

Has this happened to you? You check the “Crawl Errors” report in Google Search Console (formerly known as Webmaster Tools) and you see so many crawl errors that you don’t know where to start. Loads of 404s, 500s, “Soft 404s”, 400s, and many more… Here’s how I deal with big amounts of crawl errors.
Important note: This article is out of date, as it deals with error reports from the old Google Search Console, which no longer exist. Comments are closed.
This guide was first published on rebelytics.com in 2015 and has since then been updated several times and moved to this blog.
Contents
Here’s an overview of what you will find in this article:
- Don’t panic!
- First, mark all crawl errors as fixed
- Check your crawl errors report once a week
- The classic 404 crawl error
- 404 errors caused by faulty links from other websites
- 404 errors caused by faulty internal links or sitemap entries
- 404 errors caused by Google crawling JavaScript and messing it up 😉
- Mystery 404 errors
- What are “Soft 404” errors?
- What to do with 500 server errors?
- Other crawl errors: 400, 503, etc.
- List of all crawl errors I have encountered in “real life”
- Crawl error peak after a website migration
- Summary
So let’s get started. First of all:
Don’t panic!
Crawl errors are something you normally can’t avoid and they don’t necessarily have an immediate negative effect on your SEO performance. Nevertheless, they are a problem you should tackle. Having a low amount of crawl errors in Search Console is a positive signal for Google, as it reflects a good overall website health. Also, if the Google bot encounters less crawl errors on your page, users are less likely to see website and server errors.
First, mark all crawl errors as fixed
This may seem like a stupid piece of advice at first, but it will actually help you tackle your crawl errors in a more structured way. When you first look at your crawl errors report, you might see hundreds and thousands of crawl errors from way back when. It will be very hard for you to find your way through these long lists of errors.
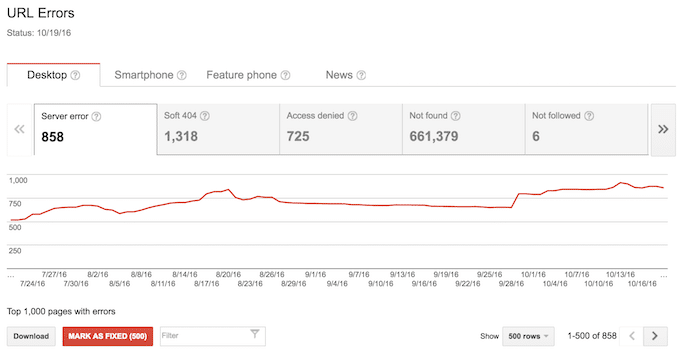
Does this screenshot make you feel better? I bet you’re better off than this webmaster 😉
My approach is to mark everything as fixed and then start from scrap: Irrelevant crawl errors will not show up again and the ones that really need fixing will soon be back in your report. So, after you have cleaned up your report, here is how to proceed:
Check your crawl errors report once a week
Pick a fixed day every week and go to your crawl errors report. Now you will find a manageable amount of crawl errors. As they weren’t there the week before, you will know that they have recently been encountered by the Google bot. Here’s how to deal with what you find in your crawl errors report once a week:
The classic 404 crawl error
This is probably the most common crawl error across websites and also the easiest to fix. For every 404 error the Google bot encounters, Google lets you know where it is linked from: Another website, another URL on your website, or your sitemaps. Just click on a crawl error in the report and a lightbox like this will open:
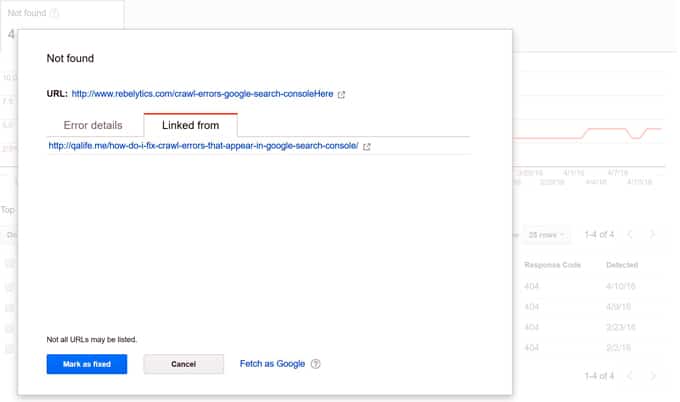
Please note that the info in the “Linked from” tab is not always up-to-date. It can contain URLs that don’t exist anymore or that don’t link to the error URL anymore. This is because in this tab, Google lets us know where it found the error URL, not where it is currently linked (as the name might suggest).
Did you know that you can download a report with all of your crawl errors and where they are linked from? That way you don’t have to check every single crawl error manually. Check out this link to the Google API explorer. Most of the fields are already prefilled, so all you have to do is add your website URL (the exact URL of the Search Console property you are dealing with) and hit “Authorize and execute”. Let me know if you have any questions about this!
Now let’s see what you can do about different types of 404 errors.
404 errors caused by faulty links from other websites
If the false URL is linked to from another website, you should simply implement a 301 redirect from the false URL to a correct target. You might be able to reach out to the webmaster of the linking page to ask for an adjustment, but in most cases it will not be worth the effort.
404 errors caused by faulty internal links or sitemap entries
If the false URL that caused the 404 error for the Google bot is linked from one of your own pages or from a sitemap, you should fix the link or the sitemap entry. In this case it is also a good idea to 301 redirect the 404 URL to the correct destination to make it disappear from the Google index and pass on the link power it might have.
404 errors caused by Google crawling JavaScript and messing it up 😉
Sometimes you will run into weird 404 errors that, according to Google Search Console, several or all of your pages link to. When you search for the links in the source code, you will find they are actually relative URLs that are included in scripts like this one (just a random example I’ve seen in one of my Google Search Console properties):
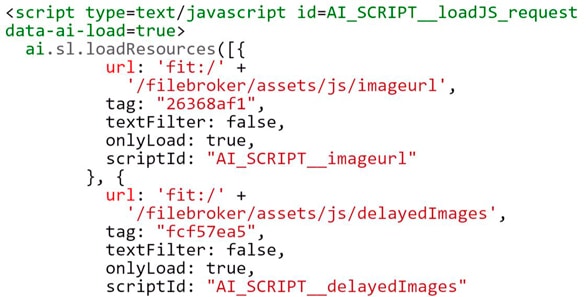
According to Google, this is not a problem at all and this type of 404 error can just be ignored. Read paragraph 3) of this post by Google’s John Mueller for more information (and also the rest of it, as it is very helpful):
Mystery 404 errors
In some cases, the source of the link remains a mystery. The data that Google provides in the crawl error reports is not always 100% reliable. For example, the information in the “Linked from” tab is not always up-to-date and can contain URLs that haven’t existed for many years or don’t link to the error URLs anymore. In such cases, you can still set up a 301 redirect for the false URL.
Remember to always mark all 404 crawl errors that you have taken care of as fixed in your crawl error report. If there are 404 crawl errors that you don’t know what to do about, you can still mark them as fixed and collect them in a “mystery list”. Should they keep showing up again, you know you will have to dig deeper into the problem. If they don’t show up again, all the better.
If you have a case of mystery 404 errors, feel free to leave me a comment at the end of this article. I’ll be happy to check out your problem.
Let’s have a look at the strange species of “Soft 404 errors” now.
What are “Soft 404” errors?
This is something Google invented, isn’t it? At least I’ve never heard of “Soft 404” errors anywhere else. A “Soft 404” error is an empty page that the Google bot encountered that gave back a 200 status code.
So it’s basically a page that Google THINKS should be a 404 page, but that isn’t. In 2014, webmasters started getting “Soft 404” errors for some of their actual content pages. This is Google’s way of letting us know that we have “thin content” on our pages.
Dealing with “Soft 404” errors is just as straightforward as dealing with normal 404 errors:
- If the URL of the “Soft 404” error is not supposed to exist, 301 redirect it to an existing page. Also make sure that you fix the problem of non-existent URLs not giving back a proper 404 error code.
- If the URL of the “Soft 404” page is one of your actual content pages, this means that Google sees it as “thin content”. In this case, make sure that you add valuable content to your website.
After working through your “Soft 404” errors, remember to mark them all as fixed. Next, let’s have a look at the fierce species of 500 server errors.
What to do with 500 server errors?
500 server errors are probably the only type of crawl errors you should be slightly worried about. If the Google bot encounters server errors on your page regularly, this is a very strong signal for Google that something is wrong with your page and it will eventually result in worse rankings.
This type of crawl error can show up for various reasons. Sometimes it might be a certain subdomain, directory or file extension that causes your server to give back a 500 status code instead of a page. Your website developer will be able to fix this if you send him or her a list of recent 500 server errors from Google’s Webmaster Tools.
Sometimes 500 server errors show up in Google’s Search Console due to a temporary problem. The server might have been down for a while due to maintenance, overload, or force majeure. This is normally something you will be able to find out by checking your log files and speaking to your developer and website host. In a case like this you should try to make sure that such a problem doesn’t occur again in future.
Pay attention to the server errors that show up in your Google Webmaster Tools and try to limit their occurrence as much as possible. The Google bot should always be able to access your pages without any technical barriers.
Let’s have a look at some other crawl errors you might stumble upon in your Google Webmaster Tools.
Other crawl errors: 400, 503, etc.
We have dealt with the most important and common crawl errors in this article: 404, “Soft 404” and 500. Once in a while, you might find other types of crawl errors, like 400, 503, “Access denied”, “Faulty redirects” (for smartphones), and so on.
In many cases, Google provides some explanations and ideas on how to deal with the different types of errors.
In general, it is a good idea to deal with every type of crawl error you find and try to avoid it showing up again in future. The less crawl errors the Google bot encounters, the more Google trusts your site health. Pages that constantly cause crawl errors will be thought to also provide a poor user experience and will be ranked lower than healthy websites.
You will find more information about different types of crawl errors in the next part of this article:
List of all crawl errors I have encountered in “real life”
I thought it might be interesting to include a list of all of the types of crawl errors I have actually seen in Google Search Console properties I have worked on. I don’t have much info on all of them (except for the ones discussed above), but here we go:
Server error (500)
In this report, Google lists URLs that returned a 500 error when the Google bot attempted to crawl the page. See above for more details.
Soft 404
These are URLs that returned a 200 status code, but should be returning a 400 error, according to Google. I suggested some solutions to this above.
Access denied (403)
Here, Google lists all URLs that returned a 403 error when the Google bot attempted to crawl them. Make sure you don’t link to URLs that require authentication. You can ignore “Access denied” errors for pages that you have included in your robots.txt file because you don’t want Google to access them. It might be a good idea though to use nofollow links when you link to these pages, so that Google doesn’t attempt to crawl them again and again.
Not found (404 / 410)
“Not found” is the classic 404 error that has been discussed above. Read the comments for some interesting information about 404 and 410 errors.
Not followed (301)
The error “not followed” refers to URLs that redirect to another URL, but the redirect fails to work. Fix these redirects!
Other (400 / 405 / 406)
Here, Google groups everything it doesn’t have a name for: I have seen 400, 405 and 406 errors in this report and Google says it couldn’t crawl the URLs “due to an undetermined issue”. I suggest you treat these errors just like you would treat normal 404 errors.
Flash content (Smartphone)
This report simply lists pages with a lot of flash content that won’t work on most smartphones. Get rid of flash!
Blocked (Smartphone)
This error refers to pages that could be accessed by the Google bot, but were blocked for the mobile Google bot in your robots.txt file. Make sure you let all of Google’s bots access the content you want indexed!
Please let me know if you have any questions or additional information about the crawl errors listed above or other types of crawl errors.
Crawl error peak after a website migration
You can expect a peak in your crawl errors after a website migration. Even if you have done everything in your power to prepare your migration from an SEO perspective, it is very likely that the Google bot will encounter a big number of 404 errors after the relaunch.
If the number of crawl errors in your Google Webmaster Tools rises after a migration, there is no need to panic. Just follow the steps that have been explained above and try to fix as many crawl errors as possible in the weeks following the migration.
Summary
- Mark all crawl errors as fixed.
- Go back to your report once a week.
- Fix 404 errors by redirecting false URLs or changing your internal links and sitemap entries.
- Try to avoid server errors and ask your developer and server host for help.
- Deal with the other types of errors and use Google’s resources for help.
- Expect a peak in your crawl errors after a website migration.
Important note: This article is out of date, as it deals with error reports from the old Google Search Console, which no longer exist. Comments are closed.
Hi… Thanks for the information… This below is the mail I got from Google few days ago
“Search Console has identified that your site is affected by 2 new Coverage related issues. This means that Coverage may be negatively affected in Google Search results. We encourage you to fix these issues.
Top new issues found, ordered by number of affected pages:
Submitted URL not found (404)
Redirect error”
Please, what should I do???
Please note that this article deals with reports from the old Google Search Console, which no longer exist, and your questions are about errors from the new Google Search Console.
For the error “Submitted URL not found (404)”, you can follow the advice for 404 errors described above.
The redirect error normally means that a URL redirects, but the redirect does not lead to a working target. You can check if there is a redirect loop or a similar problem.
I hope this helps. Please let me know if you have any further questions.
Hi thanks for this helpful guide. Unfortunately I am still confused about the errors showing up on my google search console. I think It happened after I moved URLs back in December. I now have 31 errors that simply say – Submitted URL has crawl issue, many of the links are to media items uploaded to my media library, some never used or deleted since. Others on pages that seem fine. I pressed the validate all fixes back on 6th March and now at 20th April it still says pending. I am not really sure what to do but I know my google rating has gone down enormously. In December my old site was close to 250 hits from google a day no I get about 2. Really lost what to do now.
Hi Jade,
If you changed your URLs last year, you should make sure that all old URLs that ever existed on your website now redirect to URLs that work and that have the same or similar content as the old URLs.
Most of you crawl errors are probably nothing to worry about and if you lost most of your organic search traffic, there are probably other reasons for this, even if the crawl errors might be related to some them.
Please let me know if there is anything I can do to help you.
Hi! Google is unable to index our homepage url https://wineshoplouisville.com/ and is showing a Crawl Anomaly error in Search Console. When I inspect the page source in Chrome and click on Network tab, it shows a 3.19sec load with 404 errors on two elements (header_bg.gif and title_bg.png), and 500 error on http://www.wineshoplouisville.com document. It seems that Google has grabbed all the other urls in our site though. I am not a developer, nor am I well-versed in wordpress (we are using All in One SEO plugin). Could this be an issue with the homepage image carousel or another plugin? Or is it something else altogether? (A couple side notes: This site was built a while ago and is using php5.6. As far as I understand it cannot be updated to php7 without a considerable amount of work. We changed hosting providers recently and our version of wordpress was updated at that time, and an SSL installed. Hosting provider assures us redirects are set up properly and there are no server side issues.) Thanks in advance for any thoughts!
Hi Shelby,
I checked your home page and it does indeed give back a 500 error, although it is working perfectly. This status code is the problem you should take care of first – you can worry about the 404s on the image files later, as they are not the reason for your indexing problems.
Your home page should be giving back a 200 status code. Google probably won’t index a page as long as it gives back a server error, even if it renders perfectly in the browser.
I’m not sure what this problem is caused by, but it might be a good idea to deactivate your plugins one by one to check if one of them might be causing this.
I hope this helps for now!
Best regards,
Eoghan
Hi
I am working on wordpress. Elementor plugin and yoast seo are there. When i create a page, i simply add title. And URL is generated with that title. But after updating all SEO information, there is new URL. But search console is crawling with old URL and 404 error is displaying.
Example:
1. Before Updation SEO information URL: http://healthgeekss.com/health/services/weight-loss/wl-sideeffects/
2. After Updation SEO information URL: http://healthgeekss.com/health/services/weight-loss/side-effects-of-rapid-weight-loss/
Google is crawling by first. Instead of 2nd but on blog there is 2nd updated URL. How to overcome it.
Please help me.
Hi Shikha,
Thank you for your question.
A quick solution would be to set up a 301 redirect from the old URL to the new URL. This would at least fix the 404 error problem.
You can then also check if there are any internal links, sitemap entries or similar pointing to the old URL. If so, they should be updated.
It might be possible to fix the underlying problem by making sure you don’t publish articles or pages before you’ve defined the final URL.
I hope this helps for now. Please let me know if you have any further questions.
Best regards,
Eoghan
Hi Eoghan,
I am working on a website is showing JavaScript in the meta description in Bing/Yahoo. For some reason, the homepage of the website doesn’t the title or meta description in Google.
Happy to share the URL with you in private.
Thanks
Sam
Hi Sam,
I will send you an e-mail so that you can share more information with me.
Hi Eoghan,
Thanks for this article. I have a question around SPA (Single Page Applications). I am currently get a soft 404 as I’m using Angular on my site to show content dynamically. I’m assuming this is the reason why I’m getting this error and why search engines are not crawling my site. Is there a strategy to overcome this for SPAs?
Hi Will,
Unfortunately, there’s not a simple answer to your question, as SEO for SPAs / JS frameworks is a complex topic, but here are a few things you could start with:
– Make sure every page on your website has a URL of its own (without using URL fragments).
– Make sure Google can render each page on your website.
– Consider server-side rendering as an option.
The latest versions of Angular have several SEO-friendly solutions.
I hope this helps for now!
Hello Eghan Henn.
I deleted many posts, categorys, pages, tags in my wordpress.
Now I give 404 errors URLs in my webmaster, Crawl errors.
please tell me how to fix it step by step?
Hi Milad,
Sure, here are the steps:
1. Export 404 errors.
2. Find a matching redirect target for every one of them.
3. Set up redirects (only for URLs that have a matching target).
I hope this helps!
Hello Eoghan, thank you for your useful post.
I’m having an huge increase of 404 errors on my website.
Since a couple of days, Googlebot (smartphone) crawls about 10k/day fake URLs.
URLs are like:
– /ebook-murray-lawn-mower-download-pdf.pdf
– /kim-passion.pdf
– /leddy-may-other-poems.pdf
– /ebook-minutes-of-stated-meetings-download-pdf.pdf
and so on… I never had those files on my website.
The strange thing is that for the URLs above, Google does not report the link source.
For all the other “normal” 404 errors, Google report the link source, both if it’s internal (e.g. sitemap or site page) or external (external site page that links to mine).
I searched for the URLs in all the website files (also cache files), databases, etc. There aren’t matching in any way.
Is anyone experiencing the same behavior?
Hello Franco,
This looks nasty! When you do a site: search for your domain on Google, you can see that there are thousands of URLs (mainly PDFs) indexed that don’t belong there. They all return 404 errors and they all seem to have had random content at the time they were crawled.
I’ve seen similar cases in the past on websites that had been hacked. Did you have any issues of that type in the past?
Hi,
This blog looks great. What if I get redirected error when i try to fetch and render in search console. Can any one guide me? How to resolve this ?
Hi Akshay,
What does the error say exactly? If it simply states that the URL is redirected, you should do fetch and render for the redirect target. If it’s a redirect from http to https, for instance, you might have to switch properties. If there’s an actual problem with the redirect (like a redirect loop), then you might want to fix that first.
Feel free to share more details about the error and I will be happy to help.
Hi Eoghan,
I have a similar problem that most of the people are commenting here..i.e 404 crawl errors in GWT…kindly check this snap https://prnt.sc/lxrgd8..this is a snap from GWT with all the errors in it….
i have tried for a couple of months to fix them by making ‘mark as fixed’ option…but these crawl errors gets generated almost every day…i have no idea where from these URLs are getting generated….
I have disabled almost all plugins…so that no problems arise out of plugins…
Moreover there is no point of making 301 redirects as these URLs are not from any contents from site and i will not be able to stop doing 301 redirects as the URLs gets generated every day…
No ‘LINKED FROM’ tab found in GWT…
what to do? Where from these URLs are fetching…ran my site for checking malware, no negative result found… can u plz help????
kindly come up with an answer asap…its troubling me a lot..
Thanks.
Brett Ander
Hi Brett,
This does indeed look strange. One thing you should be aware if is that by marking errors as fixed, you don’t actually fix them. You just make the URLs disappear from the report until they are crawled again.
This does look like some kind of malware problem to me. If you like, you can send me the URL of your website via e-mail and I will have a closer look.
Hi Eoghan,
Have you ever seen smartphone crawl errors like this one below?
size/x-large/page/2/%3Ca%20href=
I have hundreds of links with %3Ca%20href= appended to regular links.
Hi Nicolina,
Thank you for your question. “%3Ca%20href=” is “<a href=”, percent encoded.
This looks like a problem with broken internal links to me. There’s probably an error in one of the links in your page template that appends “<a href=” to the URLs of internal links or that simply links to “<a href=” as a relative link.
You can find this error by inspecting the source code of your page or by crawling your website with a tool like Screaming Frog. You can also send me the URL of your website via e-mail and I’ll have a look at it, if you like.
Hi Eoghan,
Very nice article. You have covered almost every possible scenario, except than what I am facing now 🙁
I see an strange issue in some of the websites who for some reason want to crawl my site and index it, specially Google Webmasters and Bing Webmasters.
The issue is that they are unable to show the screenshot of my website as their thumbnail !! (but it’s ok on some services like gtmetrix)
Here is the website: https://profile.center/
We have checked everything inside our codes, and found nothing…
Can you help me understand the reason?
Best,
Shahram
Hi Shahram,
Thank you very much for your comment. Could you please send me some additional information to help me understand your question better? Which thumbnail images are you referring to?
Hi Eoghan Henn,
I read your full article. Its really informative & well explained. My site has thousands of 404 errors in webmasters tools. The problem is that there is no linked page details. All the 404 errored paged were double encoded . For example , I have urlencoded the paged with “/” symbol to %2F in url parameter. But google showing 404 pages with “%252F” (google again urlencoded it % symbol to %25) . How to deal this type of errors. Any idea ? my site address is https://sapstack.com and the problamtic pages came from the section https://sapstack.com/tables
Hi Syam,
Sorry to hear about your URL encoding problem. I had a look at the URLs from your /tables/ directory that are currently indexed by Google and I couldn’t find any examples of error URLs, so that’s a good sign. Can you tell from the crawl error reports when this type of error was first detected? Maybe there was a temporary problem with your URL encoding that caused the errors. If Google is still re-crawling the false URLs you might be able to set up redirect rules to send the bot back to the correct version of each URL.
If you send me some more detailed information via email, I’ll be happy to have a closer look.
plz help me how can i fix this 🙁
URL Last Crawled
01 Sep 2018
Last Crawl Result
Banned Domain Or IP
Hi John,
This is an error message from Majestic, and not from Google Search Console, right? I’ll be happy to help you if you send me some more information.
Why will irrelevant crawl errors not show up again if I mark everything as fixed? I think it will be better if I can determine all critical errors right the first time and fix them immediately. A week may be too long to take action.
Hi Lina,
Yes, you’re right! If you’re able to analyse all of the errors straight away, then that’s the best thing to do. But if there’s a lot of data and you want to focus on the most important errors first, then marking everything as fixed is a good idea, because it allows you to start from zero and only address issues that were recently encountered by Google’s bots (the ones that show up again).
Hello Eoghan,
Thanks for the article, it’s really helpful, while we try to figure out what is happening on our site. We identified thousands of low quality posts on our WordPress site and deleted them from the site. We’ve updated any internal links pointing to those pages, so they are no longer being linked too. But since these changes, we’re still seeing within Google Search Console that our Not found errors has been increasing dramatically. We 301 redirected a large portion of these URL’s, but some we just left as a 404 as Google has mentioned in many instances this shouldn’t be a problem. Where I am concerned is that these URL’s are still showing up in the not found error reports. Also, they are showing ‘linked from’ URL’s that either no longer exist or they do exist, but there isn’t a URL to the error page. It feels like Google is crawling a cached version of our site or has a snapshot from 2-3 months ago, rather than showing the actual crawl errors today. We can’t seem to find where/how Google is displaying these URL’s. Any suggestions?
Thank you,
BJ
Hi BJ,
What you’re seeing is normal behaviour by Google. Known URLs will be re-crawled regularly, even if they no longer have internal links pointing to them and if they return a 404 error. The “linked from” tab in GSC shows where Google discovered a URL, but the links are normally not removed from the report when they stop existing.
The only way to stop Google from re-crawling your old URLs is redirecting them to a matching target. If you manage to identify a good redirect target for all of the old URLs you eliminated, that’s what I would recommend to do.
If it’s not possible to redirect all of the old URLs, you can also consider changing the status code of the removed URLs from 404 to 410. A 410 status code signals that the content was removed intentionally and Google will most likely re-crawl those URLs less frequently in future and eventually stop re-crawling them less frequently.
I hope this helps! Please let me know if you have any further questions.
Best regards,
Eoghan
Hi Eoghan,
This is a very helpful article. We use to get multiple 404 errors due to javascript and kept scratching our head to figure out what going on with the website and than we would request for a manual crawl, but now as you said such errors can be neglected, we are at great relieve. Will keep visiting this page if such error again show up. Thanks for this post.
If these errors show up again and again, or if there are lots of them, it’s worth checking where they’re coming from and fixing them. If there’s just an occasional error of this type, it’s probably not going to do any harm.
Hi Eoghan,
Great article > thank-you
Recently I was caught with a Yoast update issue causing Google and the other major SE to index every image as its specific unique URL page. I installed the Yoast Purge plugin.
But I am still getting URL 404 crawl errors now months later.
Will this clear sooner or later or do I need to take some other manual actions.
Thanks Darren
Hi Darren,
Thank you for your comment. I’m glad you liked the article.
The Yoast Purge plugin sets a 410 status code (instead of 404) for all of the attachment URLs. You can check your error reports to see whether the URLs have 404 or 410 errors. You can also double check the status codes with a tool like https://httpstatus.io. If they are 410 errors, everything’s fine. You’ll just need some patience until they all disappear. If you’re still seeing 404 errors, then either something isn’t working with the Purge plugin, or the errors were caused by a different problem.
I hope this helps for now. If you have any further questions, please just let me know.
Hi Eoghan,
I see some comments above about the Yoast plug-in, but nothing specific to the issue I’m having. I’m finding that the Yoast tags are coming up as soft 404 errors in Google Search Console. Do you know how I can continue to use Yoast without these errors?
Thanks!
Hi CL,
Nice website, I really like the design.
Tags aren’t a Yoast feature, they’re a standard WP feature, and it looks like you’ve deactivated some of them at some stage in the past (good idea). Some of your old tag URLs are now giving back 404 errors. On the 404 error page, there are links to other tags (at the bottom), which give back 200 status codes, but don’t have any content. These are the ones that show up as soft 404s in your crawl error reports.
Here’s what I would do: Deactivate tags altogether in WordPress, remove the links from the 404 error page, and make sure that all tag URLs give back 404 errors.
I hope this helps for now! Please let me know if you have any further questions.
Hey Henn, i’d appreciate if you can provide some insights or help
I am using pressive theme from thrive theme and thrive architect
My problem is in the google console as i have thousands of internal links, while i have 2 or 3 interlinking for each post and i have 50 posts
Thousands of these take this format http://prntscr.com/ktqz53
each post have 100s getting to each of them http://prntscr.com/ktqzpw
all my images are added via html and my xml sitemap has just pages and post
how can i clean up this stuff, my rankings have been dropping and i am thinking this maybe one of the causes
Hi Sammy,
When seeing the screenshots of your error URLs, I’m wondering if your problem is related to the Yoast image attachment bug from earlier this year. Please check this post on the Yoast website and let me know if it helps. If it doesn’t help, I’ll be happy to have another look at your problem.
Hi There,
I have around 8000 pages in my website. It is having around 22000 Not found URL. But when I am checking their source i.e. our internal link, the not found URL is not in that page anywhere.
Possible Reason of there errors are that I assumed:
1. I have replaced my topics taxonomy with tags
2. I have changed my “articles” taxonomy with “Category” taxonomy
3. Sometime I need to change my URLs due to various reasons immediately but my website is frequently crawled, it get cached immediately.. So that URL also comes Under “Not found” category
4. I am assuming these issue arises after the “Core Algo update” of Google On 18th April 2018 which suggest that you cannot change the URL. Is there any fix for the same if this is the only reason?
Some workaround that I have already performed
1. Removed URLs from Webmaster “Remove URL ” option
2. Tried to redirecting the above URLs on the current URL, but the website encounter so many issues, so removed the redirection
Can you please suggest any solution for the same
Hi Rajat,
When you change URLs, you should always 301 redirect the old URLs to the new ones. This might result in lots of redirects in your case, but it is definitely worth the effect.
In order to clean up the existing 404 errors, I recommend you redirect the error URLs to their new equivalents. In future, make sure that you always set up 301 redirects for URL changes immediately.
Also, maybe you can find solutions for not having to change URLs so much in future. URLs should only be changed when it’s absolutely necessary.
I hope this helps!
Hi Eoghan! Very very nice post!
I have a question, can you help me? WebMaster tools is showing me 404 errors, however it shows cut URLs. Sometimes missing a big chunk, sometimes missing only a hunk of html.
Example:
/corujinha-menina-lembrancinhas-e-imagens.h
/Centro-de-Mesa-Mario-Kart-Gr
Correct should be:
/corujinha-menina-lembrancinhas-e-imagens.html
/Centro-de-Mesa-Mario-Kart-Gratis.html
Hi Pedro,
Thanks for your comment. I’m glad you liked the article.
It looks like, for some reason, Google is trying to access these cut-off URLs on your page. The error URLs that are shown in the report are the URLs that Google actually tried to crawl.
Can you see where these URLs are linked from in the “linked from” tab? And do you have lots of error URLs of this type, or just a couple?
I hope this helps. If you have additional questions, please just let me know.
Hello, I am really hoping you can help me. I have a really bad situation with thousands of mystery 404’s showing up every day apparently from a googlebot searching my site. The site is positivemindworks.co . The only way I am able to keep my site active long term is by blocking the whole of the US from accessing it (with wordfence country blocker). Obviously having serious consequences for me SEO! If I lift the block for a day then googlebots try to crawl my site but keep crawling random dynamic mystery 404 pages that make no sense to me at all. After a few days it crashes my server. If you are in the US then I can lift the country ban for the day so that you can check out the site. Just please let me know when you are ready to take a look and I will lift it straight away. Thank you so much in advance!!!
Hi Samantha,
Thank you for your comment. I’m based in Spain, so there’s no problem for me checking your website.
It is indeed not a good idea to block all US IP addresses from your website. You really want Google to be able to crawl your website.
When I check which pages on your domain are currently indexed by Google, I see the type of URLs you are talking about: site: search for positivemindworks.co
Have you always owned this domain or did you acquire it from someone else? Was your website hacked recently?
Your server should normally not crash because of Google’s requests. You might have to think about upgrading your server. Also, you can try to limit Google’s crawl rate in Google Search Console under Site Settings > Crawl rate.
It is important that you find a solution for lifting the country block without Google’s requests crashing your servers first. Then, you should try to find out why these error URLs are being generated.
Apart from the solutions outlined in the article and in other comments, it might be a good idea to block the URLs in questions via the robots.txt file.
Please let me know if you need help with any of this.
My site http://www.jhollowell.com site returns a 403 to scanning tools/ googlebot. It is currently indexed on. Bing and Yahoo. kindly assist with these please.
Hi Ola,
Currently, I can’t access your website and I’m getting this error message:
Bandwidth Limit Exceeded
The server is temporarily unable to service your request due to the site owner reaching his/her bandwidth limit. Please try again later.
It looks like you have some server problems that need sorting out. Let me know when you’ve fixed it, so I can have a look to see if the 403 error for Googlebot is related to this or if there’s another problem.
Hi, I am seeing this in my Google Search Console: Googlebot couldn’t access this page because the server didn’t understand the syntax of Googlebot’s request.
This is a new site that was just set up within the last 2 months. It is WordPress hosted at GoDaddy with Cloudflare https.
Thanks so much for your help and dedication.
Hi Lori,
Thank you for your message. Which URL did you get this error message for? If you send it to me here or via e-mail, I’ll be happy to have a look at it.
Hello, sir, I have an error URL not found but I don’t know how to deal with such URL error because this the URL is like this: https://www.todaystechlog.com/category/pc/post-type-1 OR category/pc/post-type-1. So I don’t have any such URL on my site. Don’t know how such URL is created on my site I already set my permalink to sample post. So I won’t have any such kind of URL on my site. So how do I fix this kind of URL error? am using WordPress.
Hi Akshay,
It might be a URL that existed at some point in the past. If there are just a few errors like this, you can simply ignore them, or redirect the URLs to a matching target.
If there’s a bigger underlying problem and Google keeps finding new URLs, feel free to send me more information and I’ll be happy to have a look at it.
Hi,
Thank you for your article. We are a job listing website. Vacancies on our website expires after some time, so robot finds a lot of “not found” pages due to natural expiration. In our case, how should we handle it?
Hi Sutirth,
Thank you for your interesting question. Without knowing the details of your case, I would suggest giving back a 410 error code for expired vacancies. The URLs will stay show up in your error reports, but Google will understand that the content has been removed intentionally and might re-crawl the URLs less frequently in future.
Another option would be setting up 310 redirects, but I would only recommend this in cases where you have matching redirect targets, such as jobs that are very similar to the ones on the old URLs, which might be a bit difficult to set up in practice.
I hope this helps. Please let me know if you have any additional questions.
Best regards,
Eoghan
Hi, I got same error like top comment but can’t fix.
I have many 404 error url (deleted post)
https://ex.com/post_error_1 => It’s linked from https://ex.com/postx, /posty, /postz
https://ex.com/post_error_2 => same…
https://ex.com/post_error_3
https://ex.com/post_error_4
All page linked from (postx, postx, postz…) I checked and no more link to post_error_1 (or post_error_2…) but I don’t know why google still show linked (seem google not update).
on my site, all 404 error I hold old url and return 404 code (not found) – not soft 404.
so should I redirect 301 all error_post link to https://ex.com/404 (with 404 code return) or hold same old url https://ex.com/post_error_1 with 404 return code.
thank you
Thank you very much for your comment.
You’re right, Google doesn’t normally update the “linked from” information. It shows you were Google’s crawler originally found the URL, so it can happen that the pages shown don’t exist any more.
It is also normal that Google keeps crawling 404 pages to check whether the content has come back. If you like, you can just leave everything as it is and ignore the errors. If there are matching redirect targets for the 404 error URLs, it makes sense to redirect them. This way they will disappear from your error reports in GSC and Google will probably also stop re-crawling them eventually. Another option would be to give back a 410 error, instead of a 404, which is a stronger signal that the content has been removed intentionally and it can lead to Google re-crawling the URLs less frequently.
I hope this helps for now! Please let me know if you have any further questions.
Hi I am also getting same errors what George is getting like
https://www.ticklishblinks.in/fullscreen-page/comp-j7ephedi/2fd25b44-9622-11e7-bb53-12dd26dd586a/18/
I have lots of them. Please help!!
Hi Yogesh,
This seems to be a problem that occurs with lots of pages that are built with Wix.
I haven’t had much time to dig into this, but blocking the directory /fullscreen-page/ via your robots.txt file might help.
Feel free to let me know if any other questions occur while you do your further research on this.
I hope this helps for now!
Hello Eoghan,
Thanks a ton, as your redirection method worked like a charm for me, I was having an issue of 404 error pages, as you said we can find these issues in crawl errors, where search console provides a tab named “Linked from”, this linked from tab was containing my old pages of same website which don’t exist now and these URLs were from http://infusionarc.com and they were indexed but now my URL is https://infusionarc.com. So at first I resubmitted sitemap from my old domain i.e. from “http” and did redirection method on new domain i.e. “https”, and again resubmitted from “https”. Now there are 0 errors showing in search console.
Thanks.
That’s great! Thanks for sharing these details. Good work!
Hello sir,
Can you please help me, I am facing lots of 404 URL generated in webmaster.
Please check image there are all most 25k+ 404 URL generated in webmaster, I have also contact with server support, also scan website they didn’t find anything in my WordPress website.
I don’t’ why “info” folder created automatically. I have checked all source code.
Please help me to fix this issue.
https://prnt.sc/kcrvz9
Thanks,
Hi! Do you have information on where the URLs are linked from? You can find this by clicking on each URL and looking at the “linked from” tab. Without any additional information, it’s difficult for me to help you with this, but feel free to get in touch with more information, so that I can have a closer look at it.
Hi Eoghan,
it’s been a few months since I have a big problem of 404 errors that I can not solve.
I’ll explain shortly.
Apparently there was an error with the SSL certificate, confirmed by the Hosting provider. Because of this Google has linked links to another site, which resides on the same server and has the same shared IP.
This has caused over 3000 fake links linked to our domain.
The serp is completely invaded by these links with a lot of title and metadescription, clicking on them you get to page 404 of our site. By examining the individual links from the serp, google’s cache shows the pages with their original appearance and their original link.
The site is in no way corrupted or malware.
The provider confirms that the problem with SSL has been resolved.
I immediately reported the 404 errors as correct by the search console, but these come back again, I report them almost every day, if I do not, they multiply every day.
Although these links have never been present on our site.
I have also sent the sitemap several times, but it does not change anything.
I hope I was clear.
Do you have some advice?
Thank you
Hi Woody,
Simply marking the errors as fixed will not fix them, it will only remove them from the reports. If you want Google to stop crawling these URLs, I would recommend (in this case) to redirect them. As they never had any content, you probably won’t find a matching target on your website, so you can just 301 redirect them to your home page. This is not a very clean solution (redirecting tons of URLs to the home page is not something I would normally recommend), but it’s the only thing I can think of in an edge case like this.
I hope this helps! Please let me know if you have any additional questions.
Hello Eoghan,
Thank you for your answer.
Would not it be better to report them then as 410 errors?
Perhaps in this way we could even clean up the SERP of our site.
Error 410 indicates deleted contents, so maybe it’s a cleaner solution than 301 do not you think?
Thanks
Its Nice Explanation actually i am facing Soft 404 Errors in my web master tool . i Just started new blog but 404 error is coming. so should i ignore this type of error?
Please help
https://newswoxen.com/ This is website address
You probably shouldn’t ignore soft 404 errors! I’d recommend checking the error pages and figuring out why Google is seeing them as soft 404s (info above: https://www.rebelytics.com/crawl-errors-google-search-console/#what-are-soft-404-errors). I hope this helps! If not, please just let me know.
Hi,
i am using wordpress multisite platform.
please help me regarding 404 not found page error. why i am getting 404 error everyday . i already fixed 300-400 errors but still getting more new 404 not found page error, is there any way to overcome from this kind of problem.
you can check the following
https://prnt.sc/k9505f
https://prnt.sc/k951jw
please help me
Hi Raman,
Sorry, I can’t access your screenshots right now. It says “Lightshot is over capacity”. If you like, you can send me some more info via e-mail and I’ll have a look.
Hello Sir, I`ve found something strange on my website
Just in 2 days it have 400 ++ Url Erros (not found) like you can see here : http://prntscr.com/k36tc0
And all the errors are the same, can see here : http://prntscr.com/k36ts4
Why would Google bot crawl until the page so far far away? I really dont get it why.
Do you have a solution for my problem sir?
It looks like you’ve got something strange with pagination going on there. I quickly checked your indexed URLs and it looks like most of them end with /page/-number-/. If some of these URLs stop existing, you should make sure to redirect them to a matching target, so that they don’t throw 404 errors.
I hope this helps!
Hi Sir,
I am trying to crawl my website https://wdsoft.in/ in webmaster tool, but it’s not crawling successfully, it’s continuously shown redirected, please help me how to fetch my website as google fectch.
I hope you help me.
Thanks
Hi Arun,
at a first glance, I can’t detect any important problems. Are you using the right property? If you’re in the http or www property, although your page is on https and without www (and http and www URLs redirect to the correct versions), all URLs you fetch will show as redirected.
I hope this helps! If you have additional questions, please just let me know.
Hi Eoghan Henn !
My Name is Samia and I’m a blogger. I’m facing an issue named “Server Error”. I’m using Newspaper 8 Theme and the Error is ” /wp-content/themes/Newspaper/” can ou please guide me how to Fix it ?
Hi Samia!
Thank you very much for your comment. You shouldn’t worry too much about this error. Maybe you can find out how Google found this URL? This discussion might help: https://www.rebelytics.com/crawl-errors-google-search-console/#comment-11988
Please let me know if there’s anything else I can do for you.
Hi,
I bought a new domain through Shopify and set up the store. Suddenly some strange links started to appear in search console like 404 errors. Those links are from a site which had the same name, and was previously owned by someone else and when I looked up in Wayback machine this website was active till 2017 and it was some sort of world news website. My shop is related to fashion and I am getting links like world news, archive567, tag/beyonce, car accidents, tag.christians, tag/campus etc. There is no way to redirect them. I have deleted those links like they were fixed but they reappear again and again. I don’t want to start a brand new website with some spamy links and warnings from Google. Please tell me how to deal with it and how they can sell domain which is not completely clean.
Thank you
Hi Lana,
Thank you for sharing this interesting case. What’s happening here is totally normal – Google still knows the old URLs and tries to re-crawl them once in a while, in order to see if the old content has come back. This will probably never stop, unless if you set up 301 redirects from those old URLs to new targets that actually work. Another option that might work would be returning a 410 code instead of a 404 code. This is a signal to Google that the content has been removed intentionally and they might re-crawl the URLs less often or stop crawling them altogether. If Shopify itself doesn’t give you these options, there’s certainly another way of doing it. 301 redirects, for instance, can be set up fairly easily, if you have access to your .htaccess file.
I hope this helps for now!
Hello Eoghan!
We recently received an email from Google telling us that we had an increase in “404” pages, and when I logged into our Google Search Console, saw that they are almost entirely links to pharmaceutical drugs. Why would this be happening and what should I do? I’ve changed all passwords in case we were hacked, but didn’t receive any kind of alerts from our WordFence.
Apparently, the source of the link is another link on our website that is also marked as a 404. Really confusing.
Thank you for your help!
Katie H.
Hi Katie,
Sorry about my late reply. I’ve been very busy these last few weeks. The problem you describe could indeed be related to some kind of website hack. If you send me some additional information, I’ll be happy to have a closer look at it to see what it might be.
Best regards,
Eoghan
How should I think about it if URLs keep recurring in this report that were once broken URLs on a site but which have since been removed? In some cases, Google still claims a “linked from” to be pointing at the URL which I’ve verified does not contain it.
This happens a lot. The “linked from” info should not be interpreted as “currently linked from” but rather as “once upon a time linked from (when we first found this URL)”. Google will keep recrawling old broken URLs once in a while. If you really want it to stop, you can redirect the old URLs to matching targets. Otherwise, you can just ignore the crawl errors.
i have some faulty links from other sites which are pointing to my site assets for which i cant even put 301, so i wonder is it safe to redirect all 404 to home page just or its bad
Hello Zahid,
redirecting a bunch of URLs to the home page should always be the last option. Can’t you find better redirect targets, at least for some of the URLs?
Hello, for some reason I got a regular amount of 404 errors through search console, that I took care of, but there are many more with random urls that I’ve never seen before when I check in the Redirection plugin. Do you know what this could mean?
https://ezhangdoor.com
Thanks!
Hi Trey,
Do the URLs only show up in your redirection plugin, or also in GSC?
Very informatif posting sir. I had some problem with my website crawling. Many of my website url suddenly error. The url got messed up. There are two slash. Here some example:
https://modifmotor1.com/cover-bodi-samping-vario-125-techno-lama-warna-lengkap/cover-bodi-samping-vario-125-techno-lama-warna-putih/
https://modifmotor1.com/per-klep-racing-jepang-satria-fu/per-klep-jepang-satria-fu/
https://modifmotor1.com/rumah-roller-racing-honda-vario-110-ktc/pulley-set-roller-racing-honda-vario-110-ktc/
Please help. It made my website many of the post in page 1, gone 🙁
Thank you in advance
Hi Zhoel,
I’m sorry, I’m not sure I understand your problem. Your example URLs are working. Could you send me some additional info, so that I can try to help you?
Hi Eoghan,
I recently redesigned this site on an entirely different server after being hacked (0ld-Prestashop). there were more than 1000 pages and google alerted us to the hack. I fixed the issue and actully found the directory in the hidden files on the server, we no longer have that host. All the files were recreated for the new design (watermarks placed on the artwork) this is a stencil site.
How do i get rid of the 404 errors as a result of the hack? fixed the site within 2 days of the hack but, a month later the 404 errors are still showing.
thanks
Therese
Hi Therese,
I’m sorry to hear your website was hacked, but it’s a good thing you got it fixed so quickly.
Google will probably keep recrawling the fake URLs once in a while, and you have three options for dealing with the 404 errors, none of which is ideal:
1. Just ignore them. They probably won’t do your SEO performance any harm. The downside is that they’ll get in your way in the crawl error reports.
2. Change the status codes for all of the fake URLs to 410. They will keep showing up in the error reports every time they’re crawled, but with a 410 error code there’s a chance that Google will crawl them less regularly and will eventually stop recrawling them.
3. Redirect all of the fake URLs to another URL, e.g. the home page. You normally shouldn’t abuse 301 redirects like this, but I guess that in your case it would be an option to just make the URLs go away from your crawl error reports. You don’t constantly want to be reminded of that time your site got hacked, right?
I hope this helps. Please let me know if you have any further questions.
As you said First, All error mark as fixed. My question is If not found error more the 5000+ how to mark as fixed in once as it only show top 1000 links. Is there any way to mark fixed all 5000+ link at once
I’m sorry, I don’t know of any other way to mark crawl errors as fixed than doing it 1000 by 1000, as soon as the next 100 show up. Even if you use the API and don’t do it manually, you have to wait for the next 1000 errors to show up, as far as I know.
hi Eoghan Henn!
I’m in trouble I receive a message from google console.
” Warnings
URLs not accessible
When we tested a sample of the URLs from your Sitemap, we found that some URLs were not accessible to Googlebot due to an HTTP status error. All accessible URLs will still be submitted.
1
Sitemap: urdutalkshows.org/sitemap_post.xml.gz
HTTP Error: 404
URL: http://urdutalkshows.org/countries-facts/facts-about-Saudi-arabia.html”
How it fix this problem…!
Hi Hafiz,
In order to fix this problem, you should remove the URL with the 404 error status code (http://urdutalkshows.org/countries-facts/facts-about-Saudi-arabia.html) from the sitemap (urdutalkshows.org/sitemap_post.xml.gz). Or, if the URL http://urdutalkshows.org/countries-facts/facts-about-Saudi-arabia.html should be available, make sure it works again and doesn’t give back a 404 error.
I hope this helps!
After reconstructed my website webmaster shows many crawl errors about older URLs..After i mark it as fixed can i redirect it to new URLs ..is Google will consider this redirection?
Hello Afzal,
Google will start processing these redirects as soon as it re-crawls the URLs, which can take a while. The errors should not show up in your reports again.
I have a question regarding the relationship between the graph that is displayed and the number of errors that show below. If I hover on the graph it will show “36 errors” on March 12. If I look in the list of URL’s it will show 5 URL’s listed on the same date. Where do the 36 errors come from if only 5 URL’s are listed?
Thanks!
Hi Kara! The number represented in the graph is the total number of crawl errors that Google is currently displaying for your website. If you see a total of 36 errors and 5 error URLs that were discovered on March 12, the number of errors displayed in the graph for March 11 should be 31. If it’s higher, that’s because some errors were removed the same day (meaning that Google re-crawled previous error URLs on March 12 and found that they were no longer returning errors). I hope this helps! Please let me know if you have any further questions.
I got the problem on my voxya website. When I added SSL on the website then webmaster start showing server connectivity (Connect timeout, Connection refused, No response) and robots.txt (Unreachable) fetch problem. Please help me how I can resolve this problem.
Hello Akriti,
Sorry to hear about your problems! Did you make sure all of your http URLs now redirect correctly to their https equivalents? Did you set up a new Google Search Console property for your https version?
Feel free to send me some more information and I’ll be happy to help.
Hello,
My website getting 503 errors in WMT all those not found pages redirected to main page that is how my script designed. So please tell me what should i do to 503 errors? should i “fetch as” and point them all to my main page?
thank you
Hi Anthony,
503 errors are often caused by a temporary problem (like server overload). You should check if the pages GSC shows 503 errors for are constantly unavailable or if it really just is something temporary. If it’s a temporary problem, you don’t really have to do anything to the URLs, except for making sure the problem doesn’t return. Maybe you need a better performing server?
The other thing you mention, with all 404 error pages automatically being redirected to the home page, is something you might want to review. The home page is not always the best redirect target for URLs that no longer exist.
I hope this helps!
hi, i could fixed all my errors in google search console.
thank you.
Happy to hear that! Thanks for your comment.
Hi i have a couple of errors which i cant figure out how to correct.
Access Denied
https://cassies.com.au/feed/?attachment_id=3380
404 error not sure what to do.
sitemap-tags.xml
Thanks
Danny
Hi Daniel,
Here’s what you can do:
– Find out where the URLs are linked form and remove the links.
– If possible, redirect the URLs to a fitting target.
– Mark the errors as fixed in Google Search Console.
I hope this helps!
how do i have get rid of crawl errors on google web master. All the crawl errors are for pages that are deleted because products are discontinued.
Hi Olive,
When you delete pages because products are no longer available, you have many options, three of which are:
1. Simply return 404 errors for the deleted URLs, as you’re doing right now. This will cause 404 errors in GSC and probably also for some users, but it won’t do too much harm, so it’s OK if you don’t have the resources to set up another solution.
2. Find a matching product that you can 301 redirect the old URL to. If you choose this option, you should make sure that the product you redirect the old URL to is a good and relevant replacement for the discontinued product.
3. Give back a 410 error instead of a 404 error for discontinued products. This is a stronger signal that the URL has been removed intentionally and might lead to Google trying to re-crawl it less (although this is not guaranteed). In your crawl error reports, URLs with a 410 error code will still show up as 404 errors.
I hope this helps! Please let me know if you have any additional questions.
Update: 410 errors now show up as 410 errors in Google Search Console, and are no longer marked as 404 errors.
hello, Eoghan Henn nice info.
what exactly I get from google webmaster
1 server error and 22 not found for desktop
0 server error and 2 not found for smartphone
so can I fix that server error?
thanks
Hi Bablu,
First, you should check if the server error is still happening – often they are just temporary. If it still happening, check if the URL should really be working. If not, make sure you don’t link to it and redirect it, if you can. If it should be working, try to find out why it isn’t and fix it.
I can’t help you much without additional information, but feel free to share more details (via e-mail if you like).
Those 22 link on google webmaster whenever I click on them they all redirect to 404 not found. A couple of day ago i edit all of these link to make better my seo using Yoast . isn’t that is result of that. and also server 1 error still appears.
Hello Bablu,
It’s good that you have already identified the links pointing to the error URLs and changed them. Now, if possible, you should redirect the error URLs to matching targets (there are also WordPress plugins for this). Then you can mark the errors as fixed in Google Search Console and they should not come back.
For the remaining server error, you can do the same.
I hope this helps!
Hello Eoghan,
can You solve this problem? Not followed link in google search console.
this link made by feed burner.
there is an example:
2012/05/mark-twain-all-bangla-onobad-e-book-%E0%A6%AC%E0%A6%BE%E0%A6%82%E0%A6%B2%E0%A6%BE-%E0%A6%85%E0%A6%A8%E0%A7%81%E0%A6%AC%E0%A6%BE%E0%A6%A6-%E0%A6%87-%E0%A6%AC%E0%A7%81%E0%A6%95-%E0%A6%AE%E0%A6%BE/feed/
Hi Anick,
I believe that these URLs are generated in a link element in your head section.
If you go to the source code of the page https://allbanglaboi.com/2012/05/mark-twain-all-bangla-onobad-e-book-বাংলা-অনুবাদ-ই-বুক-মা/, you will find this element in line 48:
<link rel=”alternate” type=”application/rss+xml” title=”Allbanglaboi – Free Bangla Pdf Book, Bangla Book pdf, Free Bengali Books » Mark Twain All : Bangla Onobad E-Book ( বাংলা অনুবাদ ই বুক : মার্ক টয়েন এর গল্প সমগ্র ) Comments Feed” href=”https://allbanglaboi.com/2012/05/mark-twain-all-bangla-onobad-e-book-%e0%a6%ac%e0%a6%be%e0%a6%82%e0%a6%b2%e0%a6%be-%e0%a6%85%e0%a6%a8%e0%a7%81%e0%a6%ac%e0%a6%be%e0%a6%a6-%e0%a6%87-%e0%a6%ac%e0%a7%81%e0%a6%95-%e0%a6%ae%e0%a6%be/feed/” />
The URL that is linked in the href attribute gives back a redirect that doesn’t resolve properly, that’s where the “not followed” error comes from.
I hope this helps! Please let me know if you have any further questions.
Thanks Eoghan for the reply. but I can’t solve this problem. in google search shows 516 Not followed link on my site.
Hi Anick,
I’m sorry my reply didn’t help you. Maybe you know a web developer you could ask how to remove the element that is causing the errors from your source code?
We fixed thousands of 404 errors with redirection, but just out of curiosity, is it necessary to mark the URLs fixed in GWT or will the Crawl Error report eventually be updated automatically?
Hi Carey,
As far as I know, the crawl error report is updated every time Google attempts to re-crawl an URL that previously had an error, if the error is gone by then.
Redirected URLs should disappear from the crawl error reports over time.
i have marked it as fixed but still its showing on. and i dont want to redirect it.
I have also deleted from my website, now what should i do ?
Hi Ankush,
If you mark an error as fixed and it shows up again, that means that Google tried to access the URL again. You can ignore this, if you like, which shouldn’t cause to many problems in most cases. You can also change the status code of the URL to 410 and hope that this helps Google understand that the URL is not coming back and that they try to access it less often.
I hope this helps! Please let me know if you have any further questions.
I have these 5 errors come up in the last few days and my site has been fine and I havent done anything to it.
The first 4 say not found url points to a non existent page, the last one says other – google was unable to crawl this url due to an undertimined issue
Any help correcting it would be much appreciated
1
fullscreen-page/comp-jbuvb96h/779897c6-9f10-4634-a89c-088088fda3b4/32/%3Fi%3D32%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/18/18
2
fullscreen-page/comp-jbuvb96h/097cd7ba-d2dd-4f27-b842-41fb9e4bce71/10/%3Fi%3D10%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/17/18
3
fullscreen-page/comp-jbuvb96h/51ce979e-13b2-4583-9922-0669fdf3009d/4/%3Fi%3D4%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/17/18
4
fullscreen-page/comp-jbuvb96h/c67a24e8-5266-4d0f-9da7-dbf04366a86e/21/%3Fi%3D21%26p%3De6zct%26s%3Dstyle-jbvcqto6
404
1/17/18
1
_api/common-services/notification/invoke
405
1/20/18
Hi George,
Thank you for your comment. I had a quick look at your website and I couldn’t find out where these URLs are being generated.
If you do a site search for your website, you will see that there are lots of URLs in Google’s index that you don’t really want there (including URLs like the examples you provided):
site:georgecoullpaintinganddecorating.co.uk
Your website only has one URL that you need crawled and indexed, so it might be a solution to limit crawling to only this URL via your robots.txt file (without blocking resources that are needed to render the page).
I hope this points you in the right direction. Please let me know if you have any further questions.
Hi George! Did you find the solution for your errors? I am also getting the same errors. Please help. I guess it has something to do with Wix
There are many products on my site, many products are no longer for sale,, and we have directly deleted the products that are no longer being sold. As a result, there are many 404 pages((more than 1,000) in Google Search Console. Recently, Google rankings are dropped rapidly. How should I handle this?
301 redirected to the home page? Or blocked resources by robots.txt?
Thanks!
Hi Kingbig,
Thanks a lot for your comment. First of all: If you lost rankings, this is probably not due to the 404 errors in your reports. 404 errors do not directly cause ranking losses. What might have happened is that the pages you deleted were ranking before – hence the ranking losses after deleting them.
Here are some things you can do:
If you really have to delete a page, redirect the URL to a similar target, NOT to the home page. A similar target in your case might be a newer version of a discontinued product.
Think about whether it always makes sense to delete pages of products that are no longer sold. If they can’t provide any value any longer – sure, delete them. But maybe some of your products turn into collector’s items once they’re sold out? If people are still searching for them, try to provide them with info about the product that they might be interested in. This is good branding for you and next time they might buy from you. In general: if you have a page for something that people are searching for, do your best to give them what they need.
Also, try to find out what exactly caused your ranking losses: Which pages and keywords dropped? Is this really related to the pages you deleted or did something else happen?
In hope this helps for now! Please let me know if you have any further questions.
Hello
I get some 404 errors everyday from “Google Webmaster Tools”, whereas these 404 pages (that Google says) have deleted
for a long time and I have cleaned these old URLs several times by “remove urls” tools either.
I didn’t find any way exept “301 redirect” and i used wordpress plugin to do that. the plugin solved my problem, but reduces
my site speed, so that my site couldn’t load at all.
I did “redirect” technic by htaccess file (without any plugin) but i have this problem (reducing page speed) again .. !
I would appreciate it if help me fast, because i can’t find another way to solve and this issue is important for me ..
Thanks a lot ..
Please note that marking errors as fixed doesn’t change anything for Google: They will continue crawling the error URLs once in a while to check if they’re still not working.
301 redirects are a good way to get rid of errors, as long as you find valid redirect targets.
Using a .htaccess file sounds like the right option. How many rules did you add to it? It would have to be extremely big to slow down your website. Improving your servers’ performance might be the right way to go.
I hope this helps!
There is a page on our corporate website called /Folsom
But I’ve noticed that in WMT a series of randomly appearing 404 pages, such as:
Folsom/UaURY/
Folsom/LMZVM/
Folsom/mTfQh/
Folsom/hTWSZ/
There are dozens of these, and I have no idea where they are coming from. It makes me wonder if Googlebot is trying to crawl one of the ASP.NET form tags but that wouldn’t make sense.
If there is some easy way to prevent these let me know.
I spoke with our IT department and we were able to track down what these URLs were coming from. An external email program from one of our clients was generating these URLs, that explains why there was no referrer. Thanks
Hi Mike,
Thanks for sharing this interesting case. How did Google end up crawling these URLs?
Best regards,
Eoghan
Hi,
In my search consol showing crawl error 404 and same link delete from my website dashboard ( website builder). I marks as fixed all error but they don’t working or same page error 404 showing.
Hi Lokesh,
Thanks a lot for your comment. Marking an error as fixed just stops the error from showing up in your reports, but it doesn’t actually fix the error. If you want to achieve this, you should also set up a 301 redirect from the URL that is no longer working to a matching target, if there is one.
I hope this helps. Please let me know if you have any further questions.
Nice article.
I have a question though. I have 188 links ending in // and when I want to see where they are linked from the “Linked from” tab dosen’t appear. What does that mean?
Thanks.
Hi Casper,
Thanks a lot for your comment. Google does not always show “linked from” information. This often happens for very old URLs, or sometimes (but probably not in your case) also for URLs that Google accesses although it didn’t find any links pointing to them (for example m.yourdomain.com to check if there is a mobile subdomain).
Can you determine redirect targets for the faulty URLs? If so, I would recommend you set them up and don’t worry too much about how Google came up with the URLs.
I hope this helps. Please let me know if you have any additional questions.
I am Vivek Suthar. when my website was live my website has ‘capital letter’ links and google index all links, but I got the good result. then after I transferred all my website links into ‘small letter’ submit sitemap again, but now a day I lost my traffic but my all keyword position is not changed. plz..give me some suggestion for it.
Hello Vivek,
Thank you very much for your comment.
It seems odd if you lose your traffic, but not your rankings. Maybe one of the data sets you are using is not correct or not up-to-date?
Changing all of your URLs can cause a loss of traffic, especially if you don’t redirect your old URLs to their new equivalents. And even then, you should expect a temporary loss of organic traffic. Did you set up redirects from your old capital letter URLs to your new lower case URLs?
Please let me know if I can do anything for you to solve this.
Hello Eoghan,
Greetings of the day!
I read your article. I got some help from your article but I am stuck somewhere and need your help. My website has desktop and mobile site. I checked in webmaster crawl error menu that some desktop url have 404 error which I will have solved with the help of the team but when I go to the smartphone urls then its showing faulty redirect. 62 links showing faulty redirect on smart phone url. Please help how I can resolve these faulty redirect which is showing in the smartphones. Please help.
Regards,
Ankit
Hello Ankit,
Thanks a lot for your interesting question.
The “faulty redirects” error often occurs if redirects for mobile users don’t send mobile users to the exact equivalent of the desktop URL they requested on a mobile device, but to the home page of the mobile version instead. Is this the case on your website?
More info from Google here: Faulty redirects.
If you like, you can share more info with me and I will have a closer look at your problem.
Hi Eoghan,
Thanks for helping me. In future, if I get any problem I will surely message you.
Thanks
Dear sir,
How to remove a crawler errors in webmaster tools. Please info. me point to point.
Following errors in my site.
Current Status
Crawl Errors
Site Errors
DNS Server connectivity Robots.txt fetch
URL Errors
2 Soft 404
3 Not found
Hi Thalib,
Your low numbers of crawl errors are really nothing to worry about. If you still want to fix them, these two sections of the post should help you:
https://www.rebelytics.com/crawl-errors-google-search-console/#what-are-soft-404-errors
https://www.rebelytics.com/crawl-errors-google-search-console/#the-classic-404-crawl-error
If anything remains unclear, please let me know. I’ll be happy to advise further.
Thanks for this article. We did a relaunch of a quite big page a few months ago. We could decrease the 404 from about 110’000 pages to about 50’000 pages. All the important pages have been redirected, so the 50k missing ones at the moment are just “collateral damage” but they keep beeing stuck in the Google Index. Therefore I would like to forward them all to the home page. Do you know how I can download more than 1000 pages? Thanks
Hi Simon,
Thanks a lot for your comment. Unfortunately, I believe that you cannot export more than 1000 errors at a time. This limit seems to hold, even when using the API.
Are the 50000 pages that are left actually indexed (as in: they show up in Google’s search results when you perform a site search for your domain), or do they just keep showing up in the error reports in Google Search Console?
I would generally advise against just redirecting such a big number of URLs to the home page. This wouldn’t really add any value to the situation. Better options would be finding matching redirect targets, or changing the status code to 410, to signal that the pages have been removed intentionally.
Please let me know if you have any further questions.
hello,
my site had a lot of 404 error, and i fix them by google webmaster. but some of them repeat everyday yet, what should I do?
( they are the links that i received from other sites or blogs and these URLs are changed now)
please help me.
thank you.
Hi Leila,
Just marking errors as fixed in Google’s Webmaster Tools doesn’t really fix errors. If they show up again the next day (or later), this means that Google has tried to access the URLs again.
If you received links from other websites to URLs that do not exist any longer, it is very important that you set up 301 redirects from the error URLs to pages that work and that have similar content. This way, you do not only prevent 404 errors from showing up in Google Search Console, but you also send users that click on the links to the right target and direct the relevance that these links pass to your website to important pages, instead of losing it to an error page.
Please let me know if you need any further guidance with this issue.
Hy sir!
I really Like Your Post and read it from start to end…
now, the question is that “How we completely remove the crawl errors 404 “not found” and delete disappear that posts which i have already removed and that create the 404 not found error …
i want to make my site error free totally…
please help!
i will extremely wait for your response…..
Thanks is advance
Hello Alex,
Thank you for your comment. I’m sorry you had to wait so long for my reply.
There are very few sites that are completely error free, but it’s a good goal!
If you want to make all 404 errors disappear, you will have to set up 301 redirects for all error URLs to working targets. But please make sure that the targets match the content of the original URLs! It does not have to be exactly the same content, but a good equivalent. It would not be a good idea to set up redirects just to make the errors disappear if you do not have matching targets that you can redirect the URLs to.
I hope this helps! Please let me know if you have any further questions.
hi Eoghan Henn, please provide details about blocked resources by robots.txt, how to solve these errors.
thank you!!
Hello Agon,
I’m sorry about my very late reply. I’ve had some crazy weeks and I didn’t manage to keep up with all the comments on here.
The error you are referring to normally occurs when Google’s mobile bot is blocked from certain URLs via your robots.txt file. You should check the error URLs, ask yourself if you need the mobile bot to crawl them, and if so, make sure that they are not blocked via your robots.txt file.
Please let me know if you have any further questions.
Im in very big trouble i have 27 server errors soft error 3 not found 127 and it is increasing day by day. Please help me to resolve them. Please help me
http://www.Techmanish.com
Hi Manish,
if you send me some more detailed info, I’ll be happy to help!
Great article – thanks for all the info! My question is when you utilize APIs Explorer, can you input the MAIN website as siteUrl? Will that fix all (about 500) crawl errors on my site?
Thanks in advance for your help,
Dars
Hello Dars! You can use the API explorer to export crawl errors, or to mark them as fixed (here), but not to actually fix them. Unfortunately, with the API explorer, you still have to mark them as fixed one by one. Via the API, you could probably mark them as fixed all at once, but you’d need a script for that. For actually fixing your crawl errors, you’ll still have to analyse them one by one to find the source of the problem. I hope this helps! Please let me know if you have any other questions.
I checked all 404 errors using:
https://www.google.com/webmasters/tools/crawl-errors?hl=en&siteUrl=https://globalcommercialparts.com/#t2=1
and found really scary ones like:
appliance-parts/rotisserie/twitter.com
appliance-parts/rotisserie/youtube.com
appliance-parts/freezer/twitter.com
appliance-parts/food-storage/youtube.com
How this url was buil by Google crawler?
How to fix such issues?
Hello Leo,
these errors are caused by broken internal links on your page.
For example, on https://globalcommercialparts.com/appliance-parts/rotisserie.html, you have the following links in the footer:
<li class=”twitter”><a href=”twitter.com”>Twitter</a></li>
<li class=”youtube”><a href=”youtube.com”>YouTube</a></li>
These are interpreted as internal links to
https://globalcommercialparts.com/appliance-parts/rotisserie/twitter.com
and
https://globalcommercialparts.com/appliance-parts/rotisserie/youtube.com
because the protocol is missing from the URLs. You should change the URLs in the links to https://www.youtube.com/ and https://twitter.com/ to fix this.
I hope this helps! Please let me know if you have any additional questions.
Sir, please help me to come out the scary situation. Since from six month my website is going as usual and Google fetch the url’s slowly. But suddenly- from last two week Google response some absurd results. Increasing 503, 404, 303 error day by day, alexa is going higher, keywords which are exists within 100 numbers- they are going obsolete, traffic has fallen down etc. Please suggest me how I control over my website, it is an e-commerce B2B website. I am going to shock for the Google activity and I am scare about such things are happen. Please suggest me how to control over it.
Hello Deepak,
Thanks a lot for your comment and sorry about my late reply. I have had trouble keeping up with all of the comments over the last few weeks.
Your questions is a very general one, but I will try to give you some replies: When crawl errors show up in Google Search Console, there is normally a good reason for it, even if it’s sometimes hard to spot it right away. If you double check an error and everything seems to be alright with that page, there are different scenarios. The error might have been temporary and in this case, you should only make sure that it is nothing recurring. Another option could be that the error only occurs when Google tries to fetch the page, but not when you access it with your browser. It is a good idea to use a crawling tool like screaming frog and crawl the page with different settings in order to find errors: With and without JavaScript rendering, with different user agents (including Googlebot), with and without robots.txt and so on. If you want to dig deeper, you can also do log file analysis in order to find out how and when search engine bots crawl your page.
I hope this helps as a first general answer to your general question. Please let me know if there is anything else I can do for you.
HI Eoghan,
Back on 6/9/17 you said that there is no limit to the number of redirects a site should use, but it is important not to abuse the feature either. When you set up a redirect it should be justified, which means that the content of the old URL should be found on the new URL (or at least a similar version). It is not a good idea, for example, to redirect loads of old URLs to the home page.
One problem that can arise with lots of redirects is that your htaccess file simply gets too big, which has a negative impact on the load time of your pages.
I have been working on these redirects and I have about 650 of them to date. My website weights 830 MB right now. In the scheme of things is 650 redirects at lot to have in my htaccess file? If not, what is the threshold where there would be too many and I would begin to see a negative impact on the load time of my pages?
Dirt E. Harry
President & CEO
http://topairgun.com
Hi Dirt E. Harry,
Good to hear from you again!
I really can’t tell you exactly when a .htaccess file is TOO big (because I don’t know), but I’ve seen websites with tens of thousands of redirects and no noticeable problems due to it, so I guess you’re on the safe side with your 650 redirects.
Just keep an eye on your server response and page load times and you’ll be fine.
Thanks Eoghan!
Well done and in depth! To reiterate something you talked about with 404 errors. So many of my clients worry when this error comes up but the reality is that is a past SEO or employee writes a post or content that is unrelated or useless in the sense of being spun content or otherwise it is actually a good thing. Let the 404 stand and say “this page is gone for good”.
Luckily I have noticed with Google’s recent update on 301 and 302 redirects sending more SEO juice through that 404s have equal swiftness in content removal. This is great if you are looking to get rid of old unrelated content. In the same vein it could be bad if you intended to redirect to the correct page and didn’t. That is the whole point behind the 404 error is the ability to see content that isn’t currently going anywhere and fix it.
Hello Anuj,
Thanks a lot for sharing your experience with us!
Best regards,
Eoghan
Thanks for all this great advice! I’ve been trying to fix a ton of errors in Google Webmaster Tools and pretty much getting nowhere.
I’ve noticed that I’ve got over 2,000 “Not found” URL errors. Pretty much all of these are either posts and pages with “/Twitter” and/or “/Pinterest”. I’ve checked all the social share links on the page and they work fine.
Any ideas you may have to fix this? It’s a very odd error to have!
Thank you!
Sorry! Ignore my comment. Turns out it was two social text links in the footer which weren’t properly linked. I didn’t think to check that!
Hi Ricky,
I’m glad you figured it out!
Eoghan
I’m in very big trouble i have 500 server errors and it is increasing day by day. Please help me to resolve them. Please help me
Hi Arbaz,
I’ll be happy to help if you send me some more info! You can share the details here or just reply to the email that I’m sending you now.
Best regards,
Eoghan
Hi Eoghan,
I have an ongoing problem with WT.
I have number of pages that no longer exist – they tend to be blog pages that have either changed url or been deleted. Some are even noindexed as a whole such as tag/category pages.
However, on an regular basis Google digs them back up and re-presents them as crawl errors. I go through the same process each time: they no longer exist – they have no backlinks, so I simply tellGoogle to ignore them.
A month later, we start the whole thing over again. Aargh!!!
What I have noticed is that the “linked from” tab shows the http equivalent in some cases. Http? We haven’t used plain http for nearly 2 years.
Need to get rid of this crap once and for all – at best it’s annoying – at worst it’s affecting our rankings in some way.
Any ideas?
Hi John,
This is a common issue: Google will recrawl URLs it has discovered in the past again and again, even if they return 404s, as long as it thinks that their content might reappear. There are two ways to get rid of the 404 errors:
1. If you can identify a good redirect target for the URL (one that has the same or very similar content), you can set up a 301 redirect.
2. If you cannot find a good redirect target, you can change the status code of the URL to 410. This is a signal to Google that the content has been removed intentionally. Please note that 410 URLs will still show up as 404 errors in Google Search Console, but it is less likely that Google will continue recrawling them.
As for the info in the “linked from” tab: This is just where Google discovered the URL, so the data is often outdated. It would probably be better if they called it “link last found on” or something like that.
I hope this helps! Please let me know if you have any other questions.
Update: 410 errors now show up as 410 errors in Google Search Console, and are no longer marked as 404 errors.
Hi Eoghan (cool name, mate), thanks for this post – very insightful.
So i am working on a website after we re-launched in April 2017. The dilemma I am having is that we setup around 1137 “Redirect 301 /old-url https://www.website.com/new-url/” but i have a hunch that lots of them are now also resulting in 404s.
What is a convenient/accurate way to see this list of redirects. I tried using http://www.redirect-checker.org/bulk-redirect-checker.php to see that the full old-urls are in fact redirecting fine – but they still result in 404s.
Please assist/advise as you can? Would be much appreciated.
Thanks
Yatish
Hello Yatish,
Thanks a lot for your comment. I normally use Screaming Frog to check lists of URLs. It has a list mode where you can just paste all of your URLs and it then requests them one by one and gives you back all the relevant data, including status codes. The tool you linked to is probably fine to just check the status codes, even if you can only check 100 URLs at a time.
I’m not sure if I understood your question too well. What did the result the tool gave you look like? Did the URLs you pasted result in 404 errors or not? If you send me some more detailed information (here or by e-mail), I can have a closer look at it.
Best regards,
Eoghan
I feel one reason why I see so many 404 is due to someone scraping my site and hosting it somewhere. I deleted thousand and thousand of pages over 6 years ago and Google still tells me I have a 404 for one of those URL’s.
I changed to from HTML to WP, then to SSL. I screwed up and pushed over 20K pages to a wrong directory and deleted my error months ago. GWM still tells me I have all these 404’s from this error. It seems I can never win with GWM tools.
Google panda destroyed my business model, but that’s life.
Does anyone offer paid consulting to get my domain semi error free?
Hi Duncan,
Thanks for sharing your experiences. I’m sorry to hear that you’ve had such bad luck with crawl errors. Hopefully another reader can help you with some consulting.
Good luck and let me know if there’s anything I can do for you.
Hi Eoghan,
One of my sites keep piling up URL errors (hundreds a day)
All the pages displayed have never been generated on the site.
unfortunately , and I don’t know why, the error origin is not displayed on Search Console, so I cannot trace where those 404 are being generated from.
Here’s an example: https://www.screencast.com/t/EYxfGXiIny
What do you recommend I should do, and does that effect the site’s ranking (which gradually decreases)
Hi Tobi,
That sounds strange, especially if we are talking about hundreds of URLs every day. Don’t any of them have any info in the “linked from” tab? Has this problem just started recently or has it been like this for a long time?
I see you set up a 301 redirect for the example URL in the screenshot. Did you do this for more URLs? Did you mark them as fixed? Did it stop the URLs from showing up again?
Maybe, if you send me some more example URLs, I can get an idea of what might be going on. I wouldn’t worry about the site’s ranking too much right now, but this is definitely something you should try to figure out and fix. I’ll help you with it as good as I can, if you give me some more info 🙂
Eoghan
Hi Eoghan,
Thanks a lot for your quick and detailed answer, and more importantly, your offer to help out. This means a lot to me,
Yes, crawl errors keep piling up rapidly https://www.screencast.com/t/qNgKnbWWR
It is an issue we had a few weeks back, we have initially set 301 redirects and marked them all fixed, not entirely sure now doing so was a smart move.
Since then, errors kept back again, though I’m not sure these are the same URLs
Here are a bunch of those new URLs:
https://www.al-ram.net/i22598
https://www.al-ram.net/pli-dramatist-tact-nel/236/12720
https://www.al-ram.net/complicated/lenelenari/louis+r%E3%83%9D%E3%82%A4%E3%83%B3%E3%83%88%EF%BC%91%EF%BC%90%E5%80%8D%E3%82%AD%E3%83%A3%E3%83%B3%E3%83%9A%E3%83%BC%E3%83%B3%E2%99%AA%E3%83%AB%E3%82%A4%E3%83%B4%E3%82%A3%E3%83%88%E3%83%B3
All of which don’t show the origin of the error:
https://www.screencast.com/t/TOhydUah6xd7
Thanks again for your help
Tobi
Hello Tobi,
Thanks for the additional information. This is indeed a mysterious case. I tried to find out where Googlebot might have found these URLs, but I couldn’t find any hints or traces anywhere. I searched for quite a while, but there’s really nothing 🙁
The domain is quite young (about 2 or 3 years) and there has never been another website on the same domain, right? Does the company own any other old domains that it redirected to this domain?
Setting up 301 redirects for the error URLs is probably a good idea, because this way there’s a chance that Google will stop crawling them eventually and the errors should stop showing up in your reports immediately.
There are two possible scenarios why these URLs might be crawled right now:
1. The URLs that are being crawled right now have been in some scheduling bucket for Google’s crawler (for whatever reason) and are being crawled right now. Setting up 301 redirects for all error URLs will help, because the errors won’t show up again and Google will probably stop crawling the URLs once it realises that the 301 redirect is there to stay.
2. The URLs are not old, but are constantly being generated right now at a source that we haven’t been able to identify yet. In this case, we should really try to find out where the URLs are coming from and find a way to stop them.
I suggest that for now, you continue setting up 301 redirects for all new errors that show up and keep an eye on the number of new errors. If they go down, that’s fine, and if not, let me know and we can have an even closer look at the problem to try and identify where these URLs are being generated.
Also, try to check all of the errors for “linked from” information. This could be very valuable for solving the problem. Did you know that you can export all errors at once via the API? Here’s a link you can use to try it out: Google APIs explorer. That way you don’t have to check every link manually.
I hope this helps for now! I’m sorry I haven’t been able to fully solve the problem yet.
Let me know how it goes!
Eoghan
Thank you so much once again!
I have exported all errors , yet non show the links origin ( I have checked that this field is included in the report).
Will go on and 301 those new errors, which are now over 2000, and rising at 200+ a day.
Waiting now for the company’s answer about their domains,
will update you later on this week
Thanks again for taking time trying to resolve this, your devotion in beyond any expectations I had.
Hi Tobi,
OK, let me know how it goes!
Eoghan
This article cleared up a lot for me and enabled me to clean up my site errors. I had always wondered if having the errors affected my SEO and if cleaning them up would help.
Thanks, Larry!
Hi Eoghan,
I have been working on the 404s that show up in the Google crawl errors at least once a week and I notice that several keep showing up. These are all URLs that have to do with products that have been deleted from not only the website, but also the sitemap- I mark them as fixed and some keep coming back. About a month ago, I set up an Excel worksheet so i could keep track. One in particular has shown up 4 times in the last month- I know it is totally gone from the site and the sitemap. It also does not exist on any of the internal pages that Google says it does.
If the URL is showing up in an external URL, I create a 301 and that usually takes care of it, although I created a 301 on a particular URL one day and it showed up again 2 days later… is there a lag time where Google finally sees the 301?
I was told that Google doesn’t like a lot of 301 redirects… is there a limit on how many redirects a site should have? Should I go in and remove some of the old redirects or is it okay to let them ride?
Dirt E. Harry
Hello again 🙂
Some 404 errors will keep showing up again and again, even if they are not linked internally or externally any more. I need to update the article to make this clear.
When you set up a 301 redirect, the URL should not show up as a 404 error again. The only explanation I can think of for the error that showed up two days after you set up a 301 redirect is that the URL was crawled shortly before you set up the redirect but was only included in the report a few days later. Most of the Search Console reports are not updated in real time.
There is no limit to the number of redirects a site should use, but it is important not to abuse the feature either. When you set up a redirect it should be justified, which means that the content of the old URL should be found on the new URL (or at least a similar version). It is not a good idea, for example, to redirect loads of old URLs to the home page.
One problem that can arise with lots of redirects is that your htaccess file simply gets too big, which has a negative impact on the load time of your pages.
If you want to delete old redirects, make sure they are not needed anymore, meaning the redirected URLs are not accessed by users or bots any more.
I hope this helps!
Hi Eoghan,
I really appreciate your answer… makes total sense.
In regards to the htaccess file, I have about 475 redirects to date. My site is not yuuuuge nor is it a dinky site either- it weighs about 807MB
Airguns are as bad as automobiles- the manufacturers are constantly coming up with new models and discontinuing old models. One thing I thought about doing is turning off the Availability, Featured, On-Sale switches and the Add to Cart button on discontinued items and adding the term “Unfortunately this Model is now Unavailable” to the item description.
If there is a bookmark or an external site link to the item, the end searcher will know exactly what page to go to to find the latest/greatest heart throb (if they know anything about airguns) and the bot won’t know the difference.
The result would be tons of time saved deleting the item(s) from the site, sitemap and creating re-directs and no more 404s- not to mention simply turning switches back on if the item is resurrected and becomes available again… what do you think?
Dirt E. Harry
President and CEO
http://topairgun.com
Yes, that sounds like a good plan! Maybe think about adding some useful links to similar products to the pages of products that are currently unavailable. Here’s an example of a product page for a discontinued product that has a link to the newer versions of the product: https://www.ecom-ex.com/products/archive/communication/ex-handy-07/
Thanks Eoghan!
You have just saved me another Yuuuuge chunk of time! Love it when a plan comes together,
Dirt E. Harry
President and CEO
http://topairgun.com
Not done this because I don’t run any e-commerce sites, but another option is to leave the old page in situe and simply include a message and a link to the new product. Don’t just leave the searcher to find their way.
If the products are too similar it might not be a good idea but if they are different enough not to be seen as duplicates it could be an option.
You’ll need to turn things off though to ensure items not accidentally purchased or seen in searches but this can be automated based on the status=”discontinued”. Get a coder in to make the appropriate changes to the template and make it as easy as setting a flag.
I am getting 4 internal server errors 500 in my search console.It is with some attachment.When I click on the link the page opens properly but when I do fetch with google .It says unreachable.Please help me with this problem
Hello Indrani,
Thanks a lot for your comment. I would need some more info to help you with this one. If you like you can send me an e-mail and I can have a look.
Best regards,
Eoghan
hi
i have a problem in crawl error in google webmaster.i removed error but 2 or 3 days after that ,i see a lot of errors in this list but i dont move any page.
please help me
Hi Mehrnoosh,
I will need some more info to help you with this. I will send you an e-mail.
Hi Henn,
Awesome Dude… This Article helps to remove my all Crawl error from Web master Console.
Thanks
Hi Shailesh,
I’m happy to hear it was helpful to you!
Eoghan
Hi Eoghan,
After reading through your informative post I wonder if you can advise me on something. I’ll put as much detail as I can.
I recently had a major overhaul of my site, built with WordPress, and I’m getting a lot of odd 404 crawl errors. I did the following when relaunching the site:
1) Changed permalink structure, setting up 301 redirects for each page, from old link to new.
2) Once site was up and running, I then had SSL added.
3) I then replaced all the 301 redirects again, to point from old links to new https versions of the pages.
This was all done for the purpose of old backlinks dotted around the web and I also went through the site and manually updated all internal links to point to the correct https URL’s.
I then submitted an XML sitemap to GSC. There wasn’t one previously as I had not done this with my old site.
However now, as Google starts to crawl the site, I am getting loads of 404 errors for what look like the old links, but they have https at the start.
1) Essentially I had old URL’s like this:
http://www.example.com/blog/2015/05/10/postname
2) Now I have new URL’s that looks like this:
https://www.example.com/postname
3) GSC is giving me 404 errors for a hybrid of the old and new URL’s, showing old linking structure but with SSL, like this:
https://www.example.com/blog/2015/05/10/postname
I should point out, if I manually type in one of my old URL’s it does direct to the new page and, if I do a Google search and click on an old link, it also redirects to the new page. So I know my 301 redirects are all good.
So these third hybrid URL’s that Google can’t find in GSC, technically never existed as I never had SSL with my old site permalink structure. I also double checked my sitemap that I submitted and that only contains the correct, new URL’s, it doesn’t have any incorrect ones in there.
My questions is, should I just ignore these errors for the hybrid links as they have never been real pages. If I shouldn’t ignore them, how do I remove them? Setting up 301 redirects seems counter intuitive as I’m redirecting from a page that never existed so nobody would ever find a link for these hybrid URL’s ‘out in the wild’.
I hope that all makes sense :/
Thanks in advance for any help!
Hello Richard,
Thanks a lot for sharing this interesting case. Everything you explain makes total sense, so it looks like you did a very good job with setting up the redirects.
Still, it is slightly worrying that Googlebot is accessing your old URLs with https although there shouldn’t be a redirect pointing to them. Have you checked the “linked from” tab in the crawl error reports? You can find it by clicking on each URL in the report. The reason why I’m worried about the errors is that if Google is crawling “wrong” new URLs, they might not be crawling the right ones at all, which would be a problem. This is why it would definitely be a good idea to find out how Google found the wrong URLs.
If you like, you can send me an e-mail with your domain name and some examples of URL errors so I can have a closer look.
Best regards,
Eoghan
Geez thanks hey. I was really starting to loose my marbles with the returning 404 problems. Best thing really is to redirect. Google doesn’t seem to know what’s still on and what’s not, so rather than keep trying to contact webmasters, etc. – REDIRECT.
Thanks again,
Faniso
I’m happy to hear it helped. And thanks for the update!
Hi Eoghan,
Thanks for putting this post together. Have you ever seen a bunch of 404 errors that end in an /@ sign after the permalink? I am wondering if this is an error that originated on a social media platform like twitter or instagram.
Here is how it looks in the crawl errors: http://example com/get-404-results/@example
In this example, the permalink minus the @example works perfectly to a live page. I have like 400 of these.
I did recently move the site to https from http but I don’t think that has anything to do with it.
I’d love to hear your thoughts.
Thanks,
Paul
Hi Paul,
Thanks a lot for this interesting question. I have never seen a case like this, but I could imagine it happening if, for example, you tried to link to a Twitter profile on all of your pages and entered href=”@example” instead of href=”https://www.twitter.com/example” into the link tag. Crawlers or browsers might interpret this as a relative link and add the URL of the current page to the URL path. This would then cause lots of crawl errors just like you described.
Is the “@example” part the same in all URLs? Have you checked the “linked from” information in the crawl error reports to see where the false URLs are linked from? If they are linked internally, have you checked your source code for “@example”?
I hope this helps. If you like, you can send me some more info on this and I will have a closer look.
Hi Eoghan 🙂
Can you please help me figure this out?
Here we go! I had an HTML website years ago. I had added the site to the Google Webmaster (Search Console now). Then several months ago I removed all pages from my website and now for installed a WordPress site. The new XML that I have added to Search Console is generated by JetPack (By WordPress). And yet I still 404 URL errors of the old HTM or HTML files! How’s that even possible that the new generated XML which only recognize WordPress URL parameters detects old deleted HTM links which were never there for almost 4 months?
Is it because of the fact that Google itself still stores all those links or because of my XML generated file? How can we delete all missing URL from Google for good? And if it is 301 can you please tell me how can we redirect *.htm and *.html to new pages of the website?
Sorry for the long comment!
Thanks,
Hello Shahab,
your old pages are probably still being crawled because Google still has them on the list of URLs they have discovered on your website and that they have scheduled for crawling. They won’t crawl them as often as the pages that are working, but they will check every now and again to see if they still return an error or if they are back up.
In order to get rid of the crawl errors in your GSC reports, you should indeed redirect all of the old URLs. I guess the easiest way to set this up would be using a WordPress plugin like this one (I’ve never tested it, but it looks decent). Alternatively, if you’re familiar with editing your .htaccess file, you can choose this option. The Yoast SEO plugin has a handy .htaccess file editor, but you’d have to write your rewrite rules yourself (or find another tool that generates them for you).
If you have versions of URLs ending in htm and html, you can add each one of them seperately and define a redirect target that contains content that is similar to the content on the old page.
Please let me know if you have any further questions.
Hi again,
Thanks a lot for your detailed reply. Really appreciated it 🙂
“They won’t crawl them as often as the pages that are working, but they will check every now and again to see if they still return an error or if they are back up.”
How long would it take for Google to let go of the broken links? And how come they aren’t deleted yet? Is there a timeframe? Can’t we tell Google that these pages are removed or personally delete them from GSC?
And if I want to do a 301 redirect could I do that for all htm files? Cause I don’t have an exact list of links. Could I use *.htm?
And finally what would happen if I don’t do anything? Bad for SEO?
Thanks a lot,
Hello Shahab,
Thanks a lot for your interesting follow-up questions.
I don’t know when and if Google stops crawling URLs that return an 404 error. If they are linked from somewhere, they will definitely get crawled again and again. If not, you’d expect them to stop at some stage, but I’ve seen old URLs being crawled for many years after the pages stopped existing.
Yes, you can “tell” Google that you removed the URLs intentionally: A 410 status code instead of a 404 status code would do the job. With a 410 status code, it is more likely that Google stops crawling the URLs, although it’s not guaranteed. And one thing that can be confusing about this is that the pages will still show up as 404 errors in Google Search Console.
You cannot “delete” URLs from the crawling schedule yourself in GSC. There is a function to request removal of a URL from the index, but this is only temporary (for 90 days) and it’s not the same as preventing it from being crawled.
You could probably block URLs via your robots.txt file, if you really don’t want them crawled, but I don’t think that’s a useful measure here.
And yes, you can create a redirect rule in your htaccess file that redirects all URLs that end in “.htm” to a certain target, but this isn’t really advisable either. What I would recommend here is to export all 404 errors from GSC, mark them as fixed, and set up a redirect for each error URL to an equivalent target. I guess in most cases you’ll still be able to figure out what content was on the old page and find a fitting redirect target.
If you don’t do anything, this will probably not do you much harm, but you might lose some potential. If, for example, some of your old pages have backlinks from other websites, you should definitely redirect them to targets that have similar content.
I hope this helps! Let me know if you have any other questions.
Thanks a lot for your great answer 🙂
Just some final questions:
What is the correct redirect for *.htm? Just put it there or something else?
Maybe I have to use it, because I saw that old htm urls are about 146. And it is probably a little time consuming. I would like to do them individually of course.
Thanks a lot again 🙂
Hi Shahab,
I’m not very familiar with actually creating htaccess files, but this should help: http://stackoverflow.com/questions/3220377/htaccess-redirect-if-url-contains-a-certain-string
Please do let me know if you have any further questions!
Hi Eoghan,
I added a new product to my site yesterday 5/5/17 and added it to the sitemap and published. Today 5/6/17 I embedded a video from U-Tube in the same product. Do i need to go in and update the product date in the sitemap and republish because of the added html code? I know I have to update if I change more than a couple of words in the text or content of a given product.
Dirt E. Harry
Well, if you really want everything to be 100% correct in your XML sitemap, the “lastmod” value should probably accurately reflect the last time the page was changed (no matter how small the change was). But if you don’t keep the “lastmode” value up to date, it’s not a problem, because Google and other search engines don’t really pay attention to it (which also means that keeping it up to date won’t really help you in any way).
Here’s some info on how Google deals with it: https://www.seroundtable.com/google-lastmod-xml-sitemap-20579.html
XML sitemaps help Google discover your URLs, but whether or not and how often a page is crawled and re-crawled after it has been discovered depends on a number of factors and the “lastmod” value probably is one of the less important ones.
I hope this helps! Please let me know if you have any further questions.
Thanks Eoghan- this will save me a lot of work!
Hi Eoghan
I have come across your blog and it is very helpful.
Our website has recently been hacked and our IT guys are still trying to clear up it up for the last 2 months.
I would really like to get a second opinion on what we need to do to clear the crawl errors.
Would you be able to help?
Thanks!
Hi Charl,
Sure, just share your questions here or send me an e-mail. I’ll be happy to give you my opinion.
Eoghan
Hi Eoghan,
I must say that your Rebi,ytics.com comments and posts have been extremely interesting and informative- I have learned a great deal! Needless to say your site is now bookmarked.
The person that has been my SEO consultant for the last 7 or 8 years is discontinuing services at the end of this year (2017).
Therefore, i am looking for a person that has the ability to:
Write compelling content using key words and phrases that make sense to optimize my category pages.
Monitor the sitemap crawl errors and fix them in a timely manner.
Stay abreast with Google and make the necessary changes in the back office of the site to keep it up to date for optimum performance.
Pro-actively suggest any additional site branding, design appearance and navigation ideas to increase customer purchasing and loyalty.
Increase customer traffic and hit to sales ratios.
If you or any of your commenters know of such a person please let me know,
Dirt E. Harry
Hi Dirt E. Harry,
Thanks a lot for your comment. I’m glad my articles have been helpful. Right now, I don’t know of anyone who is available for SEO projects, but I’ll just leave this comment here for everyone to see. Good luck with your search! And just let me know if you have any further questions.
Hello Dirt E. Harry,
I run a website agency where our main focus is SEO, website design and development. We are SEO certified by Google, meaning that we have passed all the exams for Google Analytics and Google AdWords with a score of over 80%.
We are sorry to hear your SEO consultant has chosen to discontinue his services but we would be more than happy to help you out.
Feel free to visit our website and get in contact to discuss things further – https://laceytechsolutions.co.uk
Ben Lacey
Managing Director
I will just leave this here, but I want to make it very clear that there is no such thing as “SEO certified by Google”. Passing the exams for Google Analytics and Google AdWords is a nice achievement, but it does not prove any SEO skills whatsoever. Also, Google does not certify SEO practitioners in any way. Please be very careful with claims like this.
Hi,
My bIog site is in WordPress. I am getting 404 for the links. These all come when I publish my posts in facebook/ twitter and crawler shows facebook/twitter.com appended at the end.
My site map looks clean.
Can you please suggest how to fix it?
Thanks,
Sup
Hi Sup,
Could you send me an example of a URL with a 400 error (by mail if you like)? Do you use some kind of plugin to share your blog posts on Facebook and Twitter?
I’ll be happy to help you, but I need some more information.
Yes! Mine does this as well. I don’t think it’s hurting anything, but it’s highly annoying and difficult to weed throw to see actual errors. They are for ALL social media (Facebook, Pinterest, Twitter, and Instagram)
These are just a few (I have 100+ at the moment). They are all 404.
tag/munich/www.facebook.com/AliciaYarrishPhotography
tag/engagement-session-tips/www.facebook.com/AliciaYarrishPhotography
tag/engagement-session-tips/www.pinterest.com/alicia_yarrish
tag/powersheets/www.instagram.com/aliciayarrish
tag/powersheets/www.pinterest.com/alicia_yarrish
tag/powersheets/www.facebook.com/AliciaYarrishPhotography404
destination-film-photography/www.facebook.com/AliciaYarrishPhotography
destination-film-photography/www.pinterest.com/alicia_yarrish
tag/munich/www.instagram.com/aliciayarrish
tag/munich/www.pinterest.com/alicia_yarrish
Hi Alicia,
I had a quick look at your page and this is a pretty weird case. I think your problem might be related to the fact that some of the social media icon links on your page don’t have “https://” at the beginning. Google’s crawler should normally be able to recognise these links as absolute links anyhow, but here, for some reason, it looks like it’s interpreting them as internal, relative links.
To fix this, I recommend you add “https://” to all links pointing to your social media profiles.
Please let me know if this works out for you!
Hi Eoghan Henn,
Very helpful information, keep it up..
I am getting errors on my search console which are not exist on my website and server. Actually those url pattern were exist more then a year ago. Lot of times I told to my developer to check on my server but he said those are not there now. I marked as fixed several times but again and again those errors are showing up. As website platform changed to php still google search console is showing .aspx errors too.
Please give me some suggestion to solve these errors.
Thanks in advance..
Hi Raja,
Thanks a lot for your comment. Have you tried to change the http status code that these old URLs give back? The best option would probably be to 301 redirect them to similar targets. If that’s not possible, you could change the 404 status code to a 410. This can help with getting the old URLs removed from the index quicker.
Marking errors as fixed does not have any influence on Google’s crawling. It is just a useful tool for structuring your error reports better.
Please let me know if you have any further questions.
Hi,
Thank you for your article. We are a job listing website. Vacancies on our website expires after some time, so robot finds a lot of “not found” pages due to natural expiration. In our case, how should we handle it?
Hello Vadim,
Thanks a lot for your comment. When you deliberately delete a page from your website, it is best to serve a 410 status code instead of a 404. The difference is that 410 actually means “content deleted” while 404 only means “content not found”. Important side note: Pages that serve a 410 status code currently still appear as 404 errors in Google Search Console. Don’t let this irritate you.
In terms of user experience, think about what you want to display on the error page for expired job vacancies. I guess it would be more interesting to display a message about the vacancy having expired (including a call to action for further navigation on your website) rather than a standard “page not found” message.
Here’s a good article about your options when you remove pages from your website (the very last part about collateral damage is WordPress-specific, so you can ignore it): https://yoast.com/deleting-pages-from-your-site/
I hope this helps! Let me know if you have any further questions.
Hi Eoghan,
very helpful and complete information. Thank you so much!
I am happy to write the 100th comment, for this very helpful page!
I’ve tried to scroll all 99 previuos comments and perhaps I’ve missed it, but what about URLs with not found errors that have NO linked from tab ? What does it mean? Where do they come from? A sitemap xml?
Hello Alessandro! Thanks for writing the 100th comment 🙂 When a URL is included in an XML sitemap, this information also shows up in a tab next to the “linked from” tab. When there is no “linked from” tab, this simply means that there is no information available on the source of the link. This often happens with very old URLs that are re-crawled again and again. Sometimes, Google also makes up URLs itself, like (for example) m.domain.com or domain.com/mobile (just to check if there is a mobile version). These wouldn’t have a “linked from” tab either.
Hi Eoghan Henn,
A page in the sitemaps already indexed. But now I found this
HTTP Error: 403 “When we tested a sample of the URLs from your Sitemap, we found that some URLs were not accessible to Googlebot due to an HTTP status error. All accessible URLs will still be submitted.” for this page.
Could you please advise? Thank you.
Hello Annie,
in case of an error like this, I would recommend to crawl all URLs in your sitemap using a tool like Screaming Frog. If some of the URLs return errors, you should check if they should be removed from the sitemap (because they aren’t supposed to be in there) or if the pages need fixing (because they should be working but aren’t). If there aren’t any errors, you can resubmit the sitemap in Google Search Console and check the error report. Sometimes, this type of error is just temporary.
Please let me know if you have any further questions.
Thanks Rebel
Actually, I tried to Fetch as Google but It turns to “error” instead of “complete” as usual. I don’t know to do next. I have Tried to install Scream Frog on my PC but it won’t run. Today this page disappear when I search the keyword rank from this page (previously on page 2, now I cannot see it on top 200 )
Could you please help
Thank you.
Hello Annie,
Can you tell me which page we are talking about? I can have a look to see if I can identify the problem.
Best regards,
Eoghan
Hi Eoghan,
I recently redesigned some our our site using an administrator login (we only have relatively limited access).
Part of my redesign included removing some pages and replacing them, as well as changing a number of URLs.
If I have not entered a 301 redirect before deleting, is it still possible to do so? Is it possible to do this through HTML source or similar, as we do not have access to hidden files from my knowledge.
Kind regards
Harry
Hi Harry,
Sorry about my late reply! Yes, you can (and should) still implement 301 redirects, although it would have been best to implement them immediately after you changed the URLs.
There are several ways to implement 301 redirects and your choice depends on your technical circumstances. Here’s an overview that I find quite useful: http://www.webconfs.com/154/301-redirects-how-to-redirect-your-website/
Let me know if you have any further questions!
Hi Eoghan,
My site gives error 500 (internal server error) when clicking from a google search result. If i search for autismherbs on google and click on any of the links to my website, i get error 500 (internal server error) but if i click the address bar and hit enter, or click a link to autismherbs.com on any other site, it works just fine.
I have check error log and it show:
[core:debug] [pid 992574] core.c(3755): AH00122: redirected from r->uri = /index.php, referer: https://www.google.com/
I have try deleting .htaccess file but the problem still occur.
Any solution for this problem? What codes should i check?
Hello Anne,
First of all, sorry about my late reply. I’ve been having trouble keeping up with the comments here.
I checked your website and this is indeed very strange behaviour. It seems like your pages return 500 error codes for the Googlebot and for visitors that click on a Google search result. The exact same URLs work fine for other user agents and referrers.
I’ve spent some time trying to figure out why your website behaves this way, but I don’t have a good idea yet. Can you check with your hosting / developers if there is any setting that determines different response codes for different user agents or referrers?
Please let me know if you have any further questions.
Hi Eoghan. Wonderful article on crawl errors. I’m getting a whole lot of “no sentences found” news errors but when I test the article in news tool I get a success. How does one fix this? Also when I do a fetch and render it only renders the bot view. The visitor view is blank.
Hello Nikkhil,
Thanks a lot for your comment. I’m very sorry, but I do not have a lot of experience with Google News. As far as I know, the error “no sentences found” can be triggered by an unusual formatting of articles – too few or too many sentences per paragraph.
If Google has problems rendering your page, there might be other technical problems. You should definitely check this out. Does the problem occur with all articles or just the ones that also have a “no sentences found” error?
I’m sorry I can’t give you a better reply. Let me know if you have any additional questions.
Eoghan
Hi Eoghan,
Thank you for the response. Our site is built on a MEAN stack. We use pre-render IO for the google bot to crawl since the site is in Angular js. There are about 600 articles in the error list with no sentences found. All of them have content! eg http://www.spotboye.com/television/television-news/after-sunil-grover-is-navjot-sidhu-the-next-to-quit-kapil-sharma-s-show/58d11aa18720780166958dc3
Hello Nikkhil,
The Google Cache for the example you provided looks fine. I’m not sure if prerendering is still the preferred way of dealing with Angular JS websites though, as Google is now a lot better at rendering JavaScript. Also, I do not know if the Google News bot treats JS differently (although it shouldn’t). The fact that the visitor view in the fetch and render report is not working is something you should probably dig into deeper.
Sorry again for not having any solid responses for you, but this might help you with your further research. Let me know if you have any other questions!
Eoghan
I’ve got a problem and do not know what to do
Google appears some of my website pages in search as (https) but i dont have https on my site
I do not want https just simple http
plz help me
Hello Mido,
Thanks a lot for your comment. My first idea was to suggest that you redirect all https to URLs to their http equivalents, but that would probably still cause problems for most users, if you don’t have a valid SSL certificate: A warning would be displayed before the redirect is processed. I’m not sure how the Google bot would deal with a situation like this (if it will process the redirects or not), but a missing SSL certificate will most likely cause problems in other areas.
I think your best bet would be to switch to https completely. This is something all webmasters should be doing anyhow. You can get a free SSL certificate from Let’s Encrypt: https://letsencrypt.org/
Here’s a great resource for making sure you get everything right from an SEO perspective when switching to https: http://www.aleydasolis.com/en/search-engine-optimization/http-https-migration-checklist-google-docs/
Please let me know if you have any other questions.
Eoghan
Hi Eoghan
Great article! On or around Feb. 19, 2017 our webmaster account saw a spike in 500, 502, 503 errors (‘server error’) and our programmer checked and found an issue with database and got it fixed. Accordingly we checked all the 500/502/503 errors as fixed in webmaster. However, soon thereafter, webmaster again began receiving server errors (mostly 502s, some 500s) and the number of errors keep climbing steadily everyday. We’re not sure now why we’re still getting the server error messages and I’ll be grateful if you can help out in this regard.
PS – ever since we started getting the server error messages, our traffic got badly hit as well as overall search rank positions.
Hello Surojit,
Thanks a lot for your comment. If the errors keep coming back after you marked them as fixed, it looks like the issue with the database was not the only cause for the errors. There are probably more issues you need to fix.
You can export a list of all errors through the Google Search Console API Explorer including information on where the URLs that cause the errors are linked from. This might help finding the root of the problem.
Feel free to send me some more information so I can have a closer look.
Best regards,
Eoghan
Good Day,
I need help with all my crawl errors. I will pay you in advance if you could help me to clear all my crawl errors.
Kind Regards
Johan Watson
Hello Johan,
Thanks a lot for your comment. I will help you for free if you provide me with more info.
Best regards,
Eoghan
Hi there! Thanks for this post.
I’m not sure if this question has been asked already.
I recently went into webmaster tools to check for crawl errors. Under the Smartphone tab, I noticed that most of them were for pages with either a m/pagename.html or mobile/pagename.html.
We have built these pages without any sub-directories. So you will not find
http://www.victoriafalls-guide.net/mobile/art-from-zimbabwe.html or
http://www.victoriafalls-guide.net/m/art-from-zimbabwe.html
Only such pages as http://www.victoriafalls-guide.net/art-from-zimbabwe.html
What am I missing here?
Hello Faniso,
I have seen a similar problem in several other Google Search Console properties. Sometimes it is very difficult to understand where the Google bot initially found the URLs.
Have you checked the “linked from” information in the detail view of each error URL? This might help you find the source of the link, but often there is no information available.
There is also an unconfirmed but pretty credible theory that the Googlebot just checks the m/ and mobile/ directories to see if there is a mobile version of a page when it’s not mobile-friendly: https://productforums.google.com/forum/#!topic/webmasters/56CNFxZBFwE
I recommend you mark the errors as fixed and set up 301 redirects from the non-existent URLs to the correct versions, although the redirects are probably not even necessary.
I hope this helps!
Hi Eoghan
I’m having a unresolved issue with the ‘link from’ source being pages that haven’t existed for up to 10 years.
All from recent crawls, both link and ‘linked from’ are asp urls that haven’t existed for a decade. In that time, the site (same root url) underwent three hosting company moves and several complete site rebuilds (no css, scripts, etc. were carried over).
I can see external sites keeping these old urls in their archives, etc. but how does google come up with phantom internally ‘linked from’ urls that just haven’t existed for this amount of time? Have you any thoughts on this perplexing problem Thanks!
Hi Keith,
I’ve encountered the exact same problem with several different websites.
Here’s my explanation: I’m pretty sure that the “linked from” info is normally not up-to-date. The info that is displayed here is often from previous crawls and it is not updated every time the linked pages are crawled. That would explain why, even years later, pages still show up as linked from pages that no longer exist.
Also, I have noticed that these errors often don’t come back after you have marked them as fixed for a couple of times and made sure that the pages really aren’t linked to from anywhere any longer. These errors normally won’t harm your SEO performance in any way and thus aren’t a reason to be worried.
I hope this helps! Please let me know if you have any other questions.
Eoghan
Thanks very much for that, Eoghan. Very reassuring that, at least, I’m not losing my mind. I will persist with the mark ’em fixed tactic.
Cheers! Keith
Eoghan,
I have the same problem and it’s refreshing to hear what you say.
However, I am concerned about marking as fixed unfixed pages, cause I’ve found this note in Google’s official knowledge base:
“Note that clicking This issue is fixed in the Crawl Errors report only temporarily hides the 404 error; the error will reappear the next time Google tries to crawl that URL. (Once Google has successfully crawled a URL, it can try to crawl that URL forever. Issuing a 300-level redirect will delay the recrawl attempt, possibly for a very long time.)”
Thanks for helping us!
Hello Alessandro,
I would normally only recommend marking an unfixed error as fixed to check if it shows up again. In any case, I would recommend redirecting the error pages (which would mean fixing it). Often, these errors are nothing to worry about anyhow and the behaviour of the error reports in Google Search Console does not always make sense.
I Hope this helps 🙂
Hi. Few days ago my website (a blog) started to receive so many “calls” from googlebots and when I asked to Google why this is happening they answered that this is normal and that I should down th crawl frecuency at my webmasters tool. The big question for me is: how down is down? Do you have any suggestion? Thanks!
Hi Andrea,
Are the requests from Google causing you any problems with your server? If not, I would not recommend you change anything.
If your server is indeed having trouble with the number of requests from the Google bot, I would first consider the following options:
– Check if your server is performant enough. Normally, there shouldn’t be a problem with normal crawling by Google and other bots.
– Check if the requests are actually coming from Google, or from another bot that pretends to be Google. You can compare the numbers from your log files (or wherever else you found that you were receiving lots of hits from the Google bot) with the Crawl stats report in Google Search Console (click on Crawl > Crawl stats in the left navigation).
All in all, I would really not recommend to limit the crawling frequency for the Google bot.
I hope this helps! Let me know if you have any other questions.
Hi there,
Few days ago , most of my website has disappeared from google search results . At the same time , google analytics has registered sharp decline in organich ( search engine ) visitors . Total daily visits dropped from 300 to 100 within about 3 days . Upon checking with webmaster tools , i get hundreds of “404-not found” errors . However what really bothers me is , that those URLs DO EXIST and they DO work ! I suspect that somehow the dynamic URL parameters are to blame . But so far , it has worked just fine … the website is written in several languages and ( being eshop ) is denominated in several currencies . Those languages and currencies are selected by $_GET parameters . To prevent people from trying to browse the pages without selected language or currency , the website automatically fills in those paramenters in case they are not present . Example :
http://www.eurocatsuits.com/index.php …..redirects to : http://eurocatsuits.com/index.php/?la=en¤cy=EUR
in “fetch as google” , the index.php gets “redirected” status …. of course , it redirects to index.php/?la=en¤cy=EUR …… but the “index.php/?la=en¤cy=EUR” gets “not found” status …. however , in the browser the page works just fine ….
any ideas ? … please help … thanks !
Tomas
after sleepless night i found out , that .htaccess was to blame …i will make new one later , but for now i deleted it altogether and everything works just fine ….
Hello Tomáš,
I’m glad you managed to fix this.
One general tip: You might want to get rid of those language and currency parameters in your URLs. They are not very search engine (or user) friendly.
Please let me know if you have any additional questions.
Best regards,
Eoghan
I just received an email alert from GSC about a large increase in soft 404 errors. Turns out spammers from .cn domains are linking to searches on my WordPress blog for queries in another language (I assume Chinese), and the numbers have gone up almost linearly every day since Jan. 5th when it started. I suppose I could block search links from .cn domains but do you have a better idea?
Hello Jacob,
First of all, sorry about my late reply. I haven’t been able to keep up with all of the comments these last few days.
Thanks a lot for sharing this interesting case, even if it sounds very annoying for you. Have you already set all of your search result pages to “noindex”? This is something every website should do anyhow, in order to avoid uncontrolled indexing of search result pages. You can use the Yoast SEO plugin to set this up.
It might not stop the pages from showing up as soft 404 errors, but at least it will let Google know that you do not want these pages indexed. It should be enough to make sure that these pages don’t harm you.
Another thing you might want to do is check the domains that are linking to you and see if they might be potentially harmful. It might be a good idea to use the disavow tool to exclude these links. Please note though that I am not an expert on link removal and cleanup and that you should do more research before deciding about this issue.
Please let me know if you have any further questions.
Best regards,
Eoghan
No worries, life is busy, just happy you replied at all 🙂
Yes, my search pages are noindexed, via the AIOSEO WordPress plugin.
I tried clicking through to one site, it’s a blog with a mass of links, each mostly pointing to other similarly-formatted garbage sites. The links to my site is gone and as far as I can tell, the site is being regenerated on the fly (or regularly) while replacing old links with new ones, spamming as many sites as possible.
Looks like they might just be after visits from curious webmasters like you so they can generate some ad revenue off them. Similar to the ones that spam Google Analytics accounts with referral spam.
Do any of these links show up in the “Search Traffic > Links to Your Site” report in Google Search Console?
The links probably won’t harm you if they disappear again that quickly, but I guess you should keep an eye on it. As for the crawl errors… If you mark them as fixed they probably won’t show up again if the links disappear.
I hope this helps and I hope that those spammers won’t bother you much longer.
Hi Eoghan,
I’m actually having the same issue that started right around the same date as Jacob.
I received over 200 “soft 404 errors” from search URLs that are “linked from” a really strange search results page on my site that doesn’t exist.
There are also a lot of very strange links from a few .cn websites.
Hopefully this makes sense, I’m not familiar in dealing with crawl errors. Any help or guidance would be greatly appreciated.
Thanks!
Hi Kevin,
First, I would recommend you mark the crawl errors as fixed in Google Search Console. You find this option in the crawl error report right above the detailed list of crawl errors.
If the errors don’t show up again after that, you don’t have to worry about them any longer.
If they do show up again, you’ll have to dig a bit deeper. Feel free to get back to me if you need any support with this.
Best regards,
Eoghan
hello sir this my website kindly help me my search console analytical is not working what is problem can you help i cant see any error for this http://www.subkuchsell.com website
Hello Ali,
I am not sure if I can help you with this question. If you do not see any data in Google Search Console, it might be because you only verified your property recently. It takes a few days until data is shown.
If you do not see any errors, it might also be related to the fact that there simply aren’t any errors.
Make sure you verify the right website version. The URL you enter for your Search Console property should be http://www.subkuchsell.com/.
Let me know if there is anything else I can do for you.
Eoghan
Hey Eoghan,
thanks for sharing. For an e-commerce website, my friend suggest a way to deal with 400 pages.
1.download the search crawl error-404,
2.past the 404 url in to txt file,
3. put the 404.txt in the ftp,
4.submit 404.txt to Add/Test Sitemap
google webmaster–crawl–sitemap–Add/Test Sitemap button
http://www.xxxxx.com/404.txt
since we are going to dele around 4k url recently,how to deal with it very important
Fix 404 errors by redirecting false URLs or changing your internal links and sitemap entries.
for this, steps as followings, right?
1. 301 redirect all 404 error url to the homepage,
2. update the sitemap
3. sumit the sitemap,
which one is correct?
Yes, this is how I would suggest to do it. Just think about whether there are better targets for your 301 redirects than the home page. I would not recommend to just redirect every old URL to the home page without thinking about it. For most URLs, there will probably be better targets than the home page.
Hi leanin,
I am not sure why your friend recommends these steps, but this is not a solution I have ever heard of.
hi sir
(i have bad english)
can u help me fix this issue?
my site has been block cause the yandex bot (i don really understand how this work)
http://imgur.com/a/W1JKK
i register my site at yandex , i couldnt find the crawl setting
http://imgur.com/a/297Mu
what should i do ?
Hello and thanks for sharing this interesting case. Let me try to help you, although I have never heard of a case like this before.
Yandex has a question in the FAQ section for exactly this problem: https://yandex.com/support/webmaster/robot-workings/robot-workings-faq.xml#server-overload
The crawl-delay directive in the robots.txt file (which Google, on the other hand, ignores btw) should help with this: https://yandex.com/support/webmaster/controlling-robot/robots-txt.xml#crawl-delay
Now I believe there are some more important things to consider here:
1. If your server or hosting provider can’t handle normal crawling by search engines, you need another server or hosting provider.
2. A bot that crawls your site and claims it’s the Yandex bot could be a “bad bot” mimicking the Yandex bot. These bad bots will just ignore your robots.txt file and keep crawling your page. Here’s another questions in Yandex’s FAQs about exactly this problem: https://yandex.com/support/webmaster/robot-workings/robot-workings-faq.xml#checking-yandex-robots
This is all I can come up with for now. I hope it helps and please do let me know how it goes and if you have any other questions.
Hello mirotic,
Are you using a wordpress platform? If yes, then check whether you are using SEO search term tagging 2 plugin…If yes, then simply deactivate the plugin…its recent updates has bugs…o showing such errors….i have faced a similar situation in my site….deactivating the plugin has solved my problem…try this out..
Hello Sir!
I just built a website and google won’t crawl, won’t allow me to upload a site map either. Getting only 2 links showing when I enter site:acousticimagery.net, and one of these shows a 500 error. Also, when trying to crawl, Google doesn’t like my robots.txt file. I’ve tried several edits, removing it altogether, nothing helps. My Site host is worthless, been trying to get this fixed for 2 weeks. Any input you might have would be most appreciated!!
Hello Mick! Thanks a lot for your comment.
One important problem I have been able to identify is that your server always returns a 500 error instead of a 404 error when a page does not exist. Can you think of a way to fix this?
If you want to get your pages indexed quickly, I recommend you go to “Crawl > Fetch as Google” in Google Search Console. Here you can fetch each page that is not in the index yet and then, after it has been fetched, click on “Submit to index”. This will speed up the indexing process.
I could not find a robots.txt file or an XML sitemap on your server. The robots.txt should be located at http://acousticimagery.net/robots.txt. Right now, this URL returns a 500 error code, so I assume the file does not exist or is not in this location. Your can decide how you want to name your XM sitemap, but I would recommend putting it here: http://acousticimagery.net/sitemap.xml.
Mind you, you don’t really need a robots.txt file and an XML sitemap for a website with only 4 pages (but they won’t do any harm either). Just make sure you change that thing with the wrong error codes.
Please let me know if you have any other questions.
Best regards,
Eoghan
Hello Eoghan,
Thanks for the response! Google won’t let me crawl the site as I keep getting an error saying they can’t locate the robots.txt file. I removed the file contents and tried again, still no go. Also, everytime I try to upload an XML file it tells me the file is in an invalid format. I see the 500 errors but cannot fix them. Any other ideas? This all started when I updated the site using a website builder available from Fat Cow. Very sorry I ever tried to update as I’m getting no cooperation from them on this at all. I’m thinking of just pulling the site and cancelling my Fat Cow account. You mentioned submitting each page with fetch. How do you do this?
Hi Mick,
OK, thanks for the additional information. I now have a better understanding of what is going on. The Google bot tries to access your robots.txt file at http://acousticimagery.net/robots.txt and gets a 500 server error, so it decides not to crawl the page and come back later. You can fix this by fixing the error code problem I described earlier. If http://acousticimagery.net/robots.txt returns a 404 error, everything is fine and Google crawls your page.
I do not know how this works with Fat Cow, but maybe this page will help you: http://www.fatcow.com/knowledgebase/beta/article.bml?ArticleID=620
Here’s how to submit each page to the Google index in Google Search Console:
1. In the left navigation, got to Crawl > Fetch as Google:
2. Enter the path of the page you want to submit and hit Fetch:
3. When fetching is complete, hit “Request indexing”:
4. Complete the dialogue that pops up like this:
5. Repeat for every page you want to submit to the index. Here are the paths of the pages you will want to submit:
cd-transfers
audio-recording
contact-us
I hope this helps! It will take a while until the pages show up in the search results. Let me know if there is anything else I can do for you.
Eoghan
I get a lot of page no found errors and when I checked the linked from info and click the links they clearly go to the actual page, which is not broken? It’s really annoying as the errors keep coming back.
i.e.
This error
/places/white-horse-inn/
is linked form here
http://www.seanthecyclist.co.uk/places/white-horse-inn/
Any idea what might be causing this?
Thanks
Hi Sean,
I think I might need some more information to be able to help you with this. I will send you an e-mail now.
Best regards,
Eoghan
I have been getting the same issue as Michael .
how i do to fixed this error 500 http://imgur.com/a/qE4i3
It made me lose every single keyword I was ranking for and the more I try to remove they keep coming up. As soon as I fetch the URL , search results pop back up to #2 positions for many keywords but just after a few hours looks like google crawls them again finding errors and sends the site back to the 10th page. Search rankings were gradually lost as soon as this 500 server error was discovered on webmaster.
Now I have thought about blocking /wp-includes/ but I think you cant block it anymore due to css and js which might hurt rankings even more.
Any help would be most appreciated.
Hi Donald,
You’re absolutely right, /wp-includes/ does contain some .js files that you might want Google to crawl. Your CSS is normally in /wp-content/ though.
Also, Yoast does not block /wp-includes/ by default any more (Source: https://yoast.com/wordpress-robots-txt-example/)
Nevertheless, it is probably a good idea to block all URLs that return a 500 error from the Google bot. So far, I’ve never had problems with blocking the entire /wp-includes/ directory (I still do it on this website), but it might be worth the while going through the directory and only blocking URLs that return a 500 server error.
I hope this helps!
how i do to fixed this error 500 http://imgur.com/a/qE4i3
Hello Michael,
You can block your /wp-includes/ directory from the Google bot by putting it in your robots.txt file. I recommend you install the Yoast SEO plugin for WordPress. As far as I know, it does it automatically.
I hope this helps.
Eoghan
Please see my reply to Donald’s comment (above) for an update on this issue.
Henn,
We have crawl errors in webmasters.When we remove such pages from webmasters.So within how many days that page can be removed from google Webmasters.
Hi Kevin,
For me, there are two scenarios in which I would remove a crawl error from the report:
1. If I know the error won’t occur again because I’ve either fixed it or I know it was a one-time thing.
2. If I don’t know why the error occured (i.e. why Google crawled that URL or why the URL returned an error code) and I want to see if it happens again.
WHEN you do this really doesn’t matter much. I hope this helps! Let me know if you have any other questions.
Hi Eoghan Henn,
This is kevin can u tell me after removing the page from webmasters.How many days after the page can be removed from the webmasters.
Hello Kevin,
Thanks a lot for your comment. I am not sure if I understand your question correctly. I will send you an e-mail so we can discuss this.
Best regards,
Eoghan
Please help me to fix this error.
Screenshot: http://i.imgur.com/ydZo4Wv.jpg
I’ve deleted the sample page and redirected the second url.
Hi Saud,
Unfortunately the screenshot URL is not working (any more). I will get in touch with you via email and see if I can help you.
Best regards,
Eoghan
I am getting HTTP Error: 302 error in sitemaps section. All other sitemap urls are working fine but i am getting error on main sitemap.xml. How can i resolve it?
Hello Ajay,
thanks a lot for your comment. I am not sure I understand your question very well. I will send you an e-mail so you can send me a screenshot if you like.
Best regards,
Eoghan
Hello Eoghan, I would love to know if you resolved the ‘302’ problem
I’ve had the issue of going through the wayback machine to a website but then when I click the link I need I am greeted with: ‘Got an HTTP 302 response at crawl time’ and redirected to the current website where my information is no longer.
Would really appreciate some help if you could email me.
internetuser52@gmail.com
Hi Ray,
I’ll send you an e-mail.
Eoghan
I am having this same issue (HTTP error 302) , do you mind sending me an email as well.
Thanks,
Drake
Hi Drake,
Yes, I’ll send you an e-mail 🙂
There is a nasty website that injected a redirect on our site. We found the malware and removed it, but their site is still linking to tons of URLS on our site that don’t exist–and hence creating crawler errors.
How would you suggest we fix this?
THANKS!
Jennifer
Hi Jennifer,
This does sound nasty :/
It is not easy to analyse this situation with the little bit of information I have, but I guess you do not have to worry about the crawl errors too much. Look at it this way: Somebody (a spammer) is sending the Googlebot to URLs on your website that don’t exist and have never existed. Google is clever enough to figure out that this is not your fault.
If you like, you can send me more information via email so that I can have a closer look at it.
That’s great news. Thanks for sharing Eoghan. Keep me posted!
-Chris
Hi Chris,
For now, I recommend you use Google’s Search Console API explorer. If you follow this link, the fields are already pre-filled for a list of your 404 errors with additional information about the sitemaps the false URLs are included in and the pages they are linked from:
https://developers.google.com/apis-explorer/#p/webmasters/v3/webmasters.urlcrawlerrorssamples.list
You just need to fill in your site URL (make sure you use the exact URL of your GSC property in the right format). You can then copy and paste the output and forward it your IT. I want to build a little tool that will make this easier and nicer to export, but that will take a while 🙂
Hope this helps for now! Let me know if you have any questions.
Eoghan,
That works perfectly. Thanks a ton for the detailed response and customized URL. I hope I can return the favor someday. 🙂
Thanks again,
Chris
I like this strategy.
Is there a way to download the “linked from” information in the 404 report? Would make it much easier to send the complete details to my IT team.
Hi Chris,
No, not that I know of. I check the links manually, which can be a lot of work sometimes 🙁
Hi Chris,
I did a little research and I found out that you can actually get this information through the Search Console API. Check this out:
https://developers.google.com/apis-explorer/#p/webmasters/v3/webmasters.urlcrawlerrorssamples.get?fields=urlDetails%252FlinkedFromUrls&_h=1&
I tested it for single URLs and it works. Now I’m trying to find a nice and easy way to do it for a bunch of URLs. I’ll try to make some progress with this when I have some time and I will keep you posted.
Hi,
Following a misconfiguration of another of my websites, google indexed a lot of non existant pages and now all of these pages appear in crawl errors.
I tried to set them as 410 errors to tell they doesn’t existe anymore but google keeps them in crawl errors list.
Do you know what is the best thing to do in this case ? And in a general way, for any page which is permanently deleted.
Hello Dr Emixam,
Thanks a lot for your comment snd sorry about my late reply.
From what you described, you did everything right. Just remember to mark the errors as fixed once you’ve made changes to your page. This way they should not show up again.
Let me know if you have any further questions.
Just to clarify this: Giving back a 410 code alone will not prevent the URLs from showing up in the 404 error reports – Google currently shows 410 errors as 404 errors. In order to stop the URLs from showing up in the reports, all links to the URLs need to be removed too. Otherwise, Google will keep on following the links, crawling the URLs and showing the errors in the reports. If there are external links to the URLs that cannot be removed, it might be better to use a 301 redirect to point to another URL that is relevant to the link.
Update: 410 errors now show up as 410 errors in Google Search Console, and are no longer marked as 404 errors.
Hi Eoghan-
Thanks for the great info in the article! I have an interesting (to me) issue with some of the crawl errors on our site. The total number of 404 errors is under 200 and some of them I can match to your info above. But, there are quite a few URLS that are not resolving properly due to “Chief%20Strategy%20Officer” having been appended on to each of the URLs. For example, the URL will end with “…personal-information-augmented-reality-systems/Chief%20Strategy%20Officer” and the Linked From URL is the link on our site.
I’m going to go ahead and mark all as “fixed” and see what happens, but I was wondering if you had any idea how this may have happened?
Thanks y ¡Saludos! from BCN…
Steven
Hi Steven,
Thanks for your comment! I found your website, crawled it, and found some interesting stuff that might help you. I will send you an email about this.
Best regards,
Eoghan
Hi Eoghan Henn,
I have over 1000, 404 not found errors on google search console for deleted products. What i will do to fix those errors. Can you please suggest me any way to fix them.
Thanks
Vicky
Hello Vicky,
When you have to delete a product page, you have a few options:
I hope this helps!
Hi Eoghan,
Thanks for reply,
I marked them fixed so google stop crawling them. Yes there is some deleted pages linked internally & externally. I will redirect those deleted product to similar product.
Will inform you soon about update on it.
Again thanks for reply!
Hi Vicky,
Just to clarify: Marking the errors as fixed will not make Google stop crawling them. This can only be achieved by removing all links to the URLs.
I’m looking forward to hearing about how it went for you!
Hi Eoghan,
Just wanted to give you a thumbs up! Great post and super useful to me today, right now, when I discovered a bunch of 404s on a client site who just moved from an html site to a wordpress site for some of the pages they used to rank for, ie. somepage.html.
I had used SEMRush to find as many pages as possible that they were previously ranking for and redirected them to any specific, relevant page and, when not possible, to category or broad topic pages.
The remaining crawl errors (404s) in Search Console are some pages that didn’t show up in SEMRush and of course things like “http://myclientsite.com/swf/images.swf” Since we are sensibly no longer using Flash I guess I just don’t worry about those? Not really sure.
Anyway, thanks for the great post!
Hi Chris,
Thanks for your kind words! I’m glad this article helped you.
Yes, you can just ignore the swf file errors. If you mark them as fixed I guess they won’t show up again.
Hi Eoghan,
Any thought on bigger classified ad sites handling search console?
For instance, real estate with multiple ads that expire after a certain date, having around 30k “404” or so. What would you suggest to deal with such amount of expired content?
Thanks in advance,
Hi Daniel,
Thanks a lot for your interesting question. I have no practical experience with a case like this, but let me share some thoughts:
I hope this helps!
Google treats a 410 as a 404. https://support.google.com/webmasters/answer/35120?hl=en under URL error types > Common URL errors > 404: “If permanently deleting content without intending to replace it with newer, related content, let the old URL return a 404 or 410. Currently Google treats 410s (Gone) the same as 404s (Not found).”
Hi Jules,
Thanks for linking to this source. Still, I guess that a 410 error code is the better choice when intentionally removing content. We do not have power over how Google interprets our signals, but we should do everything we can to make them as consistent as possible.
Hey Eoghan – I see your website is made with WordPress, so I was hoping you’d be able to answer my question.
I recently re-submitted my sitemap (since I thought it might be a good thing to do after disallowing /go/ in my robots.txt for affiliate links) and a few days after recrawling, I now see a new 500 error:
/wp-content/themes/mytheme/
Other notes:
– This was not present before I resubmitted my sitemap, and it’s the only 500 error I’ve seen since I launched my website a month or two ago.
– I also know that my webhost (Bluehost) tends to go down at times. Maybe this is because Google tried crawling when it was down?
– I updated my theme a few days before the 500 error appeared.
Do I need to take any action? Is there any other info I can provide?
Thanks – appreciate it.
Hi Josh! Thanks for your comment.
First of all: This is not something you should worry about, but if you have time, you might as well try to fix it 😉
Apparently, the type of URL you mentioned above always gives back a 500 server error. Check this out: I’m using a WP theme called “Hardy” and the exact same URL for my page and my theme also returns a 500 server error: https://www.rebelytics.com/wp-content/themes/hardy/. So it’s not Bluehost’s fault. (Fun fact: I will probably receive a 500 error for this now because I just placed that link here).
Now the question is: Why did the Google bot crawl your theme URL in the first place? Are you linking to it in your new sitemap? If so, you should remove the link. Your sitemap should only contain links to URLs that you want indexed. You can check where the Googlebot found the link to the URL (as mentioned in the article above). Here’s a screenshot of that:
If you find a link to that URL anywhere, just remove it. Otherwise, I guess you can just ignore this crawl error. It would be interesting to mark it as fixed and see if it shows up again. Let me know how it goes! And just give me a shout if you have any additional questions.
Best regards,
Eoghan
Awesome – thanks for the reply. It’s not linked in my sitemap and clicking on the link in GWT doesn’t show where it’s linked from, but I’ll remove it. Glad to hear it’s not really a problem.
I also had 2 other quick questions:
In general, do I only need to worry about crawl errors/warnings for relevant webpages (webpages that I want indexed and webpages that should be redirected since they’re being clicked on)? Some warnings are shown for:
/m
/mobile
/coming-soon
No idea how these appeared, and it shows they’re linked from my homepage, even though I have no idea how that is possible.
Also, my Amazon affiliate links (cloaked with /go/) got indexed a few weeks ago, and roughly a week ago, I put rel=”nofollow” for each link and also added “Disallow: /go/” under “User-agent: *” in my robots.txt.
It’s been a week, and my affiliate links are still indexed when I enter “site:mysite.com”. Do you think I’m missing anything, and how can I find out if I’m still being penalized for them?
Thanks for the help – greatly appreciated.
Hi Josh! Sorry it took me so long to reply to this one. You’re right, you should worry more about crawl errors for relevant pages that you want indexed. Nevertheless, it is always a good idea to also have a closer look at all the other crawl errors and try to avoid them in future. Sometimes, though, there’s nothing much you can do (like in the JavaScript example in the article).
What kind of redirects are you using for your Amazon affiliate links? Make sure you use a 301 redirect so they don’t get indexed.
I hope this helps!
I have same problem as Josh. But, in my error report, there is no tab for “linked from”. This is make me confuse. Why Google try to index wp-content/themes/blabla, even there is no “linked from” anywhere 😀
I think, i just mark as fixed and see whats happen next.. Thanks Eoghan Henn
Best regards from Indonesia
Hello Jimmy,
There is not always info available in the “linked from” tab. In WordPress, the theme URL shows in the source code in some context on most websites, and Google just follows these “links”. This type of error is really nothing to worry about.
Best regards,
Eoghan
Eoghan,
Thanks for the very good input. A related question: I’m getting three different numbers for Google indexed pages. 1) when I type site:mysite.com I get 200,000 and 2) when I look in Google Search Console index status it reports 117,000 and 3) when I look at crawled site map it reports only 67 pages indexed. Can you help me understand these varying index numbers? Thank you very much.
Dermid
Hello again! You get different numbers here because you are looking at three different things:
1) site:mysite.com shows you all the pages on your domain that are currently in the index. This includes all subdomains (www, non-www, mobile subdomain) and both protocols (http and https).
2) shows you all indexed pages within the Search Console property you are looking at. A Search Console property can only include URLs with a combination of one protocol and one subdomain, so if the name of your Search Console is https://www.mysite.com/, only URLs that start with https://www.mysite.com/ (and that are indexed) will show here.
3) shows you all URLs that are included in this exact sitemap and that are indexed.
I found https, http, www, non-www, and m. (mobile subdomain) pages of your domain in the Google index. You should make sure all of your pages are only available with https and decide whether you want to use www or not (this is decision a matter of taste). You can easily set this up with two 301 redirect rules: One that redirects every http URL to its https equivalent and on that redirects all non-www URLs to their www equivalents (or vice versa). Last but not least, make sure you are using the right Search Console property (so https://www.mysite.com/ or https://mysite.com/, depending on how you decide on the www or non-www matter) and post a sitemap with all the URLs you want to be indexed.
Once you’ve followed this, you should work on closing the gap between 1), 2) and 3). If you have a healthy website and you’re in control of what Google is indexing, all three numbers should be on a similar level.
Eoghan,,
Thank you. Our development team is using your advice because we have very similar issues with crawl errors. On a related note, I’m trying to understand the relationship between crawl errors and indexed URLs. When our URLs are indexed we do very well with organic search traffic. We have millions of URLs in our submitted sitemap. Within the Google Search Console our indexed URL number jumped from zero to 100K on Janurary 4th but has stayed at about that level since then. Should we expect that when we fix the crawl errors the indexed URLs will rise?
Thank you,
Dermid
Hi Dermid,
Thanks a lot for your comment and your interesting questions.
Crawl errors and indexed URLs are not always directly related. 404 errors normally occur when the Googlebot encounters faulty URLs that are not supposed to be crawled at all, for example through broken links. Server errors, on the other hand, can occur with URLs that are supposed to be indexed, so fixing these might result in a higher number of indexed URLs.
If you have millions of URLs in your sitemap, but only 100k of them are indexed, you should work on closing this gap. First of all you should check if you really want millions of URLs in your sitemap or if maybe lots of those pages aren’t relevant entry pages for users that search for your products or services in Google. It is better to have a lower number of high quality pages than having a higher number of low quality pages up for indexing.
Next, check why a big part of the URLs you submitted in your sitemaps hasn’t been indexed by Google. Note that submitting a URL in a sitemap alone will normally not lead to indexing. Google needs more signals to decide to index a page. If a large number of pages on your domain is not indexed, this is normally due to poor internal linking of the pages or poor content on the pages. Make sure that all pages you want in the Google index are linked properly internally and that they all have content that satisfies the needs of the users searching for the keywords you want to rank for.
I hope this helps!
Eoghan
Hi….Eoghan Henn
Actually my site was getting hacked after that i got a lot of errors is search console i don’t know what have to do by your tips am going to markup the errors as fixed because those URL’s are not available in my website and i removed those URL’s but the issue is one main landing page is getting 521 error code i was googled about this but i didn’t find a good solution about that and the big issue is my home page only crawled by google another pages not able to crawled even i have submitted sitemaps and using fetch us google please help me and check my website error details below and please command me a good solution about this or mail me please help me……..
hammer-testing-training-in-chennai.php
521
11/2/15
2
blog/?p=37
500
12/27/15
8
blog/?m=201504
500
12/7/15
13
userfiles/zyn2593-reys-kar-1623-moskva-rodos-ros6764.xml
521
11/2/15
14
userfiles/cez3214-aviabileti-kompanii-aer-astana-myv9933.xml
521
11/3/15
17
userfiles/wyz5836-bileti-saratov-simferopol-tsena-gif9086.xml
521
11/3/15
Hi Arun,
First of all I would like to say that I am very sorry about my late reply. I have been very busy lately and didn’t find time to reply to any comments on here.
You did the right thing marking the errors as fixed and waiting to see if they occur again. Especially 5xx errors are normally temporary. Did any of these show up again?
The other problem about important pages not being indexed is probably not related to the crawl errors problem. I am not able to determine the cause of this problem without further research, but I did find one very important problem with your website that you need to solve if you want your pages to be indexed properly:
In your main navigation, some important pages are not linked to directly, but through URLs that have a 302 redirect to the target. Example:
/hammer-testing-training-in-chennai.php is linked in the main navigation as /index.php?id=253.
/index.php?id=253 redirects to /hammer-testing-training-in-chennai.php with a 302 status code. I am not surprised that Google will not index any of the two in this case. you should make sure that you always link directly to the target URL and you should absolutely avoid redirects in internal links. And, in general, there are very few cases where a 302 reidrect is needed. Normally you will need a 301 redirect if you have to redirect a URL.
I am not sure if this is going to solve all of your problems, but fixing your internal links is definitively an important item on your to-do list. Please let me know if you have any other questions.
I have launched a new site and for some reasons I am getting an error 500 for a number of urls in webmaster tools, including the sitemap itself, When I check my logs for access to the sitemap example it shows google has accessed the sitemap and no errors where returned:
66.249.64.210 – – [29/Oct/2015:02:19:31 +0000] “GET /sitemap.php HTTP/1.1” – 10322 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Also if I access any of these urls they appear perfectly fine.
Thanks
Hello Greg, this looks like a temporary problem to me. What I would suggest is to mark the corresponding errors as fixed in the crawl error report and see if they show up again. If they do not show up again, everything is fine.
Hi
Good post! I get alo of 500 errors in GWT because of i have disabled my feeds! what should i do with that?
I have disabled feeds because other websites steal my contents!
Can you help me?
Thanks
Hello Artin, I am not quite sure if I understand your problem correctly. Which URLs return 500 errors? The URLs of your feeds? Are you still linking to them? If so, you should definitely remove the links. Also, you can check if it is possible to return a 404 instead of a 500 for your feed URLs. This would be a better signal for Google. It might even be a good idea to 301 redirect the URLs of your feeds to pages on your website, if you find a good match for every feed URL. If you explain your problem in more detail I will be happy to help.
Hey Eoghan
Thanks for your reply! i found a plugin named ”disable feeds” and it redirects all feeds to homepage, so i got rid of those 500 errors! and plus it dosn’t let those spammy sites to steal my contents.
Hello Artin, thanks a lot for sharing the info about the plugin. Sounds useful!
Good post! I have a similar problem and just don’t know how to tackle it. Google search console shows that 69 pages have errors and I discovered that the 404 errors come up whenever a ‘/’ is added after the URL.
Hello Ossai,
Google only crawls URLs that are linked somewhere, so you should first of all try to find the source if this problem. In Search Console, you can find information on where the URLs with errors are linked from. It is very likely that somewhere on your page or in your sitemap you link to those URLs with trailing slash that return 404s. You should fix those links.
The next thing you can do is make sure that all URLs that end with a slash are 301 redirected to the same URL without a trailing slash. You should only do this if all of your URLs work without trailing slash. It only requires one line in your htaccess file.
If you have any other questions I will be happy to help.
I exactly have this issue right now. Can you explain the correct htaccess code?
Hi Chris,
I am really not en expert on creating rewrite rules in htaccess files, so don’t rely on this, but this one works for me:
RewriteRule ^(.*)/$ /$1 [R,L]
Make sure you only use it for the URLs you want to use it for by setting a rewrite condition.
I hope this helps!