

Wir haben über 200 Domains gecrawlt, einschließlich aller URLs, die von ihren Homepages verlinkt sind, und der Homepages selbst, und haben die Unterschiede zwischen dem gerenderten und nicht gerenderten HTML auf jeder Seite untersucht. Eine Zusammenfassung der Ergebnisse und einige detaillierte Beispiele findest du in diesem Beitrag. Am Ende des Artikels kannst du auch auf den vollständigen Crawling-Datensatz zugreifen, den wir gesammelt und analysiert haben.
Unterschiede zwischen den beiden HTML-Versionen können bei der Indexierung eine Rolle spielen, vor allem bei größeren Websites, und sollten daher bei der Optimierung und Analyse berücksichtigt werden.
96% der Domains, die wir gecrawlt haben, weisen Unterschiede zwischen dem gerenderten HTML und dem ursprünglichen Quellcode (nicht gerendertes HTML) auf.
Von den 200 Domains, die wir gecrawlt haben, wiesen 96% Unterschiede in SEO-relevanten Bereichen wie Text, interne Links, Title Tags oder Meta Tags auf. Allerdings zeigte oft nicht jede Unterseite der Domains Unterschiede zwischen den beiden Versionen - insgesamt waren 56% der gecrawlten URLs betroffen.
Bei 81 (ca. 35%) der gecrawlten Domains gibt es nur bei den Unterseiten, nicht aber bei den Homepages Unterschiede zwischen dem gerenderten und dem nicht gerenderten HTML.
Unterschiede nach Gebiet
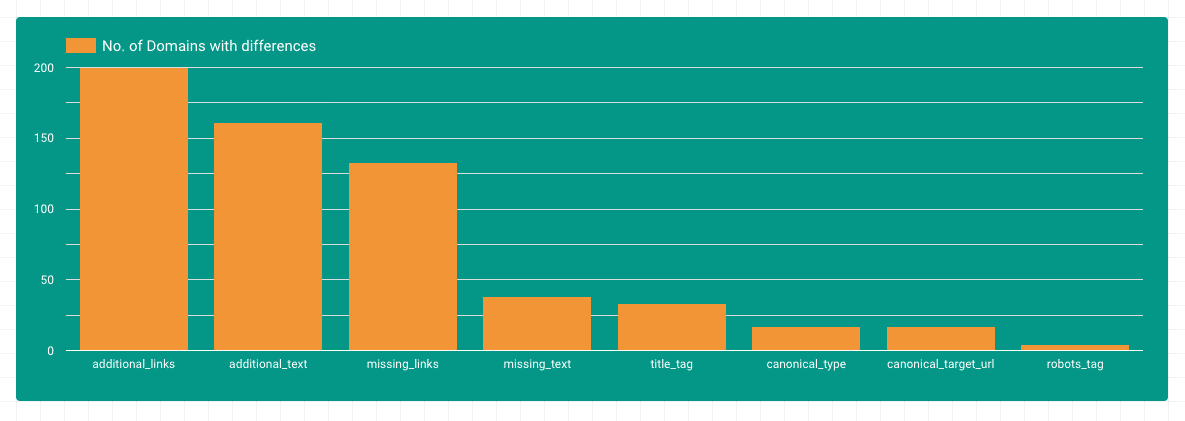
Die meisten Unterschiede finden sich in den Bereichen zusätzlicher Textund interne Links. Das macht Sinn, da JavaScript oft verwendet wird, um dynamische Inhalte in das DOM zu laden. Es fällt auch auf, dass es viele Domains gibt, in denen Links mit Hilfe von Javascript aus dem DOM entfernt werden. Unterschiede im Title-, Canonical- oder Robots-Tag sind auf weniger Domains zu finden.
Interne Verlinkung und JavaScript-Rendering
Fast alle Seiten, die wir für diese Studie gecrawlt haben, hatten zusätzliche Links im JS-gerenderten HTML. Wenn du dir die Top-Seiten ansiehst, werden manchmal bis zu 3.000 Links pro Unterseite hinzugefügt. Hier kann man davon ausgehen, dass die gesamte Hauptnavigation nur im JavaScript-gerenderten HTML verfügbar ist.

Wenn Google diese Links ignorieren würde, würden viele Strukturen und Unterseiten im Index fehlen. Daher macht es Sinn, dass Google schon seit langem versucht, die meisten der entdeckten und gecrawlten Seiten zu rendern und immer mehr Anstrengungen unternimmt, um tatsächlich alle gecrawlten Seiten zu rendern und die über JS eingefügten Links zu bewerten. Bereits 2017 beantwortete John Mueller die Frage, ob ein Link, der über JavaScript eingefügt wird, genauso PageRank erbt wie ein Link im “normalen” HTML:
Ein Link ist ein Link, unabhängig davon, wie er auf die Seite kommt. Sonst würde es nicht wirklich funktionieren.
John Müller, https://s.viu.one/013fc
Wir haben auch einige Fälle gefunden, in denen Links, die der Nutzer sieht, nicht im gerenderten HTML für Google erscheinen.
Ein Grund dafür ist, dass bestimmte Links nur dann in das gerenderte HTML geschrieben werden, wenn es ein Mouseover-Ereignis gibt. Die Links existieren weder im ursprünglichen Quellcode noch im gerenderten HTML vor der ersten Interaktion. Soweit wir wissen, führt der Googlebot derzeit keine Mouseover-Ereignisse durch - daher ist diese Art von Link für Google nicht “sichtbar”.
Ein Beispiel dafür findet man in unserem Crawl von rebuy.de - In diesem kurzen Video kann man deutlich sehen, dass die Links erst nach dem Mouseover-Ereignis erscheinen (in diesem Beispiel der Link zum iPhone XS Max im Hauptmenü):
Wenn du also bei der manuellen Analyse interner Linkstrukturen sichergehen willst, dass die Links im gerenderten HTML vorhanden sind, solltest du dir das gerenderte HTML vor jeder Benutzerinteraktion ansehen (oder eine Website Crawling Tool mit JS Rendering).
Ein weiterer Grund für fehlende Links in dem von Google gerenderten HTML kann sein, dass Anfragen durch die robots.txt-Datei blockiert werden, die für die Darstellung der Navigation benötigt wird. Dabei kann es sich um Anfragen für JavaScript-Assets handeln, ohne die die Navigation nicht funktionieren würde, oder um Ajax-Quellen, die erforderlich sind, damit die Navigation korrekt geladen wird.
Ein Beispiel aus unserem Crawl findest du auf klingel.de - Hier wird eine Ajax-Anfrage an den Server gesendet, um das Hauptmenü auf den Unterseiten zu laden, das die Kategorien zurückgibt. Wenn diese Anfrage blockiert wird (was bei Googlebot der Fall ist, aber nicht bei einem normalen Browser), funktioniert die Hauptnavigation nicht mehr:
Das kannst du mit der Chrome Extension Asset Swapper. selbst testen.
Auf der Homepage von klingel.de sind diese internen Links, anders als auf den Unterseiten, ohne Ajax-Aufruf verfügbar - der Code, der zur Anzeige der Navigation benötigt wird, wird direkt in den HTML-Quelltext geladen.
Und dann gibt es Fälle, in denen Links aus dem gerenderten HTML entfernt werden.
Hier wird das Link-Element komplett aus dem DOM gelöscht - und nicht nur ausgeblendet.

Unter mediamarkt.de, So werden zum Beispiel Links in der Hauptnavigation, die im ursprünglichen HTML vorhanden sind, aus dem gerenderten HTML auf Unterseiten gelöscht:
Google wird in diesem Fall die Links im ursprünglichen HTML entdecken und sie höchstwahrscheinlich crawlen. Es ist derzeit nicht bekannt, wie Google mit dem Signal umgeht, dass ein Link für den Nutzer offensichtlich nicht relevant ist, weil er aus dem gerenderten HTML gelöscht wurde. Es ist jedoch davon auszugehen, dass Google diese Information auf irgendeine Weise berücksichtigt.
Es ist schwer zu sagen, ob die internen Verlinkungsstrukturen aus den Beispielen unbeabsichtigt sind oder ob sie genau das sind, was die Websitebesitzer erreichen wollten. Es ist nur wichtig, solche Einflüsse bei der Optimierung zu berücksichtigen.
Zusätzlicher Inhalt
Im Bereich der Inhalte haben wir viele Domains gefunden, die zusätzliche Inhalte im gerenderten HTML enthalten.

Bei einigen von ihnen ist es vor allem der Inhalt des Zustimmungsbanners. In dem Beispiel aus wetter.com, lädt das Zustimmungsbanner eine Menge Datenschutztext über JavaScript. Hier sollte man darauf achten, dass zu viel solcher Inhalte den relevanten Inhalt nicht verwässern, wenn Google das Boilerplate nicht richtig erkennt.
In den von uns untersuchten Beispielen, in denen relevante Inhalte in das gerenderte HTML geladen werden, wurde dieser Inhalt immer von Google indexiert.
Änderungen in den Titel-Tags
Wenn wir uns die Domains ansehen, die unterschiedliche Titel-Tags im nicht gerenderten und gerenderten HTML haben, lidl.de hervorsticht:

Hier wird der Titel-Tag mit JavaScript optimiert. Wenn du dir die Ergebnisse in Google ansiehst, kannst du sehen, dass Google die Titel-Tags aus dem gerenderten HTML für die SERP-Snippets verwendet.

Bing hingegen verwendet den Titel-Tag aus dem ursprünglichen Quellcode (nicht gerendertes HTML):

Wenn du also Titel-Tags mit JavaScript änderst oder setzt, solltest du dir darüber im Klaren sein, dass andere Suchmaschinen dafür möglicherweise noch nicht bereit sind. Und wenn du eine sehr große Website hast, kann es außerdem sein, dass Google nicht alle Unterseiten rendert und den Titel-Tag aus dem ursprünglichen Quellcode für einige deiner Seiten verwendet.
Geänderte canonical und robots Tags
Bei kanonischen und robots-Tags gab es in unserer Studie nur wenige Domänen, die Unterschiede zwischen dem gerenderten HTML und dem ursprünglichen Quellcode (nicht gerendertes HTML) aufwiesen.
Es war auffällig, dass saturn.de hat einen “noindex” auf der Datenschutzseite im gerenderten HTML und überhaupt keinen robots-Meta-Tag im ursprünglichen Quelltext. Trotzdem ist die Seite im Google-Index aufgeführt. In diesem Fall scheint Google den “noindex” aus dem gerenderten HTML nicht zu berücksichtigen.
Vorsicht ist auch geboten, wenn der HTML-Kopf geändert wird oder vorzeitig geschlossen mit JavaScript. Das kann dazu führen, dass bestimmte kritische Elemente, wie z. B. kanonische Tags, außerhalb des Kopfes liegen, was bedeutet, dass sie nicht berücksichtigt werden, wenn sie nur im gerenderten HTML (aber außerhalb des Kopfes) erscheinen.
Fazit
Kaum eine Website kommt heute ohne komplexes JavaScript aus, was sich auch direkt darauf auswirkt, wie Google eine Website sieht.
Zusammenfassend kann man sagen, dass das Thema JavaScript-Rendering die Arbeit eines SEOs um eine weitere Ebene der Komplexität erweitert. Vor allem bei der internen Verlinkung gibt es verschiedene Fallstricke, die nur bei genauer Prüfung auffallen. Du solltest aber auch andere SEO-relevante Bereiche im Auge behalten, wie Title-, Canonical- oder Robots-Tags. Richtig angewendet, kannst du auch die Möglichkeiten die das JS-Rendering für die Optimierung mit sich bringt (wie das Beispiel der Titel-Tags von Lidl, das wir oben gesehen haben).
Zugang zu den vollständigen Daten
Du kannst die vollständigen Daten, die wir für diese Studie verwendet haben, gerne in einem Google Data Studio-Bericht einsehen.
Registriere dich einfach hier und du erhältst den Link zum Data Studio Dashboard per E-Mail.