics-Konten mit Empfehlungsspam.
Wird einer dieser Links im Bericht “Suchverkehr > Links zu deiner Website” in der Google Search Console angezeigt?
Die Links werden dir wahrscheinlich nicht schaden, wenn sie so schnell wieder verschwinden, aber ich denke, du solltest sie im Auge behalten. Was die Crawl-Fehler angeht... Wenn du sie als behoben markierst, werden sie wahrscheinlich nicht wieder auftauchen, wenn die Links verschwinden.
Ich hoffe, das hilft dir und ich hoffe, dass dich diese Spammer nicht länger belästigen werden.
Hallo Eoghan,
Ich habe das gleiche Problem, das ungefähr zum gleichen Zeitpunkt wie bei Jacob aufgetreten ist.
Ich habe über 200 “weiche 404-Fehler” von Such-URLs erhalten, die von einer wirklich seltsamen Suchergebnisseite auf meiner Website “verlinkt” sind, die nicht existiert.
Es gibt auch eine Menge sehr seltsamer Links von einigen wenigen .cn-Websites.
Ich hoffe, das macht Sinn, denn ich bin nicht vertraut mit Crawl-Fehlern. Für jede Hilfe oder Anleitung wäre ich sehr dankbar.
Danke!
Hallo Kevin,
Als Erstes würde ich dir empfehlen, die Crawl-Fehler in der Google Search Console als behoben zu markieren. Du findest diese Option im Crawl-Fehlerbericht direkt über der detaillierten Liste der Crawl-Fehler.
Wenn die Fehler danach nicht mehr auftauchen, musst du dir keine Sorgen mehr machen.
Wenn sie wieder auftauchen, musst du ein bisschen tiefer graben. Wenn du Unterstützung brauchst, kannst du dich gerne bei mir melden.
Mit freundlichen Grüßen,
Eoghan
Hallo zusammen,
Vor ein paar Tagen ist ein Großteil meiner Website aus den Google-Suchergebnissen verschwunden. Gleichzeitig hat google analytics einen starken Rückgang der organischen (Suchmaschinen-) Besucher registriert. Die Zahl der täglichen Besuche sank innerhalb von 3 Tagen von 300 auf 100. Bei der Überprüfung mit den Webmaster-Tools erhalte ich Hunderte von “404-not found”-Fehlern. Was mich aber wirklich beunruhigt, ist, dass diese URLs EXISTIEREN und sie funktionieren! Ich vermute, dass die dynamischen URL-Parameter daran schuld sind. Aber bis jetzt hat es gut funktioniert... Die Website ist in mehreren Sprachen verfasst und (da es sich um einen Eshop handelt) in mehreren Währungen angegeben. Diese Sprachen und Währungen werden durch $_GET-Parameter ausgewählt. Um zu verhindern, dass jemand versucht, die Seiten ohne die ausgewählte Sprache oder Währung aufzurufen, füllt die Website diese Parameter automatisch aus, falls sie nicht vorhanden sind. Beispiel:
http://www.eurocatsuits.com/index.php ..... verweist auf : http://eurocatsuits.com/index.php/?la=en¤cy=EUR
In “fetch as google” bekommt die index.php den Status “redirected” .... natürlich wird sie auf index.php/?la=en¤cy=EUR ...... umgeleitet, aber die “index.php/?la=en¤cy=EUR” bekommt den Status “not found” .... im Browser funktioniert die Seite jedoch einwandfrei ....
Irgendwelche Ideen? ... bitte hilf mir ... danke!
Tomas
Nach einer schlaflosen Nacht habe ich herausgefunden, dass die .htaccess schuld war...ich werde später eine neue erstellen, aber im Moment habe ich sie komplett gelöscht und alles funktioniert einwandfrei ....
Hallo Tomáš,
Ich bin froh, dass du es geschafft hast, das zu beheben.
Ein allgemeiner Tipp: Du solltest die Sprach- und Währungsparameter in deinen URLs loswerden. Sie sind nicht sehr suchmaschinen- (oder nutzer-) freundlich.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Hallo. Vor ein paar Tagen fing meine Website (ein Blog) an, so viele “Anrufe” von Googlebots zu erhalten. Als ich Google fragte, warum das passiert, antworteten sie, dass das normal sei und dass ich die Crawl-Frequenz in meinem Webmaster-Tool verringern sollte. Die große Frage für mich ist: Wie niedrig ist niedrig? Habt ihr einen Vorschlag? Danke!
Hallo Andrea,
Verursachen die Anfragen von Google irgendwelche Probleme mit deinem Server? Wenn nicht, würde ich dir nicht empfehlen, etwas zu ändern.
Wenn dein Server tatsächlich Probleme mit der Anzahl der Anfragen des Google-Bots hat, würde ich zunächst die folgenden Optionen in Betracht ziehen:
- Prüfe, ob dein Server performant genug ist. Normalerweise sollte es keine Probleme mit dem normalen Crawling durch Google und andere Bots geben.
- Überprüfe, ob die Anfragen tatsächlich von Google kommen oder von einem anderen Bot, der vorgibt, Google zu sein. Du kannst die Zahlen aus deinen Logdateien (oder wo auch immer du festgestellt hast, dass du viele Zugriffe vom Google-Bot erhältst) mit dem Crawl-Statistikbericht in der Google Search Console vergleichen (klicke in der linken Navigation auf Crawl > Crawl-Statistiken).
Alles in allem würde ich wirklich nicht empfehlen, die Crawling-Frequenz für den Google-Bot zu begrenzen.
Ich hoffe, das hilft dir! Lass es mich wissen, wenn du weitere Fragen hast.
Hallo zusammen! Danke für diesen Beitrag.
Ich bin mir nicht sicher, ob diese Frage schon gestellt worden ist.
Vor kurzem habe ich in den Webmaster Tools nach Crawl-Fehlern gesucht. Unter der Registerkarte "Smartphone" fiel mir auf, dass die meisten Fehler bei Seiten mit m/pagename.html oder mobile/pagename.html auftraten.
Wir haben diese Seiten ohne Unterverzeichnisse erstellt. Du wirst also nicht finden
http://www.victoriafalls-guide.net/mobile/art-from-zimbabwe.html oder
http://www.victoriafalls-guide.net/m/art-from-zimbabwe.html
Nur solche Seiten wie http://www.victoriafalls-guide.net/art-from-zimbabwe.html
Was übersehe ich hier?
Hallo Faniso,
Ich habe ein ähnliches Problem bei mehreren anderen Google Search Console-Eigenschaften gesehen. Manchmal ist es sehr schwierig zu verstehen, wo der Google-Bot die URLs ursprünglich gefunden hat.
Hast du die “verlinkt von”-Informationen in der Detailansicht der einzelnen Fehler-URLs überprüft? Das könnte dir helfen, die Quelle des Links zu finden, aber oft sind dort keine Informationen verfügbar.
Es gibt auch eine unbestätigte, aber ziemlich glaubwürdige Theorie, dass der Googlebot einfach die Verzeichnisse m/ und mobile/ überprüft, um zu sehen, ob es eine mobile Version einer Seite gibt, wenn sie nicht mobilfreundlich ist: https://productforums.google.com/forum/#!topic/webmasters/56CNFxZBFwE
Ich empfehle dir, die Fehler als behoben zu markieren und 301-Weiterleitungen von den nicht existierenden URLs zu den korrekten Versionen einzurichten, obwohl die Weiterleitungen wahrscheinlich gar nicht notwendig sind.
Ich hoffe, das hilft!
Hallo Eoghan
Ich habe ein ungelöstes Problem mit der ‘Link von’-Quelle, die Seiten sind, die seit bis zu 10 Jahren nicht mehr existieren.
Alle aktuellen Crawls, sowohl der Link als auch der ‘Link von’, sind asp Urls, die seit zehn Jahren nicht mehr existieren. In dieser Zeit ist die Website (mit derselben Root-Url) dreimal umgezogen und wurde mehrmals komplett neu aufgebaut (ohne CSS, Skripte usw.).
Ich kann mir vorstellen, dass externe Websites diese alten URLs in ihren Archiven aufbewahren, aber wie kommt Google auf diese Phantom-URLs, die schon seit so langer Zeit nicht mehr existieren? Hast du eine Idee zu diesem verwirrenden Problem? Danke!
Hallo Keith,
Ich habe genau das gleiche Problem mit mehreren verschiedenen Websites gehabt.
Hier ist meine Erklärung: Ich bin mir ziemlich sicher, dass die Information “verlinkt von” normalerweise nicht aktuell ist. Die Informationen, die hier angezeigt werden, stammen oft aus früheren Crawls und werden nicht jedes Mal aktualisiert, wenn die verlinkten Seiten gecrawlt werden. Das würde erklären, warum auch Jahre später noch Seiten als verlinkt von Seiten angezeigt werden, die nicht mehr existieren.
Außerdem habe ich festgestellt, dass diese Fehler oft nicht mehr auftauchen, nachdem du sie ein paar Mal als behoben markiert und sichergestellt hast, dass die Seiten wirklich nirgendwo mehr verlinkt sind. Diese Fehler schaden deiner SEO-Performance in der Regel nicht und sind daher kein Grund zur Sorge.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Eoghan
Vielen Dank dafür, Eoghan. Das beruhigt mich sehr, dass ich wenigstens nicht den Verstand verliere. Ich werde die Taktik des Festhaltens beibehalten.
Prost! Keith
Eoghan,
Ich habe das gleiche Problem und es ist erfrischend zu hören, was du sagst.
Ich bin jedoch besorgt über die Markierung von nicht fixierten Seiten als fixiert, denn ich habe diesen Hinweis in der offiziellen Wissensdatenbank von Google gefunden:
“Beachte, dass das Anklicken von Dieses Problem ist behoben im Crawl-Fehlerbericht den 404-Fehler nur vorübergehend ausblendet; der Fehler wird wieder erscheinen, wenn Google das nächste Mal versucht, diese URL zu crawlen. (Sobald Google eine URL erfolgreich gecrawlt hat, kann es immer wieder versuchen, diese URL zu crawlen. Eine 300-stufige Weiterleitung verzögert den erneuten Crawl-Versuch, möglicherweise für eine sehr lange Zeit.)”
Danke, dass du uns hilfst!
Hallo Alessandro,
Ich würde normalerweise nur empfehlen, einen nicht behobenen Fehler als behoben zu markieren, um zu prüfen, ob er wieder auftaucht. In jedem Fall würde ich empfehlen, die Fehlerseiten umzuleiten (was bedeuten würde, sie zu beheben). Oft sind diese Fehler ohnehin kein Grund zur Sorge und das Verhalten der Fehlerberichte in der Google Search Console macht nicht immer Sinn.
Ich hoffe, das hilft 🙂 .
Guten Tag,
Ich brauche Hilfe bei all meinen Crawl-Fehlern. Ich bezahle dich im Voraus, wenn du mir helfen kannst, alle meine Crawl-Fehler zu beseitigen.
Mit freundlichen Grüßen
Johan Watson
Hallo Johan,
Vielen Dank für deinen Kommentar. Ich werde dir kostenlos helfen, wenn du mir mehr Informationen gibst.
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan
Toller Artikel! Am oder um den 19. Februar 2017 kam es in unserem Webmaster-Konto zu einer Häufung von 500, 502 und 503 Fehlern (‘Serverfehler’), und unser Programmierer hat ein Problem mit der Datenbank gefunden und behoben. Dementsprechend haben wir alle 500/502/503-Fehler im Webmaster als behoben markiert. Kurz darauf fing Webmaster jedoch wieder an, Serverfehler zu erhalten (meist 502er, einige 500er) und die Anzahl der Fehler steigt täglich. Wir sind uns nicht sicher, warum wir immer noch die Server-Fehlermeldungen erhalten und wären dir dankbar, wenn du uns in dieser Hinsicht helfen könntest.
PS: Seitdem wir die Server-Fehlermeldungen erhalten, hat unser Traffic stark abgenommen und auch die Position in den Suchergebnissen.
Hallo Surojit,
Vielen Dank für deinen Kommentar. Wenn die Fehler immer wieder auftauchen, nachdem du sie als behoben markiert hast, sieht es so aus, als ob das Problem mit der Datenbank nicht die einzige Ursache für die Fehler war. Es gibt wahrscheinlich noch mehr Probleme, die du beheben musst.
Du kannst eine Liste aller Fehler über die Funktion Google Search Console API Explorer einschließlich Informationen darüber, woher die URLs, die die Fehler verursachen, verlinkt sind. Das könnte helfen, die Ursache des Problems zu finden.
Du kannst mir gerne mehr Informationen schicken, damit ich mir das genauer ansehen kann.
Mit freundlichen Grüßen,
Eoghan
Ich habe ein Problem und weiß nicht, was ich tun soll
Google zeigt einige Seiten meiner Website in der Suche als (https) an, aber ich habe kein https auf meiner Website
Ich will kein https, nur ein einfaches http
Bitte helfen Sie mir
Hallo Mido,
Vielen Dank für deinen Kommentar. Meine erste Idee war, vorzuschlagen, dass du alle https-URLs auf ihre http-Entsprechung umleitest, aber das würde wahrscheinlich immer noch Probleme für die meisten Nutzer verursachen, wenn du kein gültiges SSL-Zertifikat hast: Es würde eine Warnung angezeigt werden, bevor die Umleitung verarbeitet wird. Ich bin mir nicht sicher, wie der Google-Bot mit einer solchen Situation umgehen würde (ob er die Weiterleitungen verarbeitet oder nicht), aber ein fehlendes SSL-Zertifikat wird höchstwahrscheinlich Probleme in anderen Bereichen verursachen.
Ich denke, das Beste wäre, wenn du komplett auf https umstellst. Das ist etwas, was alle Webmaster sowieso tun sollten. Du kannst ein kostenloses SSL-Zertifikat von Let's Encrypt bekommen: https://letsencrypt.org/
Hier findest du eine gute Quelle, um sicherzustellen, dass du bei der Umstellung auf https aus SEO-Sicht alles richtig machst: http://www.aleydasolis.com/en/search-engine-optimization/http-https-migration-checklist-google-docs/
Bitte lass mich wissen, wenn du weitere Fragen hast.
Eoghan
Hallo Eoghan. Wunderbarer Artikel über Crawl-Fehler. Ich erhalte eine ganze Reihe von “no sentences found” News-Fehlern, aber wenn ich den Artikel im News-Tool teste, erhalte ich einen Erfolg. Wie kann man das beheben? Wenn ich einen Fetch und Render ausführe, wird auch nur die Bot-Ansicht angezeigt. Die Besucheransicht ist leer.
Hallo Nikkhil,
Vielen Dank für deinen Kommentar. Es tut mir sehr leid, aber ich habe nicht viel Erfahrung mit Google News. Soweit ich weiß, kann der Fehler “keine Sätze gefunden” durch eine ungewöhnliche Formatierung der Artikel ausgelöst werden - zu wenige oder zu viele Sätze pro Absatz.
Wenn Google Probleme beim Rendern deiner Seite hat, könnte es andere technische Probleme geben. Das solltest du auf jeden Fall überprüfen. Tritt das Problem bei allen Artikeln auf oder nur bei denen, die auch den Fehler “keine Sätze gefunden” haben?
Es tut mir leid, dass ich dir keine bessere Antwort geben kann. Lass mich wissen, wenn du weitere Fragen hast.
Eoghan
Hallo Eoghan,
Vielen Dank für die Antwort. Unsere Website ist auf einem MEAN-Stack aufgebaut. Wir verwenden Pre-Render IO, damit der Google-Bot sie crawlen kann, da die Seite in Angular js aufgebaut ist. Es gibt etwa 600 Artikel in der Fehlerliste, bei denen keine Sätze gefunden wurden. Alle von ihnen haben Inhalt! z.B. http://www.spotboye.com/television/television-news/after-sunil-grover-is-navjot-sidhu-the-next-to-quit-kapil-sharma-s-show/58d11aa18720780166958dc3
Hallo Nikkhil,
Der Google Cache für das von dir angegebene Beispiel sieht gut aus. Ich bin mir nicht sicher, ob Prerendering immer noch der bevorzugte Weg ist, um mit Angular JS-Websites umzugehen, denn Google kann JavaScript inzwischen viel besser rendern. Außerdem weiß ich nicht, ob der Google News-Bot JS anders behandelt (obwohl er das nicht tun sollte). Die Tatsache, dass die Besucheransicht im Fetch- und Renderbericht nicht funktioniert, solltest du wahrscheinlich genauer untersuchen.
Es tut mir leid, dass ich dir keine konkreten Antworten geben kann, aber vielleicht hilft dir das bei deinen weiteren Nachforschungen. Lass es mich wissen, wenn du weitere Fragen hast!
Eoghan
Hallo Eoghan,
Meine Website gibt den Fehler 500 (interner Serverfehler) aus, wenn ich von einem Google-Suchergebnis aus darauf klicke. Wenn ich bei Google nach "autismherbs" suche und auf einen der Links zu meiner Website klicke, erhalte ich die Fehlermeldung 500 (interner Serverfehler). Wenn ich aber auf die Adressleiste klicke und die Eingabetaste drücke oder auf einer anderen Website auf einen Link zu autismherbs.com klicke, funktioniert es einwandfrei.
Ich habe das Fehlerprotokoll überprüft und es zeigt:
[core:debug] [pid 992574] core.c(3755): AH00122: Umgeleitet von r->uri = /index.php, referer: https://www.google.com/
Ich habe versucht, die .htaccess-Datei zu löschen, aber das Problem tritt immer noch auf.
Gibt es eine Lösung für dieses Problem? Welche Codes sollte ich überprüfen?
Hallo Anne,
Zunächst einmal: Entschuldige meine späte Antwort. Ich hatte Schwierigkeiten, mit den Kommentaren hier Schritt zu halten.
Ich habe deine Website überprüft und das ist in der Tat ein sehr seltsames Verhalten. Es scheint, dass deine Seiten 500 Fehlercodes für den Googlebot und für Besucher, die auf ein Google-Suchergebnis klicken, zurückgeben. Für andere User Agents und Referrer funktionieren die gleichen URLs einwandfrei.
Ich habe einige Zeit damit verbracht, herauszufinden, warum sich deine Website so verhält, aber ich habe noch keine gute Idee. Kannst du bei deinem Hoster/Entwickler nachfragen, ob es eine Einstellung gibt, die unterschiedliche Antwortcodes für verschiedene User Agents oder Referrer festlegt?
Bitte lass mich wissen, wenn du weitere Fragen hast.
Hallo Eoghan,
Ich habe vor kurzem einen Teil unserer Website mit einem Administrator-Login umgestaltet (wir haben nur relativ begrenzten Zugang).
Im Rahmen der Neugestaltung habe ich einige Seiten entfernt und ersetzt sowie eine Reihe von URLs geändert.
Wenn ich vor dem Löschen keine 301-Weiterleitung eingegeben habe, ist es dann trotzdem möglich, dies zu tun? Ist es möglich, dies über den HTML-Quelltext oder ähnliches zu tun, da wir meines Wissens keinen Zugriff auf versteckte Dateien haben.
Mit freundlichen Grüßen
Harry
Hallo Harry,
Entschuldigung für meine späte Antwort! Ja, du kannst (und solltest) immer noch 301-Weiterleitungen einrichten, obwohl es am besten gewesen wäre, sie sofort nach der Änderung der URLs einzurichten.
Es gibt verschiedene Möglichkeiten, 301-Weiterleitungen zu implementieren, und deine Wahl hängt von deinen technischen Gegebenheiten ab. Hier ist eine Übersicht, die ich sehr nützlich finde: http://www.webconfs.com/154/301-redirects-how-to-redirect-your-website/
Lass es mich wissen, wenn du weitere Fragen hast!
Hallo Eoghan Henn,
Eine Seite in den Sitemaps ist bereits indexiert. Aber jetzt habe ich das gefunden
HTTP-Fehler: 403 “Als wir eine Stichprobe der URLs aus deiner Sitemap getestet haben, haben wir festgestellt, dass einige URLs aufgrund eines HTTP-Statusfehlers für Googlebot nicht erreichbar waren. Alle erreichbaren URLs werden trotzdem übermittelt.” für diese Seite.
Könnten Sie uns bitte beraten? Ich danke dir.
Hallo Annie,
Im Falle eines solchen Fehlers empfehle ich, alle URLs in deiner Sitemap mit einem Tool wie Screaming Frog zu crawlen. Wenn einige der URLs Fehler zurückgeben, solltest du prüfen, ob sie aus der Sitemap entfernt werden sollten (weil sie dort nicht hingehören) oder ob die Seiten repariert werden müssen (weil sie funktionieren sollten, es aber nicht tun). Wenn es keine Fehler gibt, kannst du die Sitemap erneut in der Google Search Console einreichen und den Fehlerbericht überprüfen. Manchmal ist diese Art von Fehler nur vorübergehend.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Danke Rebell
Ich habe versucht, die Daten wie Google abzurufen, aber es erscheint “Fehler” statt wie üblich “vollständig”. Ich weiß nicht, was ich als Nächstes tun soll. Ich habe versucht, Scream Frog auf meinem PC zu installieren, aber es lässt sich nicht starten. Heute verschwindet diese Seite, wenn ich nach dem Keyword Rank von dieser Seite suche (vorher auf Seite 2, jetzt kann ich sie nicht mehr unter den Top 200 sehen).
Könnten Sie bitte helfen
Vielen Dank!.
Hallo Annie,
Kannst du mir sagen, von welcher Seite wir sprechen? Ich kann nachsehen, ob ich das Problem identifizieren kann.
Mit freundlichen Grüßen,
Eoghan
Ich freue mich, den 100. Kommentar für diese sehr hilfreiche Seite zu schreiben!
Ich habe versucht, alle 99 vorangegangenen Kommentare durchzublättern und vielleicht habe ich es übersehen, aber was ist mit URLs mit nicht gefundenen Fehlern, die KEINEN Link von Tab haben? Was bedeutet das? Woher kommen sie? Eine Sitemap xml?
Hallo Alessandro! Danke, dass du den 100. Kommentar geschrieben hast 🙂 Wenn eine URL in einer XML-Sitemap enthalten ist, werden diese Informationen auch in einem Reiter neben dem Reiter “verlinkt von” angezeigt. Wenn es keinen Reiter “verlinkt von” gibt, bedeutet das einfach, dass es keine Informationen über die Quelle des Links gibt. Das passiert oft bei sehr alten URLs, die immer wieder neu gecrawlt werden. Manchmal erfindet Google auch selbst URLs, wie z. B. m.domain.com oder domain.com/mobile (nur um zu prüfen, ob es eine mobile Version gibt). Diese haben auch keinen Reiter “verlinkt von”.
Hi,
Vielen Dank für deinen Artikel. Wir sind eine Website mit Stellenangeboten. Die Stellenangebote auf unserer Website laufen nach einiger Zeit ab, so dass der Roboter viele “nicht gefundene” Seiten findet, weil sie natürlich ablaufen. Wie sollten wir in unserem Fall damit umgehen?
Hallo Vadim,
Vielen Dank für deinen Kommentar. Wenn du eine Seite absichtlich von deiner Website löschst, ist es am besten, einen 410-Statuscode anstelle von 404 zu liefern. Der Unterschied ist, dass 410 tatsächlich “Inhalt gelöscht” bedeutet, während 404 nur “Inhalt nicht gefunden” bedeutet. Wichtige Randnotiz: Seiten, die einen 410-Statuscode liefern, erscheinen derzeit noch als 404-Fehler in der Google Search Console. Lass dich davon nicht irritieren.
Was die Benutzerfreundlichkeit angeht, solltest du dir überlegen, was du auf der Fehlerseite für abgelaufene Stellenangebote anzeigen willst. Ich denke, es wäre interessanter, eine Meldung darüber anzuzeigen, dass die Stelle abgelaufen ist (einschließlich einer Handlungsaufforderung für die weitere Navigation auf deiner Website), als eine Standardmeldung “Seite nicht gefunden”.
Hier ist ein guter Artikel über deine Möglichkeiten, wenn du Seiten von deiner Website entfernst (der allerletzte Teil über Kollateralschäden ist WordPress-spezifisch, du kannst ihn also ignorieren): https://yoast.com/deleting-pages-from-your-site/
Ich hoffe, das hilft dir! Lass es mich wissen, wenn du weitere Fragen hast.
Hallo Eoghan,
sehr hilfreiche und vollständige Informationen. Vielen Dank dafür!
Hallo Eoghan Henn,
Sehr hilfreiche Informationen, mach weiter so.
Ich erhalte in meiner Suchkonsole Fehler, die auf meiner Website und meinem Server nicht existieren. Eigentlich gab es diese Url-Muster schon vor mehr als einem Jahr. Ich habe meinem Entwickler mehrmals gesagt, er solle meinen Server überprüfen, aber er sagte, die Fehler seien nicht mehr da. Ich habe sie mehrmals als behoben markiert, aber die Fehler tauchen immer wieder auf. Da die Plattform der Website auf PHP umgestellt wurde, zeigt die Google Search Console auch .aspx-Fehler an.
Bitte gib mir einen Vorschlag, wie ich diese Fehler beheben kann.
Danke im Voraus...
Hallo Raja,
Vielen Dank für deinen Kommentar. Hast du versucht, den http-Statuscode zu ändern, den diese alten URLs zurückgeben? Die beste Option wäre wahrscheinlich eine 301-Weiterleitung zu ähnlichen Zielen. Wenn das nicht möglich ist, kannst du den 404-Statuscode in einen 410-Statuscode ändern. Das kann dazu beitragen, dass die alten URLs schneller aus dem Index entfernt werden.
Das Markieren von Fehlern als behoben hat keinen Einfluss auf das Crawling von Google. Es ist lediglich ein nützliches Werkzeug, um deine Fehlerberichte besser zu strukturieren.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Hi,
Meine bIog-Website ist in WordPress. Ich erhalte 404 für die Links. Diese kommen alle, wenn ich meine Beiträge in Facebook/Twitter veröffentliche und der Crawler zeigt facebook/twitter.com am Ende an.
Meine Website-Karte sieht sauber aus.
Kannst du mir bitte vorschlagen, wie ich das Problem beheben kann?
Danke!,
Sup
Hallo Sup,
Kannst du mir ein Beispiel für eine URL mit einem 400-Fehler schicken (per Mail, wenn du magst)? Verwendest du eine Art Plugin, um deine Blogbeiträge auf Facebook und Twitter zu teilen?
Ich helfe dir gerne, aber ich brauche noch ein paar Informationen.
Ja! Meiner macht das auch. Ich glaube nicht, dass es irgendetwas schadet, aber es ist sehr ärgerlich und schwer zu entkrauten, um tatsächliche Fehler zu sehen. Sie sind für ALLE sozialen Medien (Facebook, Pinterest, Twitter und Instagram)
Das sind nur ein paar davon (ich habe im Moment 100+). Sie sind alle 404.
tag/münchen/www.facebook.com/AliciaYarrishPhotography
tag/engagement-session-tips/www.facebook.com/AliciaYarrishPhotography
tag/engagement-session-tips/www.pinterest.com/alicia_yarrish
tag/powersheets/www.instagram.com/aliciayarrish
tag/powersheets/www.pinterest.com/alicia_yarrish
tag/powersheets/www.facebook.com/AliciaYarrishPhotography404
destination-film-photography/www.facebook.com/AliciaYarrishPhotography
destination-film-photography/www.pinterest.com/alicia_yarrish
tag/münchen/www.instagram.com/aliciayarrish
tag/münchen/www.pinterest.com/alicia_yarrish
Hallo Alicia,
Ich habe einen kurzen Blick auf deine Seite geworfen und das ist ein ziemlich seltsamer Fall. Ich denke, dein Problem könnte damit zusammenhängen, dass einige der Social Media Icon Links auf deiner Seite kein “https://” am Anfang haben. Normalerweise sollte der Google-Crawler diese Links als absolute Links erkennen, aber hier sieht es aus irgendeinem Grund so aus, als würde er sie als interne, relative Links interpretieren.
Um dies zu beheben, empfehle ich dir, alle Links, die auf deine Social Media Profile verweisen, mit “https://” zu versehen.
Bitte lass mich wissen, ob das bei dir funktioniert!
Hallo Eoghan,
Ich muss sagen, dass deine Kommentare und Beiträge auf Rebi,ytics.com sehr interessant und informativ sind - ich habe viel gelernt! Unnötig zu sagen, dass ich deine Seite jetzt mit einem Lesezeichen versehen habe.
Die Person, die in den letzten 7 oder 8 Jahren mein SEO-Berater war, stellt ihre Dienste zum Ende dieses Jahres (2017) ein.
Deshalb suche ich eine Person, die die Fähigkeit hat,..:
Schreibe überzeugende Inhalte mit Schlüsselwörtern und Phrasen, die sinnvoll sind, um meine Kategorieseiten zu optimieren.
Überwache die Crawl-Fehler der Sitemap und behebe sie rechtzeitig.
Halte dich mit Google auf dem Laufenden und nimm die notwendigen Änderungen im Backoffice der Website vor, um sie für eine optimale Leistung auf dem neuesten Stand zu halten.
Schlage proaktiv zusätzliche Ideen für das Branding, das Design und die Navigation der Website vor, um die Kaufbereitschaft und Loyalität der Kunden zu erhöhen.
Steigere den Kundenverkehr und die Trefferquote im Verkauf.
Wenn du oder einer deiner Kommentatoren eine solche Person kennt, lass es mich bitte wissen,
Dirt E. Harry
Hi Dirt E. Harry,
Vielen Dank für deinen Kommentar. Ich freue mich, dass meine Artikel hilfreich waren. Im Moment kenne ich niemanden, der für SEO-Projekte zur Verfügung steht, aber ich hinterlasse diesen Kommentar einfach hier, damit ihn jeder sehen kann. Viel Glück bei deiner Suche! Und lass mich einfach wissen, wenn du weitere Fragen hast.
Hallo Dirt E. Harry,
Ich betreibe eine Website-Agentur, deren Schwerpunkt auf SEO, Website-Design und Entwicklung liegt. Wir sind von Google SEO-zertifiziert, was bedeutet, dass wir alle Prüfungen für Google Analytics und Google AdWords mit einer Punktzahl von über 80% bestanden haben.
Es tut uns leid zu hören, dass dein SEO-Berater sich entschieden hat, seine Dienste einzustellen, aber wir würden dir gerne weiterhelfen.
Besuche unsere Website und nimm Kontakt auf, um weitere Dinge zu besprechen - https://laceytechsolutions.co.uk
Ben Lacey
Geschäftsführerin
Ich werde das hier lassen, aber ich möchte klarstellen, dass Es gibt kein “von Google zertifiziertes SEO”.”. Das Bestehen der Prüfungen für Google Analytics und Google AdWords ist eine schöne Leistung, aber es beweist keinerlei SEO-Fähigkeiten. Außerdem zertifiziert Google keine SEO-Praktiker in irgendeiner Weise. Sei bitte sehr vorsichtig mit solchen Behauptungen.
Hallo Eoghan
Ich bin auf deinen Blog gestoßen und er ist sehr hilfreich.
Unsere Website wurde vor kurzem gehackt und unsere IT-Mitarbeiter versuchen seit 2 Monaten, das Problem zu beheben.
Ich würde wirklich gerne eine zweite Meinung dazu einholen, was wir tun müssen, um die Kriechfehler zu beseitigen.
Könntest du helfen?
Danke!
Hallo Charl,
Klar, stell deine Fragen einfach hier oder schick mir eine E-Mail. Ich werde dir gerne meine Meinung sagen.
Eoghan
Hallo Eoghan,
Ich habe gestern, am 5.5.17, ein neues Produkt zu meiner Website hinzugefügt, es zur Sitemap hinzugefügt und veröffentlicht. Heute, am 6.5.17, habe ich ein Video von U-Tube in dasselbe Produkt eingebettet. Muss ich das Produktdatum in der Sitemap aktualisieren und erneut veröffentlichen, weil der HTML-Code hinzugefügt wurde? Ich weiß, dass ich die Sitemap aktualisieren muss, wenn ich mehr als ein paar Wörter im Text oder Inhalt eines bestimmten Produkts ändere.
Dirt E. Harry
Nun, wenn du wirklich willst, dass alles in deiner XML-Sitemap 100% korrekt ist, sollte der “lastmod”-Wert wahrscheinlich genau das letzte Mal wiedergeben, als die Seite geändert wurde (egal wie klein die Änderung war). Wenn du den “lastmode”-Wert aber nicht auf dem neuesten Stand hältst, ist das kein Problem, denn Google und andere Suchmaschinen achten nicht wirklich darauf (was auch bedeutet, dass es dir nicht wirklich hilft, ihn auf dem neuesten Stand zu halten).
Hier sind einige Informationen darüber, wie Google damit umgeht: https://www.seroundtable.com/google-lastmod-xml-sitemap-20579.html
XML-Sitemaps helfen Google dabei, deine URLs zu entdecken. Ob und wie oft eine Seite nach ihrer Entdeckung gecrawlt und erneut gecrawlt wird, hängt jedoch von einer Reihe von Faktoren ab, und der “lastmod”-Wert ist wahrscheinlich einer der weniger wichtigen.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Danke Eoghan - das wird mir eine Menge Arbeit ersparen!
Hallo Eoghan 🙂 .
Kannst du mir bitte helfen, das herauszufinden?
Los geht's! Ich hatte vor Jahren eine HTML-Website. Ich hatte die Seite in der Google Webmaster (jetzt Search Console) eingetragen. Dann habe ich vor einigen Monaten alle Seiten von meiner Website entfernt und jetzt eine WordPress-Website installiert. Das neue XML, das ich der Search Console hinzugefügt habe, wird von JetPack (von WordPress) generiert. Und trotzdem bekomme ich immer noch 404 URL-Fehler der alten HTM- oder HTML-Dateien! Wie ist es möglich, dass das neu generierte XML, das nur WordPress-URL-Parameter erkennt, alte gelöschte HTM-Links entdeckt, die fast 4 Monate lang nie da waren?
Liegt es daran, dass Google selbst all diese Links noch speichert, oder liegt es an meiner XML-generierten Datei? Wie können wir alle fehlenden URLs endgültig aus Google löschen? Und wenn es 301 ist, kannst du mir bitte sagen, wie wir die *.htm und *.html auf neue Seiten der Website umleiten können?
Sorry für den langen Kommentar!
Danke!,
Hallo Shahab,
Deine alten Seiten werden wahrscheinlich immer noch gecrawlt, weil Google sie immer noch auf der Liste der URLs hat, die sie auf deiner Website entdeckt haben und für das Crawlen vorgesehen haben. Sie werden zwar nicht so oft gecrawlt wie die funktionierenden Seiten, aber ab und zu wird überprüft, ob sie immer noch eine Fehlermeldung liefern oder ob sie wieder verfügbar sind.
Um die Crawl-Fehler in deinen GSC-Berichten loszuwerden, solltest du tatsächlich alle alten URLs umleiten. Am einfachsten lässt sich das mit einem WordPress-Plugin wie diese (Ich habe es nie getestet, aber es sieht anständig aus). Wenn du mit der Bearbeitung deiner .htaccess-Datei vertraut bist, kannst du auch diese Option wählen. Das Yoast SEO Plugin hat einen praktischen .htaccess-Datei-Editor, aber du musst deine Rewrite-Regeln selbst schreiben (oder ein anderes Tool finden, das sie für dich erstellt).
Wenn du Versionen von URLs hast, die auf htm und html enden, kannst du jede davon separat hinzufügen und ein Weiterleitungsziel definieren, das Inhalte enthält, die dem Inhalt der alten Seite ähnlich sind.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Hallo nochmal,
Vielen Dank für deine ausführliche Antwort. Ich weiß es wirklich zu schätzen 🙂 .
“Sie werden sie nicht so oft crawlen wie die Seiten, die funktionieren, aber sie werden ab und zu überprüfen, ob sie immer noch einen Fehler zurückgeben oder ob sie wieder funktionieren.”
Wie lange würde es dauern, bis Google die kaputten Links löscht? Und wieso sind sie noch nicht gelöscht? Gibt es einen Zeitrahmen? Können wir Google nicht mitteilen, dass diese Seiten entfernt werden, oder sie persönlich aus dem GSC löschen?
Und wenn ich eine 301-Weiterleitung machen will, kann ich das für alle htm-Dateien tun? Ich habe nämlich keine genaue Liste der Links. Kann ich *.htm verwenden?
Und was würde passieren, wenn ich nichts tue? Schlecht für SEO?
Vielen Dank!,
Hallo Shahab,
Vielen Dank für deine interessanten Folgefragen.
Ich weiß nicht, wann und ob Google aufhört, URLs zu crawlen, die einen 404-Fehler zurückgeben. Wenn sie von irgendwoher verlinkt werden, werden sie definitiv immer wieder gecrawlt. Wenn nicht, sollte man erwarten, dass sie irgendwann aufhören, aber ich habe gesehen, dass alte URLs noch viele Jahre lang gecrawlt wurden, nachdem die Seiten nicht mehr existierten.
Ja, du kannst Google “mitteilen”, dass du die URLs absichtlich entfernt hast: Ein 410-Statuscode anstelle eines 404-Statuscodes würde das bewirken. Mit einem 410-Statuscode ist es wahrscheinlicher, dass Google die URLs nicht mehr crawlt, obwohl das nicht garantiert ist. Eine Sache, die verwirrend sein kann, ist, dass die Seiten immer noch als 404-Fehler in der Google Search Console angezeigt werden.
Du kannst URLs im GSC nicht selbst aus dem Crawling-Plan “löschen”. Es gibt zwar eine Funktion, mit der du die Entfernung einer URL aus dem Index beantragen kannst, aber das ist nur vorübergehend (für 90 Tage) und nicht dasselbe, wie zu verhindern, dass sie gecrawlt wird.
Du könntest wahrscheinlich URLs über deine robots.txt-Datei blockieren, wenn du wirklich nicht willst, dass sie gecrawlt werden, aber ich glaube nicht, dass das hier eine sinnvolle Maßnahme ist.
Und ja, du kannst eine Umleitungsregel in deiner htaccess-Datei erstellen, die alle URLs, die auf “.htm” enden, auf ein bestimmtes Ziel umleitet, aber auch das ist nicht wirklich ratsam. Was ich hier empfehlen würde, ist, alle 404-Fehler aus dem GSC zu exportieren, sie als behoben zu markieren und für jede Fehler-URL eine Weiterleitung auf ein entsprechendes Ziel einzurichten. Ich denke, in den meisten Fällen kannst du immer noch herausfinden, welche Inhalte auf der alten Seite waren, und ein passendes Weiterleitungsziel finden.
Wenn du nichts unternimmst, wird dir das wahrscheinlich nicht viel schaden, aber du könntest einiges an Potenzial verlieren. Wenn zum Beispiel einige deiner alten Seiten Backlinks von anderen Websites haben, solltest du sie auf jeden Fall auf Ziele umleiten, die ähnliche Inhalte haben.
Ich hoffe, das hilft dir! Lass es mich wissen, wenn du weitere Fragen hast.
Vielen Dank für deine tolle Antwort 🙂 .
Nur noch ein paar letzte Fragen:
Was ist die richtige Weiterleitung für *.htm? Einfach dorthin setzen oder etwas anderes?
Vielleicht muss ich es benutzen, weil ich gesehen habe, dass alte htm-URLs etwa 146 sind. Und es ist wahrscheinlich ein bisschen zeitaufwendig. Ich würde sie natürlich gerne einzeln bearbeiten.
Nochmals vielen Dank 🙂 .
Hallo Shahab,
Ich bin nicht sehr vertraut mit dem Erstellen von htaccess-Dateien, aber das sollte helfen: http://stackoverflow.com/questions/3220377/htaccess-redirect-if-url-contains-a-certain-string
Bitte lass mich wissen, wenn du weitere Fragen hast!
Hallo Eoghan,
Danke, dass du diesen Beitrag verfasst hast. Hast du schon mal eine Reihe von 404-Fehlern gesehen, die mit einem /@-Zeichen nach dem Permalink enden? Ich frage mich, ob es sich dabei um einen Fehler handelt, der von einer Social-Media-Plattform wie Twitter oder Instagram stammt.
So sieht es in den Crawl-Fehlern aus: http://example com/get-404-results/@example
In diesem Beispiel funktioniert der Permalink ohne das @Beispiel perfekt auf einer Live-Seite. Ich habe ungefähr 400 davon.
Ich habe die Seite kürzlich von http auf https umgestellt, aber ich glaube nicht, dass das etwas damit zu tun hat.
Ich würde gerne deine Meinung dazu hören.
Danke!,
Paul
Hallo Paul,
Vielen Dank für diese interessante Frage. Ich habe noch nie einen solchen Fall gesehen, aber ich könnte mir vorstellen, dass es passiert, wenn du zum Beispiel versuchst, auf allen deinen Seiten auf ein Twitter-Profil zu verlinken und im Link-Tag href=”@example” statt href=”https://www.twitter.com/example” eingibst. Crawler oder Browser könnten dies als relativen Link interpretieren und die URL der aktuellen Seite zum URL-Pfad hinzufügen. Das würde dann viele Crawl-Fehler verursachen, genau wie du beschrieben hast.
Ist der “@example”-Teil in allen URLs derselbe? Hast du die “verlinkt von”-Informationen in den Crawl-Fehlerberichten überprüft, um zu sehen, woher die falschen URLs verlinkt sind? Wenn sie intern verlinkt sind, hast du deinen Quellcode auf “@example” überprüft?
Ich hoffe, das hilft. Wenn du magst, kannst du mir noch mehr Infos schicken und ich werde mir das genauer ansehen.
Vielen Dank! Ich war schon dabei, den Verstand zu verlieren, als die 404-Probleme auftauchten. Am besten ist es wirklich, die Seite umzuleiten. Google scheint nicht zu wissen, was noch läuft und was nicht. Anstatt also weiter zu versuchen, Webmaster zu kontaktieren usw. - WEITERLEITEN.
Nochmals vielen Dank,
Faniso
Es freut mich zu hören, dass es geholfen hat. Und danke für das Update!
Hallo Eoghan,
Nachdem ich mir deinen informativen Beitrag durchgelesen habe, frage ich mich, ob du mir einen Rat geben kannst. Ich werde so viele Details wie möglich angeben.
Ich habe vor Kurzem meine mit WordPress erstellte Website gründlich überarbeitet und erhalte eine Menge seltsamer 404-Crawl-Fehler. Beim Relaunch der Seite habe ich Folgendes gemacht:
1) Ich habe die Permalink-Struktur geändert und für jede Seite eine 301-Weiterleitung vom alten Link zum neuen eingerichtet.
2) Als die Seite fertig war, habe ich SSL hinzugefügt.
3) Dann habe ich alle 301-Weiterleitungen wieder ersetzt, um von den alten Links auf die neuen https-Versionen der Seiten zu verweisen.
Außerdem habe ich alle internen Links manuell aktualisiert, damit sie auf die richtigen https-URLs verweisen.
Ich habe dann eine XML-Sitemap bei GSC eingereicht. Vorher gab es keine, weil ich das bei meiner alten Website nicht gemacht hatte.
Wenn Google nun aber beginnt, die Seite zu crawlen, erhalte ich eine Menge 404-Fehler für Links, die wie die alten aussehen, aber https am Anfang haben.
1) Im Wesentlichen hatte ich alte URLs wie diese:
http://www.example.com/blog/2015/05/10/postname
2) Jetzt habe ich neue URLs, die wie folgt aussehen:
https://www.example.com/postname
3) GSC gibt mir 404-Fehler für eine Mischung aus den alten und neuen URLs, die die alte Linkstruktur, aber mit SSL, anzeigen, so wie hier:
https://www.example.com/blog/2015/05/10/postname
Wenn ich eine meiner alten URLs manuell eingebe, wird sie auf die neue Seite weitergeleitet. Wenn ich eine Google-Suche durchführe und auf einen alten Link klicke, wird er ebenfalls auf die neue Seite weitergeleitet. Ich weiß also, dass meine 301-Weiterleitungen in Ordnung sind.
Diese dritten Hybrid-URLs, die Google im GSC nicht finden kann, haben also technisch gesehen nie existiert, da ich mit meiner alten Permalink-Struktur nie SSL hatte. Ich habe auch meine Sitemap überprüft, die ich eingereicht habe, und sie enthält nur die korrekten neuen URLs, aber keine falschen.
Meine Frage ist, ob ich diese Fehler für die hybriden Links einfach ignorieren sollte, da es sich nie um echte Seiten gehandelt hat. Wenn ich sie nicht ignorieren sollte, wie entferne ich sie dann? Das Einrichten von 301-Weiterleitungen scheint kontraintuitiv zu sein, da ich von einer Seite weiterleite, die nie existiert hat, sodass niemand jemals einen Link für diese Hybrid-URLs ‘in freier Wildbahn’ finden würde.
Ich hoffe, das macht alles Sinn :/
Vielen Dank im Voraus für jede Hilfe!
Hallo Richard,
Vielen Dank für das Teilen dieses interessanten Falls. Alles, was du erklärst, macht absolut Sinn. Es sieht also so aus, als hättest du bei der Einrichtung der Weiterleitungen sehr gute Arbeit geleistet.
Dennoch ist es etwas besorgniserregend, dass Googlebot auf deine alten URLs mit https zugreift, obwohl es keine Weiterleitung geben sollte, die auf sie zeigt. Hast du den Reiter “Verlinkt von” in den Crawl-Fehlerberichten überprüft? Du findest ihn, indem du auf jede URL im Bericht klickst. Der Grund, warum ich mir wegen der Fehler Sorgen mache, ist, dass Google, wenn es die “falschen” neuen URLs crawlt, vielleicht gar nicht die richtigen crawlt, was ein Problem darstellen würde. Deshalb wäre es auf jeden Fall eine gute Idee, herauszufinden, wie Google die falschen URLs gefunden hat.
Wenn du magst, kannst du mir eine E-Mail mit deinem Domainnamen und einigen Beispielen für URL-Fehler schicken, damit ich mir das genauer ansehen kann.
Mit freundlichen Grüßen,
Eoghan
Hallo Henn,
Dieser Artikel hilft mir, alle Crawl-Fehler aus der Web Master Console zu entfernen.
Danke
Hallo Shailesh,
Es freut mich zu hören, dass es für dich hilfreich war!
Eoghan
Ich erhalte 4 interne Serverfehler 500 in meiner Suchkonsole. Es ist mit einem Anhang. Wenn ich auf den Link klicke, öffnet sich die Seite ordnungsgemäß, aber wenn ich mit Google abrufe, sagt es unerreichbar. Bitte hilf mir bei diesem Problem.
Hallo Indrani,
Vielen Dank für deinen Kommentar. Ich bräuchte ein paar mehr Informationen, um dir zu helfen. Wenn du magst, kannst du mir eine E-Mail schicken und ich schaue es mir an.
Mit freundlichen Grüßen,
Eoghan
Hallo
Ich habe ein Problem mit Crawl-Fehlern in Google Webmaster. Ich habe den Fehler entfernt, aber 2 oder 3 Tage danach sehe ich eine Menge Fehler in der Liste, aber ich verschiebe keine Seite.
Bitte hilf mir
Hallo Mehrnoosh,
Ich brauche mehr Informationen, um dir zu helfen. Ich werde dir eine E-Mail schicken.
Hallo Eoghan,
Ich habe mindestens einmal pro Woche an den 404-Fehlern gearbeitet, die in den Google-Crawl-Fehlern auftauchen, und mir ist aufgefallen, dass einige immer wieder auftauchen. Das sind alles URLs, die mit Produkten zu tun haben, die nicht nur von der Website, sondern auch von der Sitemap gelöscht wurden. Vor etwa einem Monat habe ich eine Excel-Tabelle erstellt, damit ich den Überblick behalte. Eine davon ist im letzten Monat 4 Mal aufgetaucht - ich weiß, dass sie von der Website und der Sitemap verschwunden ist. Sie existiert auch auf keiner der internen Seiten, die Google angibt.
Wenn die URL in einer externen URL auftaucht, erstelle ich eine 301 und das erledigt es normalerweise, obwohl ich eines Tages eine 301 für eine bestimmte URL erstellt habe und sie 2 Tage später wieder auftauchte... gibt es eine Verzögerungszeit, bis Google die 301 schließlich sieht?
Mir wurde gesagt, dass Google nicht viele 301-Weiterleitungen mag... gibt es eine Grenze, wie viele Weiterleitungen eine Website haben sollte? Sollte ich einige der alten Weiterleitungen entfernen oder ist es in Ordnung, sie beizubehalten?
Dirt E. Harry
Hallo nochmal 🙂
Einige 404-Fehler werden immer wieder angezeigt, auch wenn sie nicht mehr intern oder extern verlinkt sind. Ich muss den Artikel aktualisieren, um das klarzustellen.
Wenn du eine 301-Weiterleitung eingerichtet hast, sollte die URL nicht mehr als 404-Fehler auftauchen. Die einzige Erklärung, die ich mir für den Fehler vorstellen kann, der zwei Tage nach der Einrichtung der 301-Weiterleitung auftaucht, ist, dass die URL kurz vor der Einrichtung der Weiterleitung gecrawlt wurde, aber erst einige Tage später in den Bericht aufgenommen wurde. Die meisten Berichte der Search Console werden nicht in Echtzeit aktualisiert.
Es gibt keine Begrenzung für die Anzahl der Weiterleitungen, die eine Website verwenden sollte, aber es ist auch wichtig, die Funktion nicht zu missbrauchen. Wenn du eine Weiterleitung einrichtest, sollte sie gerechtfertigt sein, d.h. der Inhalt der alten URL sollte auf der neuen URL zu finden sein (oder zumindest eine ähnliche Version). Es ist z. B. keine gute Idee, viele alte URLs auf die Startseite umzuleiten.
Ein Problem, das bei vielen Weiterleitungen auftreten kann, ist, dass deine htaccess-Datei einfach zu groß wird, was sich negativ auf die Ladezeit deiner Seiten auswirkt.
Wenn du alte Weiterleitungen löschen willst, stelle sicher, dass sie nicht mehr benötigt werden, d.h. die weitergeleiteten URLs werden nicht mehr von Nutzern oder Bots aufgerufen.
Ich hoffe, das hilft!
Hallo Eoghan,
Ich weiß deine Antwort wirklich zu schätzen... macht absolut Sinn.
Was die htaccess-Datei angeht, so habe ich bis heute etwa 475 Weiterleitungen. Meine Website ist nicht riesig, aber auch keine kleine Seite - sie wiegt etwa 807 MB.
Mit Luftgewehren ist es so schlimm wie mit Autos - die Hersteller bringen ständig neue Modelle auf den Markt und stellen alte Modelle ein. Ich habe mir überlegt, die Schalter “Verfügbarkeit”, "Angebot" und "Im Verkauf" sowie die Schaltfläche "In den Warenkorb" bei auslaufenden Artikeln zu deaktivieren und den Begriff "Dieses Modell ist leider nicht mehr verfügbar" in die Artikelbeschreibung aufzunehmen.
Wenn es ein Lesezeichen oder einen externen Link zu dem Artikel gibt, weiß der Suchende genau, auf welche Seite er gehen muss, um das neueste/größte Herzklopfen zu finden (wenn er sich mit Luftgewehren auskennt), und der Bot wird den Unterschied nicht erkennen.
Das Ergebnis wäre eine enorme Zeitersparnis beim Löschen der Artikel von der Website, der Sitemap und beim Erstellen von Weiterleitungen und keine 404 mehr - ganz zu schweigen davon, dass man die Schalter einfach wieder einschalten kann, wenn der Artikel wieder auftaucht und wieder verfügbar ist... Was meinst du?
Dirt E. Harry
Präsident und CEO
http://topairgun.com
Ja, das klingt nach einem guten Plan! Überlege dir, ob du auf den Seiten der Produkte, die derzeit nicht mehr erhältlich sind, nützliche Links zu ähnlichen Produkten einfügen kannst. Hier ist ein Beispiel für eine Produktseite für ein auslaufendes Produkt, die einen Link zu den neueren Versionen des Produkts enthält: https://www.ecom-ex.com/products/archive/communication/ex-handy-07/
Danke Eoghan!
Du hast mir gerade wieder einen riesigen Batzen Zeit gespart! Ich liebe es, wenn ein Plan aufgeht,
Dirt E. Harry
Präsident und CEO
http://topairgun.com
Ich habe das nicht gemacht, weil ich keine E-Commerce-Seiten betreibe, aber eine andere Möglichkeit ist, die alte Seite bestehen zu lassen und einfach eine Nachricht und einen Link zum neuen Produkt einzufügen. Überlasse es nicht dem Suchenden, den Weg zu finden.
Wenn sich die Produkte zu sehr ähneln, ist das vielleicht keine gute Idee, aber wenn sie unterschiedlich genug sind, um nicht als Duplikate gesehen zu werden, könnte das eine Option sein.
Du musst allerdings einige Dinge abschalten, um sicherzustellen, dass Artikel nicht versehentlich gekauft oder in der Suche angezeigt werden, aber das kann anhand des Status=”discontinued” automatisiert werden. Bitte einen Programmierer, die entsprechenden Änderungen an der Vorlage vorzunehmen, damit es so einfach ist wie das Setzen einer Markierung.
Dieser Artikel hat mich über vieles aufgeklärt und es mir ermöglicht, die Fehler auf meiner Website zu bereinigen. Ich hatte mich schon immer gefragt, ob sich die Fehler auf meine Suchmaschinenoptimierung auswirken und ob es helfen würde, sie zu beseitigen.
Danke, Larry!
Hallo Eoghan,
Auf einer meiner Websites häufen sich URL-Fehler (Hunderte pro Tag)
Alle angezeigten Seiten wurden noch nie auf der Website erstellt.
Leider, und ich weiß nicht warum, wird der Fehlerursprung nicht in der Search Console angezeigt, so dass ich nicht nachvollziehen kann, woher diese 404 generiert werden.
Hier ist ein Beispiel: https://www.screencast.com/t/EYxfGXiIny
Was empfiehlst du mir zu tun, und hat das Auswirkungen auf das Ranking der Seite (das allmählich abnimmt)?
Hallo Tobi,
Das klingt seltsam, vor allem, wenn wir jeden Tag über Hunderte von URLs sprechen. Steht bei keiner von ihnen etwas im Reiter “verlinkt von”? Hat dieses Problem erst vor kurzem begonnen oder ist es schon lange so?
Wie ich sehe, hast du eine 301-Weiterleitung für die Beispiel-URL im Screenshot eingerichtet. Hast du das auch für andere URLs gemacht? Hast du sie als fixiert markiert? Sind die URLs dadurch nicht mehr aufgetaucht?
Wenn du mir noch ein paar Beispiel-URLs schickst, kann ich mir vielleicht ein Bild davon machen, was da los ist. Ich würde mir im Moment keine allzu großen Sorgen um das Ranking der Seite machen, aber das ist definitiv etwas, das du herausfinden und beheben solltest. Ich werde dir dabei so gut wie möglich helfen, wenn du mir mehr Informationen gibst 🙂 .
Eoghan
Hallo Eoghan,
Vielen Dank für deine schnelle und ausführliche Antwort und, was noch wichtiger ist, dein Angebot, mir zu helfen. Das bedeutet mir sehr viel,
Ja, die Crawl-Fehler häufen sich schnell https://www.screencast.com/t/qNgKnbWWR
Dieses Problem hatten wir vor ein paar Wochen. Wir haben anfangs 301-Weiterleitungen eingerichtet und alle als repariert markiert, aber ich bin mir jetzt nicht mehr sicher, ob das klug war.
Seitdem sind die Fehler immer wieder aufgetreten, obwohl ich nicht sicher bin, dass es sich um die gleichen URLs handelt
Hier sind ein paar dieser neuen URLs:
https://www.al-ram.net/i22598
https://www.al-ram.net/pli-dramatist-tact-nel/236/12720
https://www.al-ram.net/complicated/lenelenari/louis+r%E3%83%9D%E3%82%A4%E3%83%B3%E3%83%88%EF%BC%91%EF%BC%90%E5%80%8D%E3%82%AD%E3%83%A3%E3%83%B3%E3%83%9A%E3%83%BC%E3%83%B3%E2%99%AA%E3%83%AB%E3%82%A4%E3%83%B4%E3%82%A3%E3%83%88%E3%83%B3
Sie zeigen alle nicht, woher der Fehler kommt:
https://www.screencast.com/t/TOhydUah6xd7
Nochmals vielen Dank für deine Hilfe
Tobi
Hallo Tobi,
Danke für die zusätzlichen Informationen. Dies ist in der Tat ein mysteriöser Fall. Ich habe versucht, herauszufinden, wo Googlebot diese URLs gefunden haben könnte, aber ich konnte nirgendwo Hinweise oder Spuren finden. Ich habe eine ganze Weile gesucht, aber es gibt wirklich nichts 🙁
Die Domain ist recht jung (etwa 2 oder 3 Jahre) und es gab noch nie eine andere Website auf derselben Domain, richtig? Besitzt das Unternehmen noch andere alte Domains, die es auf diese Domain umgeleitet hat?
Es ist wahrscheinlich eine gute Idee, 301-Weiterleitungen für die Fehler-URLs einzurichten, denn so besteht die Chance, dass Google sie irgendwann nicht mehr crawlt und die Fehler nicht mehr in deinen Berichten auftauchen.
Es gibt zwei mögliche Szenarien, warum diese URLs gerade jetzt gecrawlt werden könnten:
1. Die URLs, die gerade gecrawlt werden, befinden sich (aus welchen Gründen auch immer) in einem Zeitplan für den Crawler von Google und werden gerade gecrawlt. Wenn du 301-Weiterleitungen für alle Fehler-URLs einrichtest, wird das helfen, denn die Fehler werden nicht mehr auftauchen und Google wird wahrscheinlich aufhören, die URLs zu crawlen, sobald es merkt, dass die 301-Weiterleitung für immer da ist.
2. Die URLs sind nicht alt, sondern werden gerade jetzt ständig von einer Quelle generiert, die wir noch nicht identifizieren konnten. In diesem Fall sollten wir wirklich versuchen, herauszufinden, woher die URLs kommen und einen Weg finden, sie zu stoppen.
Ich schlage vor, dass du vorerst weiterhin 301-Weiterleitungen für alle neu auftretenden Fehler einrichtest und die Anzahl der neuen Fehler im Auge behältst. Wenn sie zurückgehen, ist das in Ordnung. Wenn nicht, lass es mich wissen und wir können uns das Problem noch genauer ansehen, um herauszufinden, wo diese URLs generiert werden.
Überprüfe außerdem alle Fehler auf die “verlinkt von”-Informationen. Das kann sehr wertvoll sein, um das Problem zu lösen. Wusstest du, dass du über die API alle Fehler auf einmal exportieren kannst? Hier ist ein Link, mit dem du das ausprobieren kannst: Google APIs-Explorer. Auf diese Weise musst du nicht jeden Link manuell überprüfen.
Ich hoffe, das hilft fürs Erste! Es tut mir leid, dass ich das Problem noch nicht vollständig lösen konnte.
Lass mich wissen, wie es läuft!
Eoghan
Vielen Dank noch einmal!
Ich habe alle Fehler exportiert, aber die Herkunft der Links wird nicht angezeigt (ich habe überprüft, dass dieses Feld im Bericht enthalten ist).
Wir fahren fort und 301 diese neuen Fehler, die jetzt über 2000 sind und täglich um 200+ ansteigen.
Ich warte jetzt auf die Antwort des Unternehmens zu ihren Domains,
Ich werde euch im Laufe der Woche auf den neuesten Stand bringen
Nochmals vielen Dank, dass du dir die Zeit genommen hast, dieses Problem zu lösen. Dein Engagement übertrifft alle meine Erwartungen.
Hallo Tobi,
Okay, lass mich wissen, wie es läuft!
Eoghan
Ich glaube, ein Grund, warum ich so viele 404-Seiten sehe, ist, dass jemand meine Seite kopiert und sie irgendwo gehostet hat. Ich habe vor über 6 Jahren tausende von Seiten gelöscht und Google sagt mir immer noch, dass ich eine 404 für eine dieser URLs habe.
Ich bin von HTML zu WP und dann zu SSL gewechselt. Ich habe es vermasselt und über 20.000 Seiten in ein falsches Verzeichnis verschoben und meinen Fehler vor Monaten gelöscht. GWM sagt mir immer noch, dass ich all diese 404-Seiten von diesem Fehler habe. Es scheint, dass ich mit den GWM-Tools nie gewinnen kann.
Google Panda hat mein Geschäftsmodell zerstört, aber so ist das Leben.
Bietet jemand bezahlte Beratung an, um meine Domain halbwegs fehlerfrei zu bekommen?
Hallo Duncan,
Danke, dass du deine Erfahrungen mit uns teilst. Es tut mir leid zu hören, dass du so viel Pech mit Crawl-Fehlern hattest. Hoffentlich kann dir ein anderer Leser mit einer Beratung weiterhelfen.
Viel Glück und lass mich wissen, wenn ich etwas für dich tun kann.
Hi Eoghan (cooler Name, Kumpel), danke für diesen Beitrag - sehr aufschlussreich.
Ich arbeite an einer Website, die wir im April 2017 neu gelauncht haben. Das Dilemma, das ich habe, ist, dass wir etwa 1137 “Redirect 301 /old-url" eingerichtet haben. https://www.website.com/new-url/”, aber ich habe die Vermutung, dass viele von ihnen jetzt auch zu 404s führen.
Wie kann ich diese Liste der Weiterleitungen bequem und genau anzeigen? Ich habe es mit http://www.redirect-checker.org/bulk-redirect-checker.php um zu sehen, dass die vollständigen alten URLs tatsächlich gut umgeleitet werden - aber sie führen immer noch zu 404s.
Bitte helfen Sie mir und geben Sie mir Ratschläge. Wir wären dir sehr dankbar.
Danke
Yatish
Hallo Yatish,
Vielen Dank für deinen Kommentar. Normalerweise verwende ich Screaming Frog, um Listen von URLs zu prüfen. Es hat einen Listenmodus, in den du einfach alle URLs einfügen kannst. Das Tool fragt dann eine nach der anderen ab und gibt dir alle relevanten Daten zurück, einschließlich der Statuscodes. Das Tool, das du verlinkt hast, ist wahrscheinlich gut geeignet, um nur die Statuscodes zu prüfen, auch wenn du nur 100 URLs auf einmal prüfen kannst.
Ich bin mir nicht sicher, ob ich deine Frage richtig verstanden habe. Wie sah das Ergebnis aus, das dir das Tool geliefert hat? Haben die URLs, die du eingefügt hast, zu 404-Fehlern geführt oder nicht? Wenn du mir ein paar genauere Informationen schickst (hier oder per E-Mail), kann ich mir das genauer ansehen.
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan,
Ich habe ein ständiges Problem mit WT.
Ich habe eine Reihe von Seiten, die nicht mehr existieren - meist sind es Blogseiten, die entweder die URL geändert haben oder gelöscht wurden. Einige sind sogar komplett nicht indiziert, z. B. Tag-/Kategorieseiten.
Regelmäßig gräbt Google sie jedoch wieder aus und zeigt sie als Crawl-Fehler an. Ich gehe jedes Mal den gleichen Prozess durch: Sie existieren nicht mehr - sie haben keine Backlinks, also sage ich Google einfach, dass es sie ignorieren soll.
Einen Monat später fangen wir das Ganze wieder von vorne an. Aargh!!!
Mir ist aufgefallen, dass die Registerkarte “Verknüpft von” in einigen Fällen das http-Äquivalent anzeigt. Http? Wir haben seit fast 2 Jahren kein einfaches http mehr benutzt.
Wir müssen diesen Mist ein für alle Mal loswerden - im besten Fall ist er ärgerlich, im schlimmsten Fall beeinträchtigt er unsere Platzierungen.
Irgendwelche Ideen?
Hallo John,
Das ist ein häufiges Problem: Google wird URLs, die es in der Vergangenheit entdeckt hat, immer wieder neu crawlen, auch wenn sie 404-Fehler zurückgeben, solange es denkt, dass ihr Inhalt wieder auftauchen könnte. Es gibt zwei Möglichkeiten, die 404-Fehler loszuwerden:
1. Wenn du ein gutes Weiterleitungsziel für die URL identifizieren kannst (eine, die denselben oder einen sehr ähnlichen Inhalt hat), kannst du eine 301-Weiterleitung einrichten.
2. Wenn du kein gutes Weiterleitungsziel findest, kannst du den Statuscode der URL in 410 ändern. Das ist ein Signal für Google, dass der Inhalt absichtlich entfernt wurde. Bitte beachte, dass 410-URLs immer noch als 404-Fehler in der Google Search Console angezeigt werden, aber es ist unwahrscheinlicher, dass Google sie weiterhin recrawlt.
Was die Informationen auf der Registerkarte “Verlinkt von” angeht: Hier steht nur, wo Google die URL entdeckt hat, daher sind die Daten oft veraltet. Es wäre wahrscheinlich besser, wenn sie es “Link zuletzt gefunden am” oder so ähnlich nennen würden.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Update: 410-Fehler werden jetzt als 410-Fehler in der Google Search Console angezeigt und nicht mehr als 404-Fehler markiert.
Ich habe ein großes Problem: Ich habe 500 Serverfehler und es werden von Tag zu Tag mehr. Bitte hilf mir, sie zu beheben. Bitte helfen Sie mir
Hallo Arbaz,
Ich helfe dir gerne, wenn du mir mehr Informationen schickst! Du kannst die Details hier teilen oder einfach auf die E-Mail antworten, die ich dir jetzt schicke.
Mit freundlichen Grüßen,
Eoghan
Danke für all diese tollen Tipps! Ich habe versucht, eine ganze Reihe von Fehlern in den Google Webmaster Tools zu beheben und bin nicht weitergekommen.
Mir ist aufgefallen, dass ich über 2.000 “Nicht gefunden”-URL-Fehler erhalten habe. Fast alle davon sind entweder Beiträge und Seiten mit “/Twitter” und/oder “/Pinterest”. Ich habe alle Social-Share-Links auf der Seite überprüft und sie funktionieren einwandfrei.
Hast du eine Idee, wie du das Problem beheben kannst? Das ist eine sehr merkwürdige Fehlermeldung!
Ich danke dir!
Sorry! Ignoriere meinen Kommentar. Es stellte sich heraus, dass es zwei soziale Textlinks in der Fußzeile waren, die nicht richtig verlinkt waren. Ich habe nicht daran gedacht, das zu überprüfen!
Hallo Ricky,
Ich bin froh, dass du es herausgefunden hast!
Eoghan
Gut gemacht und sehr ausführlich! Um etwas zu wiederholen, was du über 404-Fehler gesagt hast. Viele meiner Kunden machen sich Sorgen, wenn dieser Fehler auftaucht, aber in Wirklichkeit ist es eine gute Sache, wenn ein ehemaliger SEO oder Mitarbeiter einen Beitrag oder Inhalt schreibt, der keinen Bezug hat oder nutzlos ist, weil es sich um gesponnenen Inhalt handelt. Lass die 404 stehen und sage “diese Seite ist für immer weg”.
Glücklicherweise habe ich festgestellt, dass mit dem jüngsten Google-Update zu 301- und 302-Weiterleitungen mehr SEO-Saft durchgelassen wird und 404-Inhalte genauso schnell entfernt werden können. Das ist gut, wenn du alte, nicht verwandte Inhalte loswerden willst. Es kann aber auch schlecht sein, wenn du beabsichtigst, auf die richtige Seite weiterzuleiten, es aber nicht getan hast. Der Sinn der 404-Fehlermeldung ist es, Inhalte zu erkennen, die derzeit nirgendwo hingehören, und sie zu korrigieren.
Hallo Anuj,
Vielen Dank, dass du deine Erfahrungen mit uns geteilt hast!
Mit freundlichen Grüßen,
Eoghan
Hallo Eoghan,
Am 9.6.17 hast du gesagt, dass es keine Begrenzung für die Anzahl der Weiterleitungen gibt, die eine Website nutzen sollte, aber es ist wichtig, die Funktion nicht zu missbrauchen. Wenn du eine Weiterleitung einrichtest, sollte sie gerechtfertigt sein. Das bedeutet, dass der Inhalt der alten URL auf der neuen URL zu finden sein sollte (oder zumindest eine ähnliche Version). Es ist z. B. keine gute Idee, viele alte URLs auf die Startseite umzuleiten.
Ein Problem, das bei vielen Weiterleitungen auftreten kann, ist, dass deine htaccess-Datei einfach zu groß wird, was sich negativ auf die Ladezeit deiner Seiten auswirkt.
Ich habe an diesen Weiterleitungen gearbeitet und habe bis jetzt etwa 650 davon. Meine Website wiegt im Moment 830 MB. Sind 650 Weiterleitungen in meiner htaccess-Datei eigentlich viel? Wenn nicht, wo liegt der Schwellenwert, ab dem es zu viele sind und ich einen negativen Einfluss auf die Ladezeit meiner Seiten bemerke?
Dirt E. Harry
Präsident & CEO
http://topairgun.com
Hi Dirt E. Harry,
Schön, wieder von dir zu hören!
Ich kann dir nicht genau sagen, wann eine .htaccess-Datei ZU groß ist (weil ich es nicht weiß), aber ich habe schon Websites mit Zehntausenden von Weiterleitungen gesehen, bei denen es keine nennenswerten Probleme gab. Ich denke also, dass du mit deinen 650 Weiterleitungen auf der sicheren Seite bist.
Behalte einfach die Antwortzeiten deines Servers und die Ladezeiten deiner Seite im Auge, dann wird alles gut.
Danke Eoghan!
Sir, bitte helfen Sie mir, aus dieser beängstigenden Situation herauszukommen. Seit sechs Monaten läuft meine Website wie gewohnt und Google ruft die URLs langsam ab. Aber plötzlich - seit zwei Wochen - zeigt Google absurde Ergebnisse an. Die Zahl der 503-, 404- und 303-Fehler steigt von Tag zu Tag, Alexa wird immer höher, Keywords, die unter 100 Nummern existieren, werden obsolet, der Traffic sinkt usw. Bitte schlagen Sie mir vor, wie ich meine Website, eine E-Commerce-B2B-Website, in den Griff bekomme. Ich bin schockiert über die Google-Aktivitäten und ich habe Angst, dass solche Dinge passieren. Bitte schlagen Sie mir vor, wie ich das kontrollieren kann.
Hallo Deepak,
Vielen Dank für deinen Kommentar und Entschuldigung für meine späte Antwort. Ich hatte in den letzten Wochen Schwierigkeiten, mit all den Kommentaren Schritt zu halten.
Deine Frage ist sehr allgemein gehalten, aber ich werde versuchen, dir einige Antworten zu geben: Wenn Crawl-Fehler in der Google Search Console angezeigt werden, gibt es normalerweise einen guten Grund dafür, auch wenn es manchmal schwer ist, ihn auf Anhieb zu erkennen. Wenn du einen Fehler überprüfst und alles mit der Seite in Ordnung zu sein scheint, gibt es verschiedene Szenarien. Der Fehler könnte vorübergehend gewesen sein und in diesem Fall solltest du nur sicherstellen, dass es sich nicht um einen wiederkehrenden Fehler handelt. Eine andere Möglichkeit wäre, dass der Fehler nur auftritt, wenn Google versucht, die Seite zu holen, aber nicht, wenn du sie mit deinem Browser aufrufst. Es ist eine gute Idee, ein Crawling-Tool wie Screaming Frog zu verwenden und die Seite mit verschiedenen Einstellungen zu crawlen, um Fehler zu finden: Mit und ohne JavaScript-Rendering, mit verschiedenen User Agents (einschließlich Googlebot), mit und ohne robots.txt und so weiter. Wenn du tiefer einsteigen willst, kannst du auch eine Logdateianalyse durchführen, um herauszufinden, wie und wann Suchmaschinenbots deine Seite crawlen.
Ich hoffe, das hilft als erste allgemeine Antwort auf deine Frage. Bitte lass mich wissen, wenn ich noch etwas für dich tun kann.
Ich habe alle 404-Fehler mit überprüft:
https://www.google.com/webmasters/tools/crawl-errors?hl=en&siteUrl=https://globalcommercialparts.com/#t2=1
und fand wirklich gruselige Sachen wie:
appliance-parts/rotisserie/twitter.com
appliance-parts/rotisserie/youtube.com
appliance-parts/freezer/twitter.com
appliance-parts/food-storage/youtube.com
Wie wurde diese Url vom Google-Crawler gebaut?
Wie kann man solche Probleme lösen?
Hallo Leo,
Diese Fehler werden durch fehlerhafte interne Links auf deiner Seite verursacht.
Zum Beispiel auf https://globalcommercialparts.com/appliance-parts/rotisserie.html, hast du die folgenden Links in der Fußzeile:
<li class="”twitter”"><a href="/de/”twitter.com”/">Twitter</a></li>
<li class="”youtube”"><a href="/de/”youtube.com”/">YouTube</a></li>
Diese werden als interne Links interpretiert zu
https://globalcommercialparts.com/appliance-parts/rotisserie/twitter.com
und
https://globalcommercialparts.com/appliance-parts/rotisserie/youtube.com
weil das Protokoll in den URLs fehlt. Du solltest die URLs in den Links ändern in https://www.youtube.com/ und https://twitter.com/ um dies zu beheben.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Toller Artikel - danke für die vielen Informationen! Meine Frage ist: Kann man bei der Verwendung des APIs Explorer die HAUPT-Website als siteUrl eingeben? Werden dadurch alle (etwa 500) Crawl-Fehler auf meiner Website behoben?
Vielen Dank im Voraus für deine Hilfe,
Dars
Hallo Dars! Du kannst den API-Explorer verwenden, um exportieren Crawl-Fehler, oder um sie als fix markieren (hier), aber nicht, um tatsächlich fix sie. Leider musst du sie mit dem API-Explorer immer noch einzeln als repariert markieren. Über die API könntest du sie wahrscheinlich alle auf einmal als behoben markieren, aber dafür brauchst du ein Skript. Um deine Crawl-Fehler tatsächlich zu beheben, musst du sie immer noch einzeln analysieren, um die Ursache des Problems zu finden. Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Ich bin in großen Schwierigkeiten. Ich habe 27 Serverfehler, 3 nicht gefunden 127 und es werden von Tag zu Tag mehr. Bitte hilf mir, sie zu beheben. Bitte helfen Sie mir
http://www.Techmanish.com
Hallo Manish,
Wenn du mir ein paar genauere Infos schickst, helfe ich dir gerne weiter!
Hallo Eoghan Henn, bitte gib uns Details zu den von robots.txt blockierten Ressourcen und wie wir diese Fehler lösen können.
Danke!!!
Hallo Agon,
Es tut mir leid, dass ich so spät geantwortet habe. Ich hatte ein paar verrückte Wochen und habe es nicht geschafft, mit all den Kommentaren hier Schritt zu halten.
Der Fehler, auf den du dich beziehst, tritt normalerweise auf, wenn der mobile Bot von Google über deine robots.txt-Datei für bestimmte URLs gesperrt ist. Du solltest die Fehler-URLs überprüfen und dich fragen, ob der mobile Bot sie crawlen soll, und wenn ja, sicherstellen, dass sie nicht über deine robots.txt-Datei blockiert werden.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Hy Sir!
Ich mag deinen Beitrag sehr und habe ihn von Anfang bis Ende gelesen...
Die Frage ist nun: “Wie können wir den Crawl-Fehler 404 “nicht gefunden” vollständig entfernen und die Beiträge löschen, die ich bereits entfernt habe und die den Fehler 404 "nicht gefunden" verursachen...
Ich möchte meine Website völlig fehlerfrei machen...
Bitte hilf mir!
Ich werde extrem auf deine Antwort warten.....
Danke im Voraus
Hallo Alex,
Vielen Dank für deinen Kommentar. Es tut mir leid, dass du so lange auf meine Antwort warten musstest.
Es gibt nur sehr wenige Websites, die völlig fehlerfrei sind, aber das ist ein gutes Ziel!
Wenn du alle 404-Fehler verschwinden lassen willst, musst du 301-Weiterleitungen für alle Fehler-URLs zu funktionierenden Zielen einrichten. Achte aber bitte darauf, dass die Ziele mit dem Inhalt der ursprünglichen URLs übereinstimmen! Es muss nicht genau derselbe Inhalt sein, aber ein gutes Äquivalent. Es wäre keine gute Idee, Weiterleitungen einzurichten, nur um die Fehler verschwinden zu lassen, wenn du keine passenden Ziele hast, auf die du die URLs umleiten kannst.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
hallo,
Meine Website hatte viele 404-Fehler und ich habe sie mit Google Webmaster behoben. Aber einige von ihnen wiederholen sich jeden Tag.
(das sind die Links, die ich von anderen Seiten oder Blogs erhalten habe und diese URLs sind jetzt geändert)
bitte hilf mir.
danke.
Hallo Leila,
Das Markieren von Fehlern als behoben in den Google Webmaster Tools behebt die Fehler nicht wirklich. Wenn sie am nächsten Tag (oder später) wieder auftauchen, bedeutet das, dass Google erneut versucht hat, auf die URLs zuzugreifen.
Wenn du Links von anderen Websites auf URLs erhalten hast, die nicht mehr existieren, ist es sehr wichtig, dass du 301-Weiterleitungen von den Fehler-URLs auf Seiten einrichtest, die funktionieren und ähnliche Inhalte haben. Auf diese Weise verhinderst du nicht nur, dass 404-Fehler in der Google Search Console angezeigt werden, sondern du schickst auch Nutzer/innen, die auf die Links klicken, zum richtigen Ziel und lenkst die Relevanz, die diese Links auf deine Website bringen, auf wichtige Seiten, anstatt sie an eine Fehlerseite zu verlieren.
Bitte lass mich wissen, wenn du weitere Hilfe in dieser Angelegenheit brauchst.
Danke für diesen Artikel. Wir haben vor ein paar Monaten einen Relaunch einer ziemlich großen Seite durchgeführt. Wir konnten die 404 von etwa 110.000 Seiten auf etwa 50.000 Seiten reduzieren. Alle wichtigen Seiten wurden umgeleitet, so dass die 50.000 fehlenden Seiten im Moment nur ’Kollateralschaden’ sind, aber sie bleiben im Google-Index hängen. Deshalb würde ich sie gerne alle auf die Startseite weiterleiten. Weißt du, wie ich mehr als 1000 Seiten herunterladen kann? Danke
Hallo Simon,
Vielen Dank für deinen Kommentar. Leider glaube ich, dass du nicht mehr als 1000 Fehler auf einmal exportieren kannst. Diese Grenze scheint auch bei der Verwendung der API zu gelten.
Werden die 50000 verbliebenen Seiten tatsächlich indiziert (d. h. sie erscheinen in den Google-Suchergebnissen, wenn du eine Site-Suche für deine Domain durchführst) oder tauchen sie nur in den Fehlerberichten in der Google Search Console auf?
Ich würde generell davon abraten, eine so große Anzahl von URLs einfach auf die Startseite umzuleiten. Das würde der Situation nicht wirklich etwas bringen. Bessere Optionen wären, passende Weiterleitungsziele zu finden oder den Statuscode auf 410 zu ändern, um zu signalisieren, dass die Seiten absichtlich entfernt wurden.
Bitte lass mich wissen, wenn du weitere Fragen hast.
Sehr geehrter Herr,
Wie kann ich einen Crawler-Fehler in den Webmaster-Tools entfernen? Bitte informiere mich Punkt für Punkt.
Folgende Fehler auf meiner Website.
Aktueller Status
Crawl-Fehler
Website-Fehler
DNS Server Konnektivität Robots.txt abrufen
URL-Fehler
2 Weich 404
3 Nicht gefunden
Hallo Thalib,
Deine geringe Anzahl an Crawl-Fehlern ist wirklich kein Grund zur Sorge. Wenn du sie trotzdem beheben willst, sollten dir diese beiden Abschnitte des Beitrags helfen:
https://www.rebelytics.com/crawl-errors-google-search-console/#what-are-soft-404-errors
https://www.rebelytics.com/crawl-errors-google-search-console/#the-classic-404-crawl-error
Wenn etwas unklar bleibt, lass es mich bitte wissen. Ich berate dich dann gerne weiter.
Hallo Eoghan,
Grüße des Tages!
Ich habe deinen Artikel gelesen. Dein Artikel hat mir ein wenig geholfen, aber ich stecke irgendwo fest und brauche deine Hilfe. Meine Website hat eine Desktop- und eine mobile Seite. Ich habe im Crawl-Fehlermenü des Webmasters überprüft, dass einige Desktop-URLs einen 404-Fehler haben, den ich mit Hilfe des Teams beheben kann, aber wenn ich zu den Smartphone-URLs gehe, wird eine fehlerhafte Umleitung angezeigt. 62 Links zeigen eine fehlerhafte Weiterleitung auf der Smartphone-URL an. Bitte helfen Sie mir, wie ich diese fehlerhaften Weiterleitungen auf den Smartphones beheben kann. Bitte hilf mir.
Grüß Gott,
Ankit
Hallo Ankit,
Vielen Dank für deine interessante Frage.
Der Fehler “fehlerhafte Weiterleitungen” tritt häufig auf, wenn Weiterleitungen für mobile Nutzer/innen nicht zu der exakten Entsprechung der Desktop-URL führen, die sie auf einem mobilen Gerät angefordert haben, sondern zur Startseite der mobilen Version. Ist das bei deiner Website der Fall?
Mehr Infos von Google hier: Fehlerhafte Weiterleitungen.
Wenn du magst, kannst du mir mehr Informationen geben und ich werde mir dein Problem genauer ansehen.
Hallo Eoghan,
Danke, dass du mir geholfen hast. Wenn ich in Zukunft ein Problem habe, werde ich dich sicher benachrichtigen.
Danke
Ich bin Vivek Suthar. Als meine Website live war, hatte ich Links in Großbuchstaben und Google hat alle Links indexiert, aber ich habe ein gutes Ergebnis erzielt. Nachdem ich alle Links in Kleinbuchstaben umgewandelt hatte, habe ich die Sitemap erneut eingereicht, aber jetzt habe ich meinen Traffic verloren, aber meine Keyword-Position hat sich nicht verändert. Bitte geben Sie mir einen Vorschlag.
Hallo Vivek,
Vielen Dank für deinen Kommentar.
Es ist merkwürdig, wenn du deinen Traffic verlierst, aber nicht deine Rankings. Vielleicht ist einer der Datensätze, die du verwendest, nicht korrekt oder nicht aktuell?
Wenn du alle deine URLs änderst, kann das zu Traffic-Verlusten führen, vor allem, wenn du deine alten URLs nicht auf die neuen URLs umleitest. Und selbst dann solltest du mit einem vorübergehenden Verlust an organischem Traffic rechnen. Hast du Weiterleitungen von deinen alten Großbuchstaben-URLs zu deinen neuen Kleinbuchstaben-URLs eingerichtet?
Bitte lass mich wissen, ob ich etwas für dich tun kann, um dieses Problem zu lösen.
Schöner Artikel.
Ich habe allerdings eine Frage. Ich habe 188 Links, die auf // enden, und wenn ich sehen will, von wo aus sie verlinkt sind, erscheint der Reiter “Verlinkt von” nicht. Was hat das zu bedeuten?
Danke!.
Hallo Casper,
Vielen Dank für deinen Kommentar. Google zeigt nicht immer “verlinkt von”-Informationen an. Das passiert oft bei sehr alten URLs oder manchmal (aber wahrscheinlich nicht in deinem Fall) auch bei URLs, auf die Google zugreift, obwohl es keine Links gefunden hat, die auf sie verweisen (z.B. m.deinedomain.com, um zu prüfen, ob es eine mobile Subdomain gibt).
Kannst du Weiterleitungsziele für die fehlerhaften URLs bestimmen? Wenn ja, würde ich dir empfehlen, sie einzurichten und dir nicht zu viele Gedanken darüber zu machen, wie Google auf die URLs gekommen ist.
Ich hoffe, das hilft dir. Bitte lass mich wissen, wenn du weitere Fragen hast.
Hi,
In meiner Suchkonsole wird der Crawl-Fehler 404 angezeigt und der gleiche Link wird aus dem Dashboard meiner Website (Website-Builder) gelöscht. Ich habe alle Fehler als behoben markiert, aber sie funktionieren nicht oder die gleiche Seite zeigt den Fehler 404.
Hallo Lokesh,
Vielen Dank für deinen Kommentar. Wenn du einen Fehler als behoben markierst, wird er nur nicht mehr in deinen Berichten angezeigt, aber der Fehler wird nicht wirklich behoben. Wenn du das erreichen willst, solltest du auch eine 301-Weiterleitung von der URL, die nicht mehr funktioniert, zu einem passenden Ziel einrichten, falls es eines gibt.
Ich hoffe, das hilft dir. Bitte lass mich wissen, wenn du weitere Fragen hast.
Auf unserer Unternehmenswebsite gibt es eine Seite namens /Folsom
Aber ich habe festgestellt, dass im WMT eine Reihe von zufällig erscheinenden 404-Seiten, wie z. B.:
Folsom/UaURY/
Folsom/LMZVM/
Folsom/mTfQh/
Folsom/hTWSZ/
Es gibt Dutzende davon, und ich habe keine Ahnung, woher sie kommen. Ich frage mich, ob Googlebot versucht, eines der ASP.NET-Formular-Tags zu crawlen, aber das würde keinen Sinn ergeben.
Wenn es einen einfachen Weg gibt, dies zu verhindern, lass es mich wissen.
Ich habe mit unserer IT-Abteilung gesprochen und wir konnten herausfinden, woher diese URLs kamen. Ein externes E-Mail-Programm von einem unserer Kunden hat diese URLs generiert, was erklärt, warum es keinen Referrer gab. Danke
Hallo Mike,
Danke, dass du diesen interessanten Fall geteilt hast. Wie ist Google dazu gekommen, diese URLs zu crawlen?
Mit freundlichen Grüßen,
Eoghan
Hallo
Ich erhalte jeden Tag einige 404-Fehler von “Google Webmaster Tools”, wobei diese 404-Seiten (die laut Google) gelöscht wurden
für eine lange Zeit und ich habe diese alten URLs auch schon mehrmals mit “remove urls” Tools bereinigt.
Ich habe keine andere Möglichkeit gefunden, außer “301 redirect” und ich habe ein Wordpress-Plugin benutzt, um das zu tun. Das Plugin hat mein Problem gelöst, aber reduziert
meine Website-Geschwindigkeit, so dass meine Website überhaupt nicht mehr geladen werden konnte.
Ich habe die “Redirect”-Technik per htaccess-Datei (ohne Plugin) angewandt, aber ich habe dieses Problem (Verringerung der Seitengeschwindigkeit) wieder...!
Ich würde es zu schätzen wissen, wenn du mir schnell helfen würdest, denn ich kann keinen anderen Weg zur Lösung finden und dieses Problem ist wichtig für mich.
Vielen Dank!.
Bitte beachte, dass das Markieren von Fehlern als behoben für Google nichts ändert: Sie werden die Fehler-URLs weiterhin von Zeit zu Zeit crawlen, um zu überprüfen, ob sie immer noch nicht funktionieren.
301-Weiterleitungen sind eine gute Möglichkeit, Fehler zu beseitigen, solange du gültige Weiterleitungsziele findest.
Eine .htaccess-Datei zu verwenden, scheint die richtige Option zu sein. Wie viele Regeln hast du ihr hinzugefügt? Sie müsste schon extrem groß sein, um deine Website zu verlangsamen. Die Leistung deiner Server zu verbessern, könnte der richtige Weg sein.
Ich hoffe, das hilft!
Es gibt viele Produkte auf meiner Website, viele Produkte stehen nicht mehr zum Verkauf, und wir haben die Produkte, die nicht mehr verkauft werden, direkt gelöscht. Infolgedessen gibt es viele 404-Seiten (mehr als 1.000) in der Google Search Console. In letzter Zeit sind die Google-Rankings rapide gesunken. Wie soll ich damit umgehen?
301 auf die Startseite umgeleitet? Oder blockierte Ressourcen durch robots.txt?
Danke!
Hallo Kingbig,
Vielen Dank für deinen Kommentar. Zunächst einmal: Wenn du Rankings verloren hast, liegt das wahrscheinlich nicht an den 404-Fehlern in deinen Berichten. 404-Fehler führen nicht direkt zu Rankingverlusten. Was passiert sein könnte, ist, dass die Seiten, die du gelöscht hast, vorher gerankt haben - daher die Rankingverluste nach dem Löschen der Seiten.
Hier sind einige Dinge, die du tun kannst:
Wenn du eine Seite wirklich löschen musst, leite die URL auf ein ähnliches Ziel um, NICHT auf die Startseite. Ein ähnliches Ziel könnte in deinem Fall eine neuere Version eines auslaufenden Produkts sein.
Überlege dir, ob es immer sinnvoll ist, Seiten mit Produkten zu löschen, die nicht mehr verkauft werden. Wenn sie keinen Wert mehr haben - klar, lösch sie. Aber vielleicht werden einige deiner Produkte zu Sammlerstücken, wenn sie ausverkauft sind? Wenn die Leute immer noch nach ihnen suchen, versuche, ihnen Informationen über das Produkt zu geben, die sie interessieren könnten. Das ist ein gutes Branding für dich, und beim nächsten Mal kaufen sie vielleicht bei dir. Generell gilt: Wenn du eine Seite für etwas hast, nach dem die Leute suchen, gib dein Bestes, um ihnen das zu geben, was sie brauchen.
Versuche außerdem herauszufinden, was genau deine Rankingverluste verursacht hat: Welche Seiten und Keywords sind gefallen? Hängt das wirklich mit den Seiten zusammen, die du gelöscht hast, oder ist etwas anderes passiert?
Ich hoffe, das hilft für den Moment! Bitte lass mich wissen, wenn du weitere Fragen hast.
In den letzten Tagen sind diese 5 Fehler aufgetreten, obwohl meine Website in Ordnung war und ich nichts an ihr verändert habe.
Die ersten 4 sagen, dass die Url nicht gefunden wurde und auf eine nicht existierende Seite verweist, die letzte sagt, dass Google diese Url aufgrund eines Problems nicht crawlen konnte.
Jede Hilfe zur Korrektur wäre sehr willkommen
1
fullscreen-page/comp-jbuvb96h/779897c6-9f10-4634-a89c-088088fda3b4/32/%3Fi%3D32%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/18/18
2
fullscreen-page/comp-jbuvb96h/097cd7ba-d2dd-4f27-b842-41fb9e4bce71/10/%3Fi%3D10%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/17/18
3
fullscreen-page/comp-jbuvb96h/51ce979e-13b2-4583-9922-0669fdf3009d/4/%3Fi%3D4%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/17/18
4
fullscreen-page/comp-jbuvb96h/c67a24e8-5266-4d0f-9da7-dbf04366a86e/21/%3Fi%3D21%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/17/18
1
_api/common-services/notification/invoke
405
1/20/18
Hallo George,
Vielen Dank für deinen Kommentar. Ich habe einen kurzen Blick auf deine Website geworfen und konnte nicht herausfinden, wo diese URLs generiert werden.
Wenn du eine Site-Suche für deine Website durchführst, wirst du feststellen, dass viele URLs im Google-Index stehen, die du dort nicht haben willst (einschließlich URLs wie die von dir genannten):
site:georgecoullpaintinganddecorating.co.uk
Deine Website hat nur eine URL, die gecrawlt und indiziert werden muss. Daher könnte es eine Lösung sein, das Crawling über deine robots.txt-Datei auf diese URL zu beschränken (ohne Ressourcen zu blockieren, die zum Rendern der Seite benötigt werden).
Ich hoffe, das führt dich in die richtige Richtung. Bitte lass mich wissen, wenn du weitere Fragen hast.
Hallo George! Hast du die Lösung für deine Fehler gefunden? Ich erhalte auch die gleichen Fehler. Bitte hilf mir. Ich vermute, es hat etwas mit Wix zu tun
Ich habe es als behoben markiert, aber es wird immer noch angezeigt und ich möchte es nicht umleiten.
Ich habe auch von meiner Website gelöscht, was soll ich jetzt tun?
Hallo Ankush,
Wenn du einen Fehler als behoben markierst und er wieder auftaucht, bedeutet das, dass Google erneut versucht hat, auf die URL zuzugreifen. Du kannst das ignorieren, wenn du willst, was in den meisten Fällen keine Probleme verursachen sollte. Du kannst auch den Statuscode der URL auf 410 ändern und hoffen, dass dies Google hilft, zu verstehen, dass die URL nicht wieder auftaucht und dass sie weniger oft versuchen, auf sie zuzugreifen.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Wir haben Tausende von 404-Fehlern mit Umleitungen behoben, aber nur aus Neugier: Ist es notwendig, die behobenen URLs in GWT zu markieren oder wird der Crawl-Fehlerbericht irgendwann automatisch aktualisiert?
Hallo Carey,
Soweit ich weiß, wird der Crawl-Fehlerbericht jedes Mal aktualisiert, wenn Google versucht, eine URL, die zuvor einen Fehler hatte, erneut zu crawlen, wenn der Fehler bis dahin verschwunden ist.
Umgeleitete URLs sollten mit der Zeit aus den Crawl-Fehlerberichten verschwinden.
Hallo Eoghan,
Kannst du dieses Problem lösen? Nicht verfolgter Link in der Google Search Console.
Dieser Link stammt von Feed Burner.
gibt es ein Beispiel:
2012/05/mark-twain-all-bangla-onobad-e-book-%E0%A6%AC%E0%A6%BE%E0%A6%82%E0%A6%B2%E0%A6%BE-%E0%A6%85%E0%A6%A8%E0%A7%81%E0%A6%AC%E0%A6%BE%E0%A6%A6-%E0%A6%87-%E0%A6%AC%E0%A7%81%E0%A6%95-%E0%A6%AE%E0%A6%BE/feed/
Hallo Anick,
Ich glaube, dass diese URLs in einem Link-Element in deinem Kopfbereich generiert werden.
Wenn du den Quellcode der Seite aufrufst https://allbanglaboi.com/2012/05/mark-twain-all-bangla-onobad-e-book-বাংলা-অনুবাদ-ই-বুক-মা/, findest du dieses Element in Zeile 48:
<link rel=”alternate” type=”application/rss+xml” title=”Allbanglaboi – Free Bangla Pdf Book, Bangla Book pdf, Free Bengali Books » Mark Twain All : Bangla Onobad E-Book ( বাংলা অনুবাদ ই বুক : মার্ক টয়েন এর গল্প সমগ্র ) Comments Feed” href=”https://allbanglaboi.com/2012/05/mark-twain-all-bangla-onobad-e-book-%e0%a6%ac%e0%a6%be%e0%a6%82%e0%a6%b2%e0%a6%be-%e0%a6%85%e0%a6%a8%e0%a7%81%e0%a6%ac%e0%a6%be%e0%a6%a6-%e0%a6%87-%e0%a6%ac%e0%a7%81%e0%a6%95-%e0%a6%ae%e0%a6%be/feed/” />
Die URL, die im href-Attribut verlinkt ist, gibt einen Redirect zurück, der nicht richtig aufgelöst wird, daher kommt der Fehler “not followed”.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Danke Eoghan für die Antwort, aber ich kann dieses Problem nicht lösen. In der Google-Suche werden 516 nicht verfolgte Links auf meiner Seite angezeigt.
Hallo Anick,
Es tut mir leid, dass meine Antwort dir nicht geholfen hat. Vielleicht kennst du einen Webentwickler, den du fragen könntest, wie du das Element, das die Fehler verursacht, aus deinem Quellcode entfernen kannst?
Hallo, Eoghan Henn, tolle Infos.
was genau ich von Google Webmaster bekomme
1 Serverfehler und 22 nicht gefunden für Desktop
0 Serverfehler und 2 nicht gefunden für Smartphone
Wie kann ich den Serverfehler beheben?
danke
Hallo Bablu,
Zuerst solltest du prüfen, ob der Serverfehler immer noch auftritt - oft sind sie nur vorübergehend. Wenn er immer noch auftritt, überprüfe, ob die URL wirklich funktionieren sollte. Wenn nicht, stelle sicher, dass du nicht auf sie verlinkst und leite sie um, wenn du kannst. Wenn sie funktionieren sollte, versuche herauszufinden, warum sie es nicht tut und behebe es.
Ohne zusätzliche Informationen kann ich dir nicht weiterhelfen, aber du kannst mir gerne weitere Details mitteilen (per E-Mail, wenn du magst).
Diese 22 Links auf Google Webmaster, wenn ich sie anklicke, werden sie alle auf 404 not found umgeleitet. Vor ein paar Tagen habe ich alle diese Links mit Yoast bearbeitet, um mein SEO zu verbessern. Ist das nicht das Ergebnis davon? und auch der Server 1-Fehler erscheint immer noch.
Hallo Bablu,
Es ist gut, dass du die Links, die auf die Fehler-URLs zeigen, bereits identifiziert und geändert hast. Jetzt solltest du, wenn möglich, die Fehler-URLs auf passende Ziele umleiten (dafür gibt es auch WordPress-Plugins). Dann kannst du die Fehler in der Google Search Console als behoben markieren und sie sollten nicht mehr zurückkommen.
Für den verbleibenden Serverfehler kannst du das Gleiche tun.
Ich hoffe, das hilft!
Wie werde ich die Crawl-Fehler bei Google Web Master los. Alle Crawl-Fehler beziehen sich auf Seiten, die gelöscht wurden, weil Produkte nicht mehr hergestellt werden.
Hallo Olive,
Wenn du Seiten löschst, weil Produkte nicht mehr verfügbar sind, hast du viele Möglichkeiten, von denen drei folgende sind:
1. Gib einfach 404-Fehler für die gelöschten URLs zurück, so wie du es im Moment machst. Das führt zu 404-Fehlern im GSC und wahrscheinlich auch bei einigen Nutzern, aber es wird nicht allzu viel Schaden anrichten, also ist es in Ordnung, wenn du nicht die Ressourcen hast, um eine andere Lösung einzurichten.
2. Finde ein passendes Produkt, auf das du die alte URL 301 umleiten kannst. Wenn du diese Option wählst, solltest du sicherstellen, dass das Produkt, auf das du die alte URL umleitest, ein guter und relevanter Ersatz für das eingestellte Produkt ist.
3. Gib für eingestellte Produkte einen 410-Fehler statt eines 404-Fehlers zurück. Dies ist ein stärkeres Signal, dass die URL absichtlich entfernt wurde und kann dazu führen, dass Google weniger versucht, sie erneut zu crawlen (obwohl dies nicht garantiert ist). In deinen Crawl-Fehlerberichten werden URLs mit einem 410-Fehlercode weiterhin als 404-Fehler angezeigt.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Update: 410-Fehler werden jetzt als 410-Fehler in der Google Search Console angezeigt und nicht mehr als 404-Fehler markiert.
Hallo, ich habe ein paar Fehler, die ich nicht beheben kann.
Zugang verweigert
https://cassies.com.au/feed/?attachment_id=3380
404-Fehler nicht sicher, was zu tun ist.
sitemap-tags.xml
Danke
Danny
Hallo Daniel,
Hier ist, was du tun kannst:
- Finde heraus, von wo aus die URLs verlinkt sind und entferne die Links.
- Wenn möglich, leite die URLs auf ein passendes Ziel um.
- Markiere die Fehler in der Google Search Console als behoben.
Ich hoffe, das hilft!
Hallo, ich konnte alle meine Fehler in der Google Search Console beheben.
danke.
Das freut mich zu hören! Danke für deinen Kommentar.
Hallo,
Meine Website bekommt 503 Fehler im WMT und alle nicht gefundenen Seiten werden auf die Hauptseite umgeleitet, so ist mein Skript konzipiert. Was soll ich mit den 503-Fehlern machen? Soll ich sie mit “fetch as” alle auf meine Hauptseite umleiten?
Dankeschön
Hallo Anthony,
503-Fehler werden oft durch ein vorübergehendes Problem verursacht (z. B. Serverüberlastung). Du solltest überprüfen, ob die Seiten, für die das GSC 503-Fehler anzeigt, ständig nicht erreichbar sind oder ob es sich wirklich nur um ein vorübergehendes Problem handelt. Wenn es sich um ein vorübergehendes Problem handelt, musst du eigentlich nichts an den URLs ändern, außer dafür zu sorgen, dass das Problem nicht wieder auftritt. Vielleicht brauchst du einen leistungsfähigeren Server?
Die andere Sache, die du erwähnst, nämlich dass alle 404-Fehlerseiten automatisch auf die Startseite umgeleitet werden, solltest du vielleicht überdenken. Die Startseite ist nicht immer das beste Weiterleitungsziel für URLs, die nicht mehr existieren.
Ich hoffe, das hilft!
Ich habe das Problem auf meiner Voxya-Website. Als ich SSL auf der Website hinzugefügt habe, zeigt der Webmaster das Problem mit der Serverkonnektivität (Zeitüberschreitung beim Verbinden, Verbindung verweigert, keine Antwort) und robots.txt (unerreichbar) an. Bitte hilf mir, wie ich dieses Problem lösen kann.
Hallo Akriti,
Es tut mir leid, von deinen Problemen zu hören! Hast du sichergestellt, dass alle deine http-URLs jetzt korrekt auf ihre https-Entsprechung umgeleitet werden? Hast du eine neue Google Search Console-Eigenschaft für deine https-Version eingerichtet?
Du kannst mir gerne weitere Informationen schicken und ich helfe dir gerne weiter.
Ich habe eine Frage zum Verhältnis zwischen dem angezeigten Diagramm und der Anzahl der Fehler, die darunter angezeigt werden. Wenn ich den Mauszeiger über das Diagramm bewege, zeigt es “36 Fehler” am 12. März an. Wenn ich mir die Liste der URLs ansehe, werden 5 URLs für dasselbe Datum angezeigt. Woher kommen die 36 Fehler, wenn nur 5 URLs aufgelistet sind?
Danke!
Hallo Kara! Die im Diagramm dargestellte Zahl ist die Gesamtzahl der Crawl-Fehler, die Google derzeit für deine Website anzeigt. Wenn du insgesamt 36 Fehler und 5 Fehler-URLs siehst, die am 12. März entdeckt wurden, sollte die Anzahl der Fehler, die im Diagramm für den 11. März angezeigt wird, 31 sein. Wenn sie höher ist, liegt das daran, dass einige Fehler noch am selben Tag entfernt wurden (was bedeutet, dass Google frühere Fehler-URLs am 12. März erneut gecrawlt und festgestellt hat, dass sie keine Fehler mehr liefern). Ich hoffe, das hilft! Bitte lass mich wissen, wenn du weitere Fragen hast.
Nachdem ich meine Website rekonstruiert habe, zeigt der Webmaster viele Crawl-Fehler für ältere URLs an. Kann ich sie auf neue URLs umleiten, nachdem ich sie als repariert markiert habe, und wird Google diese Umleitung berücksichtigen?
Hallo Afzal,
Google wird mit der Bearbeitung dieser Weiterleitungen beginnen, sobald es die URLs neu gecrawlt hat, was eine Weile dauern kann. Die Fehler sollten in deinen Berichten nicht mehr auftauchen.
Hallo Eoghan Henn!
Ich bin in Schwierigkeiten und erhalte eine Meldung von der Google-Konsole.
” Warnungen
URLs nicht zugänglich
Als wir eine Stichprobe der URLs aus deiner Sitemap getestet haben, haben wir festgestellt, dass einige URLs aufgrund eines HTTP-Statusfehlers für den Googlebot nicht zugänglich waren. Alle erreichbaren URLs werden trotzdem übermittelt.
1
Sitemap: urdutalkshows.org/sitemap_post.xml.gz
HTTP-Fehler: 404
URL: http://urdutalkshows.org/countries-facts/facts-about-Saudi-arabia.html”
Wie es dieses Problem behebt...!
Hallo Hafiz,
Um dieses Problem zu beheben, solltest du die URL mit dem 404-Fehlerstatuscode entfernen (http://urdutalkshows.org/countries-facts/facts-about-Saudi-arabia.html) aus der Sitemap (urdutalkshows.org/sitemap_post.xml.gz). Oder, wenn die URL http://urdutalkshows.org/countries-facts/facts-about-Saudi-arabia.html verfügbar sein sollte, stelle sicher, dass sie wieder funktioniert und keinen 404-Fehler zurückgibt.
Ich hoffe, das hilft!
Wie du gesagt hast, werden zuerst alle Fehler als behoben markiert. Meine Frage ist: Wenn mehr als 5000 Links nicht gefunden werden, wie kann ich sie als behoben markieren, da nur die ersten 1000 Links angezeigt werden? Gibt es eine Möglichkeit, alle 5000+ Links auf einmal als behoben zu markieren?
Es tut mir leid, aber ich kenne keine andere Möglichkeit, Crawl-Fehler als behoben zu markieren, als es 1000 für 1000 zu tun, sobald die nächsten 100 auftauchen. Selbst wenn du die API verwendest und es nicht manuell machst, musst du meines Wissens warten, bis die nächsten 1000 Fehler auftauchen.
Hallo Eoghan,
Ich habe diese Website vor kurzem auf einem völlig anderen Server neu gestaltet, nachdem sie gehackt wurde (0ld-Prestashop). Es gab mehr als 1000 Seiten und Google hat uns auf den Hack aufmerksam gemacht. Ich habe das Problem behoben und das Verzeichnis in den versteckten Dateien auf dem Server gefunden, den wir nicht mehr haben. Alle Dateien wurden für das neue Design neu erstellt (Wasserzeichen auf den Grafiken), da es sich um eine Schablonenseite handelt.
Wie werde ich die 404-Fehler als Folge des Hacks los? Ich habe die Seite innerhalb von 2 Tagen nach dem Hack repariert, aber einen Monat später werden die 404-Fehler immer noch angezeigt.
danke
Therese
Hallo Therese,
Es tut mir leid zu hören, dass deine Website gehackt wurde, aber es ist gut, dass du es so schnell wieder hinbekommen hast.
Google wird die gefälschten URLs wahrscheinlich immer wieder neu crawlen, und du hast drei Möglichkeiten, mit den 404-Fehlern umzugehen, von denen keine ideal ist:
1. Ignoriere sie einfach. Sie werden deiner SEO-Leistung wahrscheinlich nicht schaden. Der Nachteil ist, dass sie dir in den Crawl-Fehlerberichten in die Quere kommen.
2. Ändere die Statuscodes für alle gefälschten URLs auf 410. Sie werden weiterhin in den Fehlerberichten auftauchen, wenn sie gecrawlt werden, aber mit einem 410-Fehlercode besteht die Chance, dass Google sie weniger regelmäßig crawlt und schließlich aufhört, sie erneut zu crawlen.
3. Leite alle gefälschten URLs auf eine andere URL um, z. B. auf die Startseite. Normalerweise solltest du solche 301-Weiterleitungen nicht missbrauchen, aber ich vermute, dass es in deinem Fall eine Möglichkeit wäre, die URLs einfach aus deinen Crawl-Fehlerberichten verschwinden zu lassen. Du willst doch nicht ständig daran erinnert werden, dass deine Website gehackt wurde, oder?
Ich hoffe, das hilft dir. Bitte lass mich wissen, wenn du weitere Fragen hast.
Ein sehr informativer Beitrag, Sir. Ich hatte ein Problem mit dem Crawling meiner Website. Viele meiner Website-URLs sind plötzlich fehlerhaft. Die Url wurde durcheinander gebracht. Es gibt zwei Schrägstriche. Hier ein Beispiel:
https://modifmotor1.com/cover-bodi-samping-vario-125-techno-lama-warna-lengkap/cover-bodi-samping-vario-125-techno-lama-warna-putih/
https://modifmotor1.com/per-klep-racing-jepang-satria-fu/per-klep-jepang-satria-fu/
https://modifmotor1.com/rumah-roller-racing-honda-vario-110-ktc/pulley-set-roller-racing-honda-vario-110-ktc/
Bitte hilf mir. Es hat meine Website viele der Beiträge auf Seite 1, weg gemacht 🙁.
Vielen Dank im Voraus
Hallo Zhoel,
Es tut mir leid, ich bin nicht sicher, ob ich dein Problem verstehe. Deine Beispiel-URLs funktionieren. Kannst du mir ein paar zusätzliche Informationen schicken, damit ich versuchen kann, dir zu helfen?
Hallo, aus irgendeinem Grund habe ich regelmäßig 404-Fehler in der Suchkonsole, die ich behoben habe, aber es gibt noch viele weitere mit zufälligen URLs, die ich noch nie gesehen habe, wenn ich das Redirection Plugin einsetze. Weißt du, was das bedeuten könnte?
https://ezhangdoor.com
Danke!
Hallo Trey,
Werden die URLs nur in deinem Umleitungsplugin angezeigt oder auch im GSC?
Ich habe einige fehlerhafte Links von anderen Websites, die auf meine Website-Assets verweisen, für die ich nicht einmal 301 setzen kann, also frage ich mich, ob es sicher ist, alle 404 auf die Startseite umzuleiten, oder ob das schlecht ist.
Hallo Zahid,
Eine Reihe von URLs auf die Startseite umzuleiten, sollte immer die letzte Option sein. Kannst du nicht zumindest für einige der URLs bessere Weiterleitungsziele finden?
Was soll ich davon halten, wenn in diesem Bericht immer wieder URLs auftauchen, die früher einmal defekte URLs auf einer Website waren, aber inzwischen entfernt wurden? In einigen Fällen behauptet Google immer noch, dass ein “verlinkt von” auf die URL verweist, die ich überprüft habe und die es nicht enthält.
Das kommt häufig vor. Die Angabe “verlinkt von” sollte nicht als “aktuell verlinkt von” interpretiert werden, sondern eher als “einst verlinkt von (als wir diese URL zum ersten Mal fanden)”. Google wird alte, kaputte URLs von Zeit zu Zeit neu crawlen. Wenn du wirklich willst, dass das aufhört, kannst du die alten URLs auf passende Ziele umleiten. Ansonsten kannst du die Crawl-Fehler einfach ignorieren.
Hallo Eoghan!
Wir haben vor Kurzem eine E-Mail von Google erhalten, in der uns mitgeteilt wurde, dass wir eine Zunahme von “404”-Seiten haben, und als ich mich in unsere Google Search Console eingeloggt habe, habe ich gesehen, dass es sich dabei fast ausschließlich um Links zu Arzneimitteln handelt. Warum ist das so und was soll ich tun? Ich habe alle Passwörter geändert, für den Fall, dass wir gehackt wurden, aber ich habe keine Warnungen von WordFence erhalten.
Offenbar ist die Quelle des Links ein anderer Link auf unserer Website, der ebenfalls als 404 markiert ist. Wirklich verwirrend.
Vielen Dank für deine Hilfe!
Katie H.
Hallo Katie,
Entschuldigung für meine späte Antwort. Ich war in den letzten Wochen sehr beschäftigt. Das Problem, das du beschreibst, könnte in der Tat mit einer Art Website-Hack zusammenhängen. Wenn du mir ein paar zusätzliche Informationen schickst, schaue ich mir das Problem gerne genauer an, um herauszufinden, worum es sich handeln könnte.
Mit freundlichen Grüßen,
Eoghan
Hi,
Ich habe eine neue Domain über Shopify gekauft und den Laden eingerichtet. Plötzlich tauchten in der Suchkonsole einige seltsame Links auf, die wie 404-Fehler aussahen. Diese Links stammen von einer Website, die denselben Namen trug und früher jemand anderem gehörte. Als ich in der Wayback-Maschine nachschaute, war diese Website bis 2017 aktiv und es handelte sich um eine Art Weltnachrichten-Website. Mein Shop hat mit Mode zu tun und ich bekomme Links wie world news, archive567, tag/beyonce, car accidents, tag.christians, tag/campus etc. Es gibt keine Möglichkeit, sie umzuleiten. Ich habe diese Links gelöscht, als ob sie repariert wären, aber sie tauchen immer wieder auf. Ich möchte keine brandneue Website mit Spam-Links und Warnungen von Google starten. Bitte sag mir, wie ich damit umgehen kann und wie sie eine nicht ganz saubere Domain verkaufen können.
Dankeschön
Hallo Lana,
Danke, dass du diesen interessanten Fall mit uns teilst. Was hier passiert, ist völlig normal - Google kennt die alten URLs immer noch und versucht, sie von Zeit zu Zeit neu zu crawlen, um zu sehen, ob der alte Inhalt zurückgekommen ist. Das wird wahrscheinlich nie aufhören, es sei denn, du richtest 301-Weiterleitungen von diesen alten URLs zu neuen Zielen ein, die auch tatsächlich funktionieren. Eine andere Möglichkeit, die funktionieren könnte, wäre die Rückgabe eines 410-Codes anstelle eines 404-Codes. Das ist ein Signal für Google, dass der Inhalt absichtlich entfernt wurde, und Google wird die URLs vielleicht seltener erneut crawlen oder ganz aufhören, sie zu crawlen. Wenn Shopify selbst dir diese Optionen nicht bietet, gibt es sicherlich noch andere Möglichkeiten, dies zu tun. 301-Weiterleitungen lassen sich zum Beispiel ganz einfach einrichten, wenn du Zugang zu deiner .htaccess-Datei hast.
Ich hoffe, das hilft für den Moment!
Hallo Eoghan Henn!
Mein Name ist Samia und ich bin eine Bloggerin. Ich habe ein Problem mit dem Namen “Server Error”. Ich benutze das Newspaper 8 Theme und der Fehler ist ” /wp-content/themes/Newspaper/” Kannst du mir bitte sagen, wie ich ihn beheben kann?
Hallo Samia!
Vielen Dank für deinen Kommentar. Du solltest dir wegen dieses Fehlers nicht zu viele Sorgen machen. Vielleicht kannst du herausfinden, wie Google diese URL gefunden hat? Diese Diskussion könnte dir helfen: https://www.rebelytics.com/crawl-errors-google-search-console/#comment-11988
Bitte lass mich wissen, wenn ich noch etwas für dich tun kann.
Hallo Herr,
Ich versuche, meine Website zu crawlen https://wdsoft.in/ im Webmaster Tool, aber sie wird nicht erfolgreich gecrawlt, sondern ständig umgeleitet. Bitte hilf mir, wie ich meine Website als Google Fectch abrufen kann.
Ich hoffe, du hilfst mir.
Danke
Hallo Arun,
Auf den ersten Blick kann ich keine wichtigen Probleme erkennen. Verwendest du die richtige Eigenschaft? Wenn du in der http- oder www-Eigenschaft bist, werden alle URLs, die du abrufst, als umgeleitet angezeigt, obwohl deine Seite auf https und ohne www ist (und http- und www-URLs auf die richtigen Versionen umleiten).
Ich hoffe, das hilft dir! Wenn du noch weitere Fragen hast, lass es mich bitte einfach wissen.
Hallo Herr, ich habe etwas Seltsames auf meiner Website gefunden
Nur in 2 Tagen hat es 400 ++ Url Erros (nicht gefunden) wie du hier sehen kannst: http://prntscr.com/k36tc0
Und alle Fehler sind die gleichen, kannst du hier sehen: http://prntscr.com/k36ts4
Warum sollte der Google-Bot die Seite so weit weg crawlen? Ich verstehe wirklich nicht, warum.
Haben Sie eine Lösung für mein Problem, Sir?
Es sieht so aus, als hättest du etwas Seltsames mit der Paginierung am Laufen. Ich habe deine indizierten URLs schnell überprüft und es sieht so aus, als ob die meisten von ihnen mit /page/-number-/ enden. Wenn einige dieser URLs nicht mehr existieren, solltest du sicherstellen, dass du sie auf ein passendes Ziel umleitest, damit sie keine 404-Fehler auslösen.
Ich hoffe, das hilft!
Hi,
Ich verwende die WordPress Multisite-Plattform.
Bitte helfen Sie mir in Bezug auf 404 nicht gefundene Seitenfehler. Warum erhalte ich jeden Tag 404 Fehler? Ich habe bereits 300-400 Fehler behoben, aber ich erhalte immer noch neue 404 nicht gefundene Seitenfehler. Gibt es eine Möglichkeit, dieses Problem zu lösen?.
kannst du Folgendes überprüfen
https://prnt.sc/k9505f
https://prnt.sc/k951jw
Bitte hilf mir
Hallo Raman,
Tut mir leid, ich kann deine Screenshots gerade nicht aufrufen. Es heißt “Lightshot ist überlastet”. Wenn du magst, kannst du mir ein paar mehr Infos per E-Mail schicken und ich schaue sie mir an.
Ich habe gerade einen neuen Blog gestartet, aber der 404-Fehler kommt. Soll ich diese Art von Fehler also ignorieren?
Bitte helfen
https://newswoxen.com/ Das ist die Adresse der Website
Soft 404-Fehler solltest du nicht ignorieren! Ich empfehle, die Fehlerseiten zu überprüfen und herauszufinden, warum Google sie als Soft-404-Fehler ansieht (Infos oben: https://www.rebelytics.com/crawl-errors-google-search-console/#what-are-soft-404-errors). Ich hoffe, das hilft! Wenn nicht, lass es mich bitte wissen.
Hallo Eoghan,
seit ein paar Monaten habe ich ein großes Problem mit 404-Fehlern, die ich nicht lösen kann.
Das erkläre ich dir gleich.
Anscheinend gab es einen Fehler mit dem SSL-Zertifikat, der vom Hosting-Anbieter bestätigt wurde. Aus diesem Grund hat Google Links zu einer anderen Website verlinkt, die auf demselben Server liegt und dieselbe gemeinsame IP hat.
Dies hat dazu geführt, dass über 3000 gefälschte Links auf unsere Domain verlinkt wurden.
Die Serp ist komplett überflutet von diesen Links mit vielen Titeln und Metadeskriptionen. Wenn du darauf klickst, kommst du auf die Seite 404 unserer Website. Wenn du die einzelnen Links aus dem Serp untersuchst, zeigt der Cache von Google die Seiten in ihrem ursprünglichen Aussehen und mit ihrem ursprünglichen Link an.
Die Seite ist in keiner Weise beschädigt oder mit Malware infiziert.
Der Anbieter bestätigt, dass das Problem mit SSL behoben wurde.
Ich habe die 404-Fehler sofort als korrekt an die Search Console gemeldet, aber sie kommen wieder, ich melde sie fast jeden Tag, wenn ich es nicht tue, vermehren sie sich jeden Tag.
Obwohl diese Links noch nie auf unserer Seite waren.
Ich habe die Sitemap auch schon mehrmals verschickt, aber es ändert sich nichts.
Ich hoffe, ich habe mich klar ausgedrückt.
Hast du einen Rat?
Dankeschön
Hallo Woody,
Wenn du die Fehler einfach als behoben markierst, werden sie nicht behoben, sondern nur aus den Berichten entfernt. Wenn du willst, dass Google diese URLs nicht mehr crawlt, würde ich (in diesem Fall) empfehlen, sie umzuleiten. Da sie nie einen Inhalt hatten, wirst du wahrscheinlich kein passendes Ziel auf deiner Website finden, also kannst du sie einfach per 301-Weiterleitung auf deine Homepage umleiten. Das ist zwar keine besonders saubere Lösung (viele URLs auf die Startseite umzuleiten, würde ich normalerweise nicht empfehlen), aber es ist die einzige Möglichkeit, die mir in einem solchen Fall einfällt.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Hallo Eoghan,
Vielen Dank für deine Antwort.
Wäre es dann nicht besser, sie als 410 Fehler zu melden?
Vielleicht können wir auf diese Weise sogar die SERP unserer Seite aufräumen.
Der Fehler 410 weist auf gelöschte Inhalte hin, also ist das vielleicht eine sauberere Lösung als 301, meinst du nicht?
Danke
Hallo Herr,
Kannst du mir bitte helfen? Ich habe mit vielen 404 URLs zu kämpfen, die in Webmaster generiert werden.
Bitte überprüfe das Bild, da die meisten 25k+ 404 URLs in Webmaster generiert werden. Ich habe auch den Server-Support kontaktiert und die Website gescannt, aber sie haben nichts auf meiner WordPress-Website gefunden.
Ich weiß nicht, warum der Ordner ’info“ automatisch erstellt wird. Ich habe den gesamten Quellcode überprüft.
Bitte hilf mir, dieses Problem zu beheben.
https://prnt.sc/kcrvz9
Danke!,
Hallo! Hast du Informationen darüber, woher die URLs verlinkt sind? Das kannst du herausfinden, indem du auf jede URL klickst und dir den Reiter “verlinkt von” ansiehst. Ohne zusätzliche Informationen ist es schwierig für mich, dir zu helfen, aber du kannst dich gerne mit weiteren Informationen melden, damit ich mir das genauer ansehen kann.
Hallo Eoghan,
Vielen Dank, deine Umleitungsmethode hat bei mir wunderbar funktioniert. Ich hatte ein Problem mit 404-Fehlerseiten, wie du sagtest, können wir diese Probleme in Crawl-Fehlern finden, wo die Suchkonsole eine Registerkarte mit dem Namen “Verlinkt von” bereitstellt. Diese verlinkt von-Registerkarte enthielt meine alten Seiten derselben Website, die jetzt nicht mehr existieren und diese URLs waren von http://infusionarc.com und sie wurden indexiert, aber jetzt ist meine URL https://infusionarc.com. Also habe ich zunächst die Sitemap von meiner alten Domain, d.h. von “http”, erneut eingereicht und eine Umleitung auf die neue Domain, d.h. “https”, vorgenommen und erneut von “https” eingereicht. Jetzt werden in der Suchkonsole 0 Fehler angezeigt.
Danke!.
Das ist großartig! Danke, dass du diese Details mit uns teilst. Gute Arbeit!
Hallo, ich bekomme auch die gleichen Fehler wie George
https://www.ticklishblinks.in/fullscreen-page/comp-j7ephedi/2fd25b44-9622-11e7-bb53-12dd26dd586a/18/
Ich habe viele von ihnen. Bitte hilf mir!!!
Hallo Yogesh,
Das scheint ein Problem zu sein, das bei vielen Seiten auftritt, die mit Wix erstellt wurden.
Ich hatte noch nicht viel Zeit, mich damit zu befassen, aber das Blockieren des Verzeichnisses /fullscreen-page/ über deine robots.txt-Datei könnte helfen.
Wenn du weitere Fragen hast, während du weiter recherchierst, kannst du mir gerne Bescheid sagen.
Ich hoffe, das hilft für den Moment!
Hallo, ich habe den gleichen Fehler wie im oberen Kommentar, kann ihn aber nicht beheben.
Ich habe viele 404-Fehler-Url (gelöschter Beitrag)
https://ex.com/post_error_1 => Es ist verlinkt von https://ex.com/postx, /posty, /postz
https://ex.com/post_error_2 => gleich...
https://ex.com/post_error_3
https://ex.com/post_error_4
Alle Seiten, die von (postx, postx, postz...) verlinkt wurden, sind nicht mehr mit post_error_1 (oder post_error_2...) verlinkt, aber ich weiß nicht, warum Google immer noch Links anzeigt (anscheinend aktualisiert Google nicht).
Auf meiner Website werden alle 404-Fehler mit der alten URL gespeichert und geben einen 404-Code (nicht gefunden) zurück - nicht soft 404.
Soll ich also 301 alle error_post-Links umleiten auf https://ex.com/404 (mit 404-Code-Rückgabe) oder dieselbe alte Url behalten https://ex.com/post_error_1 mit 404 Return Code.
Dankeschön
Vielen Dank für deinen Kommentar.
Du hast Recht, Google aktualisiert die “verlinkt von”-Informationen normalerweise nicht. Sie zeigt dir an, wo Googles Crawler die URL ursprünglich gefunden hat. Es kann also passieren, dass die angezeigten Seiten nicht mehr existieren.
Es ist auch normal, dass Google 404-Seiten immer wieder crawlt, um zu prüfen, ob der Inhalt wiederhergestellt wurde. Wenn du magst, kannst du alles so lassen, wie es ist, und die Fehler ignorieren. Wenn es passende Umleitungsziele für die 404-Fehler-URLs gibt, ist es sinnvoll, sie umzuleiten. Auf diese Weise verschwinden sie aus deinen Fehlerberichten im GSC und Google wird wahrscheinlich auch aufhören, sie erneut zu crawlen. Eine andere Möglichkeit wäre, statt einer 404 eine 410-Fehlermeldung zurückzugeben. Das ist ein stärkeres Signal dafür, dass der Inhalt absichtlich entfernt wurde und kann dazu führen, dass Google die URLs seltener neu crawlt.
Ich hoffe, das hilft dir erst einmal! Bitte lass mich wissen, wenn du weitere Fragen hast.
Hi,
Vielen Dank für deinen Artikel. Wir sind eine Website mit Stellenangeboten. Die Stellenangebote auf unserer Website laufen nach einiger Zeit ab, so dass der Roboter viele “nicht gefundene” Seiten findet, weil sie natürlich ablaufen. Wie sollten wir in unserem Fall damit umgehen?
Hallo Sutirth,
Vielen Dank für deine interessante Frage. Ohne die Details deines Falls zu kennen, würde ich vorschlagen, einen 410-Fehlercode für abgelaufene Stellenanzeigen zurückzugeben. Die URLs werden weiterhin in deinen Fehlerberichten auftauchen, aber Google wird verstehen, dass der Inhalt absichtlich entfernt wurde und wird die URLs in Zukunft vielleicht weniger häufig neu crawlen.
Eine andere Möglichkeit wäre die Einrichtung von 310 Weiterleitungen, aber das würde ich nur empfehlen, wenn du passende Weiterleitungsziele hast, z. B. Jobs, die denen auf den alten URLs sehr ähnlich sind, was in der Praxis etwas schwierig einzurichten sein könnte.
Ich hoffe, das hilft dir. Bitte lass mich wissen, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Hallo, Sir, ich habe eine Fehlermeldung URL nicht gefunden, aber ich weiß nicht, wie ich mit einem solchen URL-Fehler umgehen soll, denn die URL ist wie folgt: https://www.todaystechlog.com/category/pc/post-type-1 OR category/pc/post-type-1. Ich habe also keine solche URL auf meiner Seite. Ich weiß nicht, wie eine solche URL auf meiner Seite erstellt wird, da ich meinen Permalink bereits auf den Musterbeitrag gesetzt habe. Ich werde also keine solche URL auf meiner Seite haben. Wie kann ich diese Art von URL-Fehler beheben? Ich verwende WordPress.
Hallo Akshay,
Es könnte eine URL sein, die irgendwann in der Vergangenheit existierte. Wenn es nur ein paar solcher Fehler gibt, kannst du sie einfach ignorieren oder die URLs auf ein passendes Ziel umleiten.
Wenn es ein größeres Problem gibt und Google immer wieder neue URLs findet, kannst du mir gerne mehr Informationen schicken und ich schaue mir das Problem an.
Hallo, ich sehe dies in meiner Google Search Console: Googlebot konnte diese Seite nicht aufrufen, weil der Server die Syntax der Googlebot-Anfrage nicht verstanden hat.
Dies ist eine neue Website, die erst in den letzten 2 Monaten eingerichtet wurde. Sie wird mit WordPress bei GoDaddy mit Cloudflare https gehostet.
Vielen Dank für deine Hilfe und dein Engagement.
Hallo Lori,
Vielen Dank für deine Nachricht. Für welche URL hast du diese Fehlermeldung erhalten? Wenn du sie mir hier oder per E-Mail schickst, schaue ich sie mir gerne an.
Meine Seite http://www.jhollowell.com Die Seite gibt eine 403 an Scanning-Tools/Googlebot zurück. Sie wird derzeit indiziert bei. Bing und Yahoo. Bitte helfen Sie uns in diesen Fällen.
Hallo Ola,
Zurzeit kann ich nicht auf deine Website zugreifen und erhalte diese Fehlermeldung:
Bandbreitenlimit überschritten
Der Server ist vorübergehend nicht in der Lage, deine Anfrage zu bearbeiten, da der Betreiber der Seite sein Bandbreitenlimit erreicht hat. Bitte versuche es später noch einmal.
Es sieht so aus, als ob du einige Serverprobleme hast, die behoben werden müssen. Sag mir Bescheid, wenn du das Problem behoben hast, damit ich mir ansehen kann, ob der 403-Fehler für Googlebot damit zusammenhängt oder ob es ein anderes Problem gibt.
Hallo, ich hoffe wirklich, dass du mir helfen kannst. Ich habe ein wirklich schlimmes Problem mit tausenden von mysteriösen 404-Fehlermeldungen, die jeden Tag auftauchen, anscheinend von einem Googlebot, der meine Seite durchsucht. Die Seite heißt positivemindworks.co. Die einzige Möglichkeit, meine Seite langfristig aktiv zu halten, besteht darin, den Zugriff auf die Seite für die gesamten USA zu sperren (mit dem Wordfence Country Blocker). Das hat natürlich schwerwiegende Folgen für mein SEO! Wenn ich die Sperre für einen Tag aufhebe, versuchen die Google-Bots, meine Seite zu crawlen, aber sie crawlen immer wieder zufällige dynamische mysteriöse 404-Seiten, die für mich überhaupt keinen Sinn ergeben. Nach ein paar Tagen stürzt dann mein Server ab. Wenn du in den USA wohnst, kann ich die Ländersperre für einen Tag aufheben, damit du dir die Seite anschauen kannst. Sag mir einfach Bescheid, wenn du sie dir ansehen willst, dann hebe ich sie sofort auf. Vielen Dank im Voraus!!!
Hallo Samantha,
Vielen Dank für deinen Kommentar. Ich wohne in Spanien, also ist es für mich kein Problem, deine Website zu überprüfen.
Es ist in der Tat keine gute Idee, alle US-amerikanischen IP-Adressen von deiner Website zu sperren. Du willst ja, dass Google deine Website crawlen kann.
Wenn ich überprüfe, welche Seiten auf deiner Domain derzeit von Google indexiert werden, sehe ich die Art von URLs, von denen du sprichst: Seite: Suche nach positivememindworks.co
Warst du schon immer im Besitz dieser Domain oder hast du sie von jemand anderem erworben? Wurde deine Website kürzlich gehackt?
Dein Server sollte normalerweise nicht wegen der Google-Anfragen abstürzen. Du solltest vielleicht über ein Upgrade deines Servers nachdenken. Du kannst auch versuchen, die Crawl-Rate von Google in der Google Search Console unter Website-Einstellungen > Crawl-Rate zu begrenzen.
Es ist wichtig, dass du zuerst eine Lösung findest, um die Ländersperre aufzuheben, ohne dass die Anfragen von Google deine Server zum Absturz bringen. Dann solltest du versuchen herauszufinden, warum diese Fehler-URLs erzeugt werden.
Abgesehen von den Lösungen, die im Artikel und in anderen Kommentaren beschrieben werden, könnte es eine gute Idee sein, die fraglichen URLs über die robots.txt-Datei zu blockieren.
Bitte lass es mich wissen, wenn du dabei Hilfe brauchst.
Hallo Eoghan! Ein sehr schöner Beitrag!
Ich habe eine Frage, kannst du mir helfen? WebMaster Tools zeigt mir 404-Fehler an, allerdings zeigt es abgeschnittene URLs. Manchmal fehlt ein großer Teil, manchmal nur ein Stückchen HTML.
Beispiel:
/corujinha-menina-lembrancinhas-e-imagens.h
/Centro-de-Mesa-Mario-Kart-Gr
Richtig müsste es heißen:
/corujinha-menina-lembrancinhas-e-imagens.html
/Centro-de-Mesa-Mario-Kart-Gratis.html
Hallo Pedro,
Danke für deinen Kommentar. Freut mich, dass dir der Artikel gefallen hat.
Es sieht so aus, als ob Google aus irgendeinem Grund versucht, auf diese abgeschnittenen URLs auf deiner Seite zuzugreifen. Die Fehler-URLs, die im Bericht angezeigt werden, sind die URLs, die Google tatsächlich versucht hat, zu crawlen.
Kannst du auf der Registerkarte “Verknüpft von” sehen, von wo aus diese URLs verlinkt sind? Und hast du viele Fehler-URLs dieser Art oder nur ein paar?
Ich hoffe, das hilft dir. Wenn du noch weitere Fragen hast, lass es mich bitte einfach wissen.
Hallo zusammen,
Ich habe etwa 8000 Seiten auf meiner Website. Sie enthält etwa 22000 nicht gefundene URLs. Aber wenn ich ihre Quelle, d.h. unseren internen Link, überprüfe, ist die nicht gefundene URL nirgendwo auf der Seite zu finden.
Mögliche Gründe für diese Fehler sind, dass ich angenommen habe:
1. Ich habe meine Themen-Taxonomie durch Tags ersetzt
2. Ich habe meine “Artikel”-Taxonomie durch die “Kategorie”-Taxonomie ersetzt.
3. Manchmal muss ich meine URLs aus verschiedenen Gründen sofort ändern, aber da meine Website häufig gecrawlt wird, wird sie sofort gecached. Also kommt auch diese URL unter die Kategorie “Nicht gefunden”.
4. Ich nehme an, dass dieses Problem nach dem “Core Algo Update” von Google am 18. April 2018 aufgetreten ist, das besagt, dass du die URL nicht ändern kannst. Gibt es eine Lösung für dieses Problem, wenn dies der einzige Grund ist?
Einige Abhilfen, die ich bereits durchgeführt habe
1. URLs aus der Webmaster-Option “URL entfernen” entfernt
2. Ich habe versucht, die oben genannten URLs auf die aktuelle URL umzuleiten, aber die Website stößt auf so viele Probleme, dass ich die Umleitung entfernt habe
Kannst du bitte eine Lösung für das Problem vorschlagen?
Hallo Rajat,
Wenn du URLs änderst, solltest du die alten URLs immer per 301-Weiterleitung auf die neuen umleiten. Das kann in deinem Fall zu vielen Weiterleitungen führen, aber der Effekt ist es definitiv wert.
Um die bestehenden 404-Fehler zu bereinigen, empfehle ich dir, die Fehler-URLs auf ihre neue Entsprechung umzuleiten. Achte in Zukunft darauf, dass du bei URL-Änderungen immer sofort 301-Weiterleitungen einrichtest.
Vielleicht findest du auch Lösungen, damit du die URLs in Zukunft nicht mehr so oft ändern musst. URLs sollten nur geändert werden, wenn es absolut notwendig ist.
Ich hoffe, das hilft!
Hey Henn, ich würde mich freuen, wenn du ein paar Einblicke oder Hilfe geben könntest
Ich benutze das pressive Theme von thrive theme und thrive architect
Mein Problem ist, dass ich in der Google-Konsole Tausende von internen Links habe, während ich 2 oder 3 Verlinkungen für jeden Beitrag habe und ich habe 50 Beiträge
Tausende von ihnen haben dieses Format http://prntscr.com/ktqz53
jeder Beitrag hat 100er, die zu jedem von ihnen gelangen http://prntscr.com/ktqzpw
Alle meine Bilder werden über html hinzugefügt und meine xml-Sitemap hat nur Seiten und Beiträge
Wie kann ich dieses Zeug bereinigen? Meine Rankings sind gesunken und ich denke, dass dies eine der Ursachen sein könnte.
Hallo Sammy,
Wenn ich mir die Screenshots deiner Fehler-URLs ansehe, frage ich mich, ob dein Problem mit dem Yoast-Bilderanhänge-Fehler von Anfang des Jahres zusammenhängt. Bitte prüfe dieser Beitrag auf der Yoast-Website und lass mich wissen, ob es hilft. Wenn es nicht hilft, kann ich mir dein Problem gerne noch einmal ansehen.
Hallo Eoghan,
Toller Artikel > Dankeschön
Kürzlich hatte ich ein Problem mit einem Yoast-Update, das dazu führte, dass Google und die anderen großen Suchmaschinen jedes Bild als eigene URL-Seite indizieren. Ich habe das Yoast Purge Plugin installiert.
Aber ich erhalte auch jetzt, Monate später, noch URL 404 Crawl-Fehler.
Wird das früher oder später verschwinden oder muss ich andere manuelle Maßnahmen ergreifen?.
Danke Darren
Hallo Darren,
Vielen Dank für deinen Kommentar. Ich freue mich, dass dir der Artikel gefallen hat.
Das Yoast Purge-Plugin setzt einen 410-Statuscode (statt 404) für alle Anhang-URLs. Du kannst in deinen Fehlerberichten nachsehen, ob die URLs 404 oder 410 Fehler haben. Du kannst die Statuscodes auch mit einem Tool wie https://httpstatus.io. Wenn es 410 Fehler sind, ist alles in Ordnung. Du brauchst nur etwas Geduld, bis sie alle verschwinden. Wenn du immer noch 404-Fehler siehst, funktioniert entweder etwas mit dem Purge-Plugin nicht, oder die Fehler wurden durch ein anderes Problem verursacht.
Ich hoffe, das hilft für den Moment. Wenn du weitere Fragen hast, lass es mich einfach wissen.
Hallo Eoghan,
Ich habe oben einige Kommentare über das Yoast-Plugin gelesen, aber nichts, was sich auf mein Problem bezieht. Ich stelle fest, dass die Yoast-Tags in der Google Search Console als weiche 404-Fehler angezeigt werden. Weißt du, wie ich Yoast weiterhin ohne diese Fehler nutzen kann?
Danke!
Hallo CL,
Schöne Website, das Design gefällt mir sehr.
Tags sind kein Yoast-Feature, sondern ein Standard-WP-Feature, und es sieht so aus, als hättest du einige von ihnen irgendwann in der Vergangenheit deaktiviert (gute Idee). Einige deiner alten Tag-URLs geben jetzt 404-Fehler zurück. Auf der 404-Fehlerseite gibt es Links zu anderen Tags (ganz unten), die einen 200-Statuscode zurückgeben, aber keinen Inhalt haben. Diese werden in deinen Crawl-Fehlerberichten als Soft-404-Fehler angezeigt.
Ich würde Folgendes tun: Deaktiviere alle Tags in WordPress, entferne die Links von der 404-Fehlerseite und stelle sicher, dass alle Tag-URLs 404-Fehler zurückgeben.
Ich hoffe, das hilft dir erst einmal! Bitte lass mich wissen, wenn du weitere Fragen hast.
Hallo Eoghan,
Das ist ein sehr hilfreicher Artikel. Früher bekamen wir immer wieder 404-Fehler aufgrund von Javascript und haben uns den Kopf zerbrochen, um herauszufinden, was mit der Website los ist, und haben dann einen manuellen Crawl beantragt. Wir werden diese Seite weiterhin besuchen, wenn solche Fehler wieder auftauchen. Danke für diesen Beitrag.
Wenn diese Fehler immer wieder auftauchen oder sich häufen, lohnt es sich zu prüfen, woher sie kommen und sie zu beheben. Wenn es sich nur um einen gelegentlichen Fehler dieser Art handelt, wird er wahrscheinlich keinen Schaden anrichten.
Hallo Eoghan,
Danke für den Artikel, er ist wirklich hilfreich, während wir versuchen, herauszufinden, was auf unserer Seite passiert. Wir haben Tausende von minderwertigen Beiträgen auf unserer WordPress-Seite identifiziert und sie von der Seite gelöscht. Wir haben alle internen Links, die auf diese Seiten verweisen, aktualisiert, sodass sie nicht mehr verlinkt werden. Aber seit diesen Änderungen sehen wir in der Google Search Console, dass die Zahl der Fehler, die nicht gefunden wurden, dramatisch gestiegen ist. Wir haben einen großen Teil dieser URLs mit 301 umgeleitet, aber einige haben wir einfach als 404 belassen, da Google in vielen Fällen erwähnt hat, dass dies kein Problem sein sollte. Was mich beunruhigt, ist, dass diese URLs immer noch in den Berichten über nicht gefundene Fehler auftauchen. Außerdem werden ‘verknüpfte von’-URLs angezeigt, die entweder nicht mehr existieren oder zwar existieren, aber es gibt keine URL zur Fehlerseite. Es sieht so aus, als ob Google eine gecachte Version unserer Website crawlt oder einen Schnappschuss von vor 2-3 Monaten hat, anstatt die aktuellen Crawl-Fehler anzuzeigen. Wir können nicht herausfinden, wo/wie Google diese URLs anzeigt. Irgendwelche Vorschläge?
Vielen Dank!,
BJ
Hallo BJ,
Was du siehst, ist ein normales Verhalten von Google. Bekannte URLs werden regelmäßig neu gecrawlt, auch wenn sie keine internen Links mehr haben, die auf sie zeigen, und wenn sie einen 404-Fehler zurückgeben. Der Reiter “Verlinkt von” im GSC zeigt, wo Google eine URL entdeckt hat, aber die Links werden normalerweise nicht aus dem Bericht entfernt, wenn sie nicht mehr existieren.
Die einzige Möglichkeit, Google davon abzuhalten, deine alten URLs erneut zu crawlen, ist, sie auf ein passendes Ziel umzuleiten. Wenn es dir gelingt, ein gutes Weiterleitungsziel für alle alten URLs zu finden, die du entfernt hast, würde ich dir das empfehlen.
Wenn es nicht möglich ist, alle alten URLs umzuleiten, kannst du auch erwägen, den Statuscode der entfernten URLs von 404 auf 410 zu ändern. Ein 410-Statuscode signalisiert, dass der Inhalt absichtlich entfernt wurde, und Google wird diese URLs in Zukunft wahrscheinlich seltener neu crawlen und schließlich aufhören, sie seltener neu zu crawlen.
Ich hoffe, das hilft dir! Bitte lass mich wissen, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Warum werden irrelevante Crawl-Fehler nicht mehr angezeigt, wenn ich alles als behoben markiere? Ich denke, es ist besser, wenn ich alle kritischen Fehler gleich beim ersten Mal erkenne und sie sofort beheben kann. Eine Woche ist vielleicht zu lang, um Maßnahmen zu ergreifen.
Hallo Lina,
Ja, du hast Recht! Wenn du in der Lage bist, alle Fehler sofort zu analysieren, dann ist das die beste Lösung. Wenn es aber viele Daten gibt und du dich zuerst auf die wichtigsten Fehler konzentrieren willst, ist es eine gute Idee, alles als behoben zu markieren, denn so kannst du bei Null anfangen und nur die Probleme angehen, auf die Googles Bots vor kurzem gestoßen sind (die, die wieder auftauchen).
Bitte hilf mir, wie kann ich das beheben 🙁.
URL Zuletzt gecrawlt
01 Sep 2018
Letztes Crawl-Ergebnis
Gesperrte Domain oder IP
Hallo John,
Dies ist eine Fehlermeldung von Majestic und nicht von der Google Search Console, richtig? Ich helfe dir gerne, wenn du mir mehr Informationen schickst.
Hallo Eoghan Henn,
Ich habe deinen ganzen Artikel gelesen. Er ist wirklich informativ und gut erklärt. Meine Website hat tausende von 404-Fehlern in den Webmasters Tools. Das Problem ist, dass es keine verlinkten Seitendetails gibt. Alle 404-Fehlerseiten waren doppelt kodiert. Zum Beispiel habe ich die Seiten mit dem Symbol “/” in im URL-Parameter verschlüsselt. Aber Google zeigt 404-Seiten mit “2F” an (Google hat das %-Symbol wieder in umgewandelt). Wie kann ich mit dieser Art von Fehlern umgehen? Irgendeine Idee? Meine Website-Adresse lautet https://sapstack.com und die problematischen Seiten stammen aus dem Abschnitt https://sapstack.com/tables
Hallo Syam,
Es tut mir leid, von deinem Problem mit der URL-Kodierung zu hören. Ich habe mir die URLs aus deinem /tables/-Verzeichnis angesehen, die derzeit von Google indiziert werden, und konnte keine Beispiele für Fehler-URLs finden - das ist ein gutes Zeichen. Kannst du aus den Crawl-Fehlerberichten ersehen, wann diese Art von Fehler zum ersten Mal entdeckt wurde? Vielleicht gab es ein vorübergehendes Problem mit deiner URL-Kodierung, das die Fehler verursacht hat. Wenn Google die falschen URLs immer noch crawlt, kannst du vielleicht Umleitungsregeln einrichten, die den Bot zur richtigen Version der jeweiligen URL zurückschicken.
Wenn du mir ein paar genauere Informationen per E-Mail schickst, schaue ich mir das gerne genauer an.
Hallo Eoghan,
Sehr schöner Artikel. Du hast fast jedes mögliche Szenario abgedeckt, außer dem, mit dem ich jetzt konfrontiert bin 🙁.
Ich sehe ein merkwürdiges Problem bei einigen Websites, die aus irgendeinem Grund meine Seite crawlen und indexieren wollen, insbesondere Google Webmasters und Bing Webmasters.
Das Problem ist, dass sie den Screenshot meiner Website nicht als Vorschaubild anzeigen können! (aber bei einigen Diensten wie gtmetrix ist das in Ordnung)
Hier ist die Website: https://profile.center/
Wir haben alles in unseren Codes überprüft und nichts gefunden...
Kannst du mir helfen, den Grund dafür zu verstehen?
Das Beste,
Shahram
Hallo Shahram,
Vielen Dank für deinen Kommentar. Könntest du mir bitte einige zusätzliche Informationen schicken, damit ich deine Frage besser verstehen kann? Auf welche Vorschaubilder beziehst du dich?
Hallo Eoghan,
Hast du schon einmal Smartphone-Crawl-Fehler wie diesen hier gesehen?
size/x-large/page/2/%3Ca%20href=
I have hundreds of links with %3Ca%20href= appended to regular links.
Hallo Nicolina,
Thank you for your question. “%3Ca%20href=” is “<a href=”, percent encoded.
Für mich sieht das nach einem Problem mit fehlerhaften internen Links aus. Wahrscheinlich liegt ein Fehler in einem der Links in deiner Seitenvorlage vor, der “<a href=” an die URLs interner Links anhängt oder der einfach auf “<a href=” als relativen Link verweist.
Du kannst diesen Fehler finden, indem du den Quellcode deiner Seite inspizierst oder deine Website mit einem Tool wie Screaming Frog crawlt. Du kannst mir auch die URL deiner Website per E-Mail schicken und ich schaue sie mir an, wenn du möchtest.
Hallo Eoghan,
Ich habe ein ähnliches Problem, das die meisten Leute hier kommentieren, nämlich 404 Crawl-Fehler in GWT... bitte überprüfe diesen Snap https://prnt.sc/lxrgd8...dies ist ein Schnappschuss von GWT mit allen Fehlern darin....
Ich habe ein paar Monate lang versucht, sie zu beheben, indem ich die Option ‘Als behoben markieren’ aktiviert habe... aber diese Crawl-Fehler werden fast jeden Tag generiert... ich habe keine Ahnung, woher diese URLs generiert werden....
Ich habe fast alle Plugins deaktiviert... damit keine Probleme durch Plugins entstehen...
Außerdem macht es keinen Sinn, 301-Weiterleitungen zu machen, da diese URLs nicht von den Inhalten der Website stammen und ich nicht aufhören kann, 301-Weiterleitungen zu machen, da die URLs jeden Tag generiert werden...
Kein ‘LINKED FROM’ Tab in GWT gefunden...
Was ist zu tun? Woher kommen diese URLs? Ich habe meine Seite auf Malware geprüft und kein negatives Ergebnis gefunden... Kannst du mir helfen? ????
Bitte gib mir so schnell wie möglich eine Antwort, denn es macht mir große Sorgen.
Danke!.
Brett Ander
Hallo Brett,
Das sieht in der Tat seltsam aus. Eine Sache, die du beachten solltest, ist, dass du die Fehler nicht wirklich behebst, wenn du sie als behoben markierst. Du lässt die URLs nur aus dem Bericht verschwinden, bis sie erneut gecrawlt werden.
Das sieht für mich nach einer Art Malware-Problem aus. Wenn du magst, kannst du mir die URL deiner Website per E-Mail schicken und ich werde mir das genauer ansehen.
Hi,
Dieser Blog sieht toll aus. Was ist, wenn ich eine Fehlermeldung erhalte, wenn ich versuche, den Blog in der Search Console abzurufen und darzustellen? Kann mir jemand helfen? Wie kann ich das beheben?
Hallo Akshay,
Was genau besagt die Fehlermeldung? Wenn er einfach besagt, dass die URL umgeleitet wird, solltest du für das Umleitungsziel fetch und render durchführen. Wenn es sich zum Beispiel um eine Weiterleitung von http zu https handelt, musst du vielleicht die Eigenschaften ändern. Wenn es ein tatsächliches Problem mit der Umleitung gibt (z. B. eine Umleitungsschleife), solltest du das zuerst beheben.
Wenn du mehr über den Fehler wissen möchtest, helfe ich dir gerne weiter.
Hallo Eoghan, danke für deinen nützlichen Beitrag.
Ich habe einen enormen Anstieg von 404-Fehlern auf meiner Website.
Seit ein paar Tagen crawlt der Googlebot (Smartphone) etwa 10k/Tag gefälschte URLs.
URLs sind wie:
- /ebook-murray-lawn-mower-download-pdf.pdf
- /kim-leidenschaft.pdf
- /leddy-may-other-poems.pdf
- /ebook-minutes-of-stated-meetings-download-pdf.pdf
und so weiter... Ich hatte diese Dateien nie auf meiner Website.
Das Seltsame ist, dass Google bei den oben genannten URLs die Linkquelle nicht meldet.
Bei allen anderen “normalen” 404-Fehlern meldet Google die Linkquelle, sowohl intern (z. B. Sitemap oder Site-Seite) als auch extern (externe Site-Seite, die auf meine verlinkt).
Ich habe in allen Website-Dateien (auch Cache-Dateien), Datenbanken usw. nach den URLs gesucht. Sie stimmen in keiner Weise überein.
Hat jemand dasselbe Verhalten?
Hallo Franco,
Das sieht übel aus! Wenn du eine Site: Suche für deine Domain bei Google durchführst, kannst du sehen, dass Tausende von URLs (hauptsächlich PDFs) indexiert sind, die dort nicht hingehören. Sie alle geben 404-Fehler zurück und scheinen zum Zeitpunkt des Crawlens einen zufälligen Inhalt gehabt zu haben.
Ich habe in der Vergangenheit schon ähnliche Fälle auf Websites gesehen, die gehackt wurden. Hattest du in der Vergangenheit auch solche Probleme?
Hallo Eghan Henn.
Ich habe viele Beiträge, Kategorien, Seiten und Tags in meinem Wordpress gelöscht.
Jetzt gebe ich 404-Fehler-URLs in meinem Webmaster an, Crawl-Fehler.
Bitte sag mir, wie ich es Schritt für Schritt reparieren kann?
Hallo Milad,
Klar, hier sind die Schritte:
1. 404 Fehler exportieren.
2. Finde ein passendes Umleitungsziel für jedes einzelne von ihnen.
3. Richte Weiterleitungen ein (nur für URLs, die ein passendes Ziel haben).
Ich hoffe, das hilft!
Hallo Eoghan,
Danke für diesen Artikel. Ich habe eine Frage zu SPA (Single Page Applications). Ich erhalte derzeit einen Soft 404, da ich Angular auf meiner Website verwende, um Inhalte dynamisch anzuzeigen. Ich nehme an, dass dies der Grund ist, warum ich diese Fehlermeldung erhalte und warum die Suchmaschinen meine Seite nicht crawlen. Gibt es eine Strategie, um dieses Problem bei SPAs zu lösen?
Hallo Will,
Leider gibt es keine einfache Antwort auf deine Frage, denn SEO für SPAs / JS-Frameworks ist ein komplexes Thema, aber hier sind ein paar Dinge, mit denen du anfangen kannst:
- Stelle sicher, dass jede Seite deiner Website eine eigene URL hat (ohne URL-Fragmente zu verwenden).
- Stelle sicher, dass Google jede Seite deiner Website darstellen kann.
- Ziehe das serverseitige Rendering als Option in Betracht.
Die neuesten Versionen von Angular haben mehrere SEO-freundliche Lösungen.
Ich hoffe, das hilft für den Moment!
Hallo Eoghan,
Ich arbeite an einer Website, die JavaScript in der Meta-Beschreibung in Bing/Yahoo anzeigt. Aus irgendeinem Grund zeigt die Homepage der Website weder den Titel noch die Meta-Beschreibung in Google an.
Ich kann dir die URL gerne unter vier Augen mitteilen.
Danke
Sam
Hallo Sam,
Ich schicke dir eine E-Mail, damit du mir mehr Informationen zukommen lassen kannst.
Hallo
Ich arbeite mit WordPress. Das Elementor Plugin und Yoast SEO sind vorhanden. Wenn ich eine Seite erstelle, füge ich einfach einen Titel hinzu. Und die URL wird mit diesem Titel erstellt. Aber nachdem ich alle SEO-Informationen aktualisiert habe, gibt es eine neue URL. Aber die Suchkonsole crawlt mit der alten URL und es wird ein 404-Fehler angezeigt.
Beispiel:
1. Vor der Aktualisierung der SEO-Informationen URL: http://healthgeekss.com/health/services/weight-loss/wl-sideeffects/
2. Nach der Aktualisierung der SEO-Informationen URL: http://healthgeekss.com/health/services/weight-loss/side-effects-of-rapid-weight-loss/
Google crawlt nach der ersten. Statt der 2. gibt es im Blog eine 2. aktualisierte URL. Wie kann man das Problem lösen?.
Bitte hilf mir.
Hallo Shikha,
Vielen Dank für deine Frage.
Eine schnelle Lösung wäre es, eine 301-Weiterleitung von der alten URL zur neuen URL einzurichten. Damit wäre zumindest das 404-Fehlerproblem behoben.
Du kannst dann auch überprüfen, ob es interne Links, Sitemap-Einträge oder Ähnliches gibt, die auf die alte URL zeigen. Wenn ja, sollten sie aktualisiert werden.
Vielleicht kannst du das Problem beheben, indem du sicherstellst, dass du keine Artikel oder Seiten veröffentlichst, bevor du die endgültige URL festgelegt hast.
Ich hoffe, das hilft für den Moment. Bitte lass mich wissen, wenn du weitere Fragen hast.
Mit freundlichen Grüßen,
Eoghan
Hallo! Google kann unsere Homepage-Url nicht indexieren https://wineshoplouisville.com/ und zeigt in der Search Console einen Crawl Anomaly-Fehler an. Wenn ich den Seitenquelltext in Chrome inspiziere und auf die Registerkarte "Netzwerk" klicke, zeigt sie einen Ladevorgang von 3,19 Sekunden mit 404-Fehlern bei zwei Elementen (header_bg.gif und title_bg.png) und einem 500-Fehler bei http://www.wineshoplouisville.com dokument. Es scheint jedoch, dass Google alle anderen URLs auf unserer Website erfasst hat. Ich bin weder Entwickler noch kenne ich mich mit WordPress aus (wir verwenden das All in One SEO Plugin). Könnte das ein Problem mit dem Homepage-Bilderkarussell oder einem anderen Plugin sein? Oder ist es etwas ganz anderes? (Ein paar Randbemerkungen: Diese Seite wurde vor einiger Zeit erstellt und verwendet php5.6. Soweit ich weiß, kann sie nicht ohne großen Aufwand auf php7 aktualisiert werden. Wir haben vor kurzem den Hosting-Anbieter gewechselt und unsere WordPress-Version wurde dabei aktualisiert und ein SSL installiert. Der Hosting-Anbieter versichert uns, dass die Weiterleitungen richtig eingerichtet sind und es keine serverseitigen Probleme gibt). Vielen Dank im Voraus für eure Ideen!
Hallo Shelby,
Ich habe deine Homepage überprüft und sie gibt tatsächlich einen 500-Fehler zurück, obwohl sie einwandfrei funktioniert. Dieser Statuscode ist das Problem, um das du dich zuerst kümmern solltest - um die 404-Fehler bei den Bilddateien kannst du dich später kümmern, da sie nicht der Grund für deine Indexierungsprobleme sind.
Deine Homepage sollte einen 200er Statuscode zurückgeben. Google wird eine Seite wahrscheinlich nicht indexieren, solange sie einen Serverfehler zurückgibt, auch wenn sie im Browser perfekt dargestellt wird.
Ich bin mir nicht sicher, was die Ursache für dieses Problem ist, aber es könnte eine gute Idee sein, deine Plugins nacheinander zu deaktivieren, um zu prüfen, ob eines von ihnen die Ursache sein könnte.
Ich hoffe, das hilft für den Moment!
Mit freundlichen Grüßen,
Eoghan
Hallo, danke für diese hilfreiche Anleitung. Leider bin ich immer noch verwirrt über die Fehler, die in meiner Google Search Console angezeigt werden. Ich glaube, das ist passiert, nachdem ich im Dezember die URLs verschoben habe. Ich habe jetzt 31 Fehlermeldungen, die einfach besagen: "Submitted URL has crawl issue" (Übermittelte URL hat ein Crawl-Problem). Viele der Links sind zu Medienelementen, die ich in meine Mediathek hochgeladen habe, von denen einige nie benutzt oder seitdem gelöscht wurden. Andere auf Seiten, die in Ordnung zu sein scheinen. Ich habe bereits am 6. März auf "Alles validieren" gedrückt und jetzt, am 20. April, steht immer noch "Pending". Ich bin mir nicht sicher, was ich tun soll, aber ich weiß, dass mein Google-Rating enorm gesunken ist. Im Dezember hatte meine alte Seite fast 250 Google-Treffer pro Tag, jetzt sind es nur noch 2. Ich weiß nicht, was ich jetzt tun soll.
Hallo Jade,
Wenn du deine URLs im letzten Jahr geändert hast, solltest du sicherstellen, dass alle alten URLs, die jemals auf deiner Website existierten, jetzt auf funktionierende URLs umgeleitet werden, die denselben oder einen ähnlichen Inhalt wie die alten URLs haben.
Die meisten Crawl-Fehler sind wahrscheinlich nichts, worüber du dir Sorgen machen musst. Wenn du den Großteil deines organischen Suchverkehrs verloren hast, gibt es dafür wahrscheinlich andere Gründe, auch wenn die Crawl-Fehler mit einigen davon zusammenhängen könnten.
Bitte lass mich wissen, wenn ich dir irgendwie helfen kann.
Hallo... Danke für die Informationen... Das ist die Mail, die ich vor ein paar Tagen von Google bekommen habe
“Search Console hat festgestellt, dass deine Website von 2 neuen Coverage-bezogenen Problemen betroffen ist. Das bedeutet, dass die Reichweite in den Google-Suchergebnissen negativ beeinflusst werden kann. Wir empfehlen dir, diese Probleme zu beheben.
Die wichtigsten neu gefundenen Probleme, geordnet nach Anzahl der betroffenen Seiten:
Übermittelte URL nicht gefunden (404)
Umleitungsfehler”
Bitte, was soll ich tun???
Bitte beachte, dass sich dieser Artikel mit Berichten aus der alten Google Search Console befasst, die es nicht mehr gibt, und deine Fragen sich auf Fehler aus der neuen Google Search Console beziehen.
Bei der Fehlermeldung “Submitted URL not found (404)” kannst du den beschriebenen Ratschlägen für 404-Fehler folgen über.
Der Redirect-Fehler bedeutet normalerweise, dass eine URL umgeleitet wird, aber die Umleitung nicht zu einem funktionierenden Ziel führt. Du kannst überprüfen, ob es eine Umleitungsschleife oder ein ähnliches Problem gibt.
Ich hoffe, das hilft dir. Bitte lass mich wissen, wenn du weitere Fragen hast.