

We crawled over 200 domains, including all URLs linked from their homepages and the homepages themselves, and examined the differences between the rendered and non-rendered HTML on every page. You can find a summary of the results and some detailed examples in this post. At the end of the article, you can also access the full crawling data set we collected and analysed.
Differences between the two HTML versions can play a role in indexing, especially for larger websites, and should therefore be taken into account during optimisation and analyses.
96% of the domains we crawled have differences between the rendered HTML and the original source code (non-rendered HTML).
Out of the 200 domains we crawled, 96% show differences in SEO relevant areas such as text, internal links, title tags or meta tags. However, often not every subpage of the domains showed differences between the two versions – a total of 56% of the crawled URLs were affected.
On 81 (approx. 35%) of the crawled domains, only subpages and not the homepages have differences between the rendered and non-rendered HTML.
Differences by area
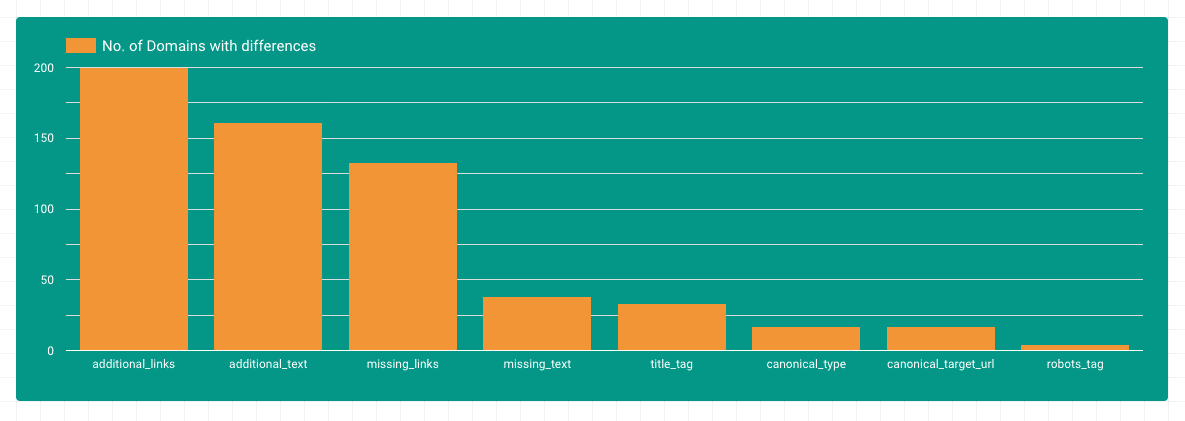
Most of the differences could be found in the areas of additional text and internal links. This makes sense, since JavaScript is often used to load dynamic content into the DOM. It is also noticeable that there are many domains where links are removed from the DOM with the help of Javascript. Differences in title, canonical or robots tags are found on fewer domains.
Internal linking and JavaScript rendering
Almost all pages that we crawled for this study had additional links in the JS-rendered HTML. If you look at the top pages, up to 3,000 links are sometimes added per subpage. Here one can assume that the entire main navigation is only available in the JavaScript-rendered HTML.

If Google ignored these links, many structures and subpages would be missing from the index. Therefore it makes sense that Google has been trying to render most of the pages it discovers and crawls for a long time and is making more and more efforts to actually render all crawled pages and to evaluate the links inserted via JS. As early as 2017, John Mueller answered the question whether a link that is added via JavaScript inherits PageRank in the same way as a link in the “normal” HTML:
A link is a link, regardless of how it comes to the page. It wouldn’t really work otherwise.
John Müller, https://s.viu.one/013fc
We also found some cases where links that the user sees do not appear in the rendered HTML for Google.
One reason for this is that certain links are only written into the rendered HTML when there is a mouseover event. The links do not exist in the original source code or in the rendered HTML before the first interaction. As far as we know, Googlebot currently does not carry out any mouseover events – therefore, this type of link is not “visible” to Google.
One can find an example of this from our crawl of rebuy.de – In this short video, you can clearly see that the links only appear after the mouseover event (in this example, the link to the iPhone XS Max in the main menu):
So, when manually analysing internal linking structures, if you want to be sure that links are available in the rendered HTML, you should look at the rendered HTML before any user interaction (or use a website crawling tool with JS rendering).
Another reason for missing links in the HTML rendered by Google can be that requests are blocked by the robots.txt file, which is needed to render the navigation. These can be requests for JavaScript assets, without which the navigation would not work, or Ajax sources that are required for the navigation to load correctly.
An example from our crawl can be found on klingel.de – Here an Ajax request is sent to the server to load the main menu on the subpages, which returns the categories. When this request is blocked (which is the case for Googlebot but not for a normal browser), the main navigation no longer works:
You can test this yourself with the Chrome Extension Asset Swapper.
On the homepage of klingel.de, unlike on the subpages, these internal links are available without the Ajax call – the code needed to show the navigation is loaded directly in the HTML source text.
And then there are cases where links are removed from the rendered HTML.
Here the link element is completely deleted from the DOM – and not just hidden.

At mediamarkt.de, for example, links in the main navigation that are present in the original HTML are deleted from the rendered HTML on subpages:
Google will discover the links in the original HTML in this case and most likely crawl them. It is currently not known how Google handles the signal that a link is apparently not relevant for the user because it is deleted from the rendered HTML. However, it can be assumed that Google takes this information into account in some way.
It is difficult to tell whether the internal linking structures from the examples are unintended or whether they are exactly what the website owners wanted to achieve. It is just important to take such influences into account when optimising.
Additional content
In the area of content, we found many domains that contain additional content in the rendered HTML.

For some of them, it is mainly the content of the consent banner. In the example from wetter.com, the consent banner loads a lot of data protection text via JavaScript. Here one should be careful that too much such content does not dilute the relevant content, if Google does not recognise the boilerplate properly.
In the examples we examined, where relevant content is loaded into the rendered HTML, this content was always indexed by Google.
Changes in title tags
If we look at the domains that have different title tags in the non-rendered and rendered HTML, lidl.de stands out:

Here the title tag is optimized using JavaScript. If you look at the results in Google, you can see that Google uses the title tags from the rendered HTML for the SERP snippets.

Bing, on the other hand, uses the title tag from the original source code (non-rendered HTML):

So if you change or set title tags using JavaScript, you should be aware that other search engines may not be ready for this yet. And also if you have a very large website, Google may not render all subpages and use the title tag from the original source code for some of your pages.
Changed canonical and robots tags
For canonical and robots tags, there were only a few domains in our study that showed differences between the rendered HTML and the original source code (non-rendered HTML).
It was noticeable that saturn.de has a “noindex” on the privacy page in the rendered HTML and no robots meta tag at all in the original source text. Still, the page is listed in the Google index. In this case, Google doesn’t seem to take into account the “noindex” from the rendered HTML.
Caution is also advised if the HTML head is changed or closed prematurely with JavaScript. This might cause certain critical elements, such as canonical tags, to be outside the head, which means that they would not be taken into account if they only appear in the rendered HTML (but outside the head).
Conclusion
Hardly any website today can do without complex JavaScript, which also has a direct impact on the way Google sees a website.
In summary, one can say that the topic of JavaScript rendering adds another level of complexity to the work of an SEO. Especially with internal linking, there are various pitfalls that are only noticeable through detailed inspections. However, you should also keep an eye on other SEO relevant areas, like title, canonical, or robots tags. Applied correctly, you can also use the possibilities that JS rendering brings for optimisation (like the title tags example from Lidl that we saw above).
Access to the complete data
You are welcome to have access to the complete data we used for this study in a Google Data Studio report.
Simply register here and you will receive the link to the Data Studio Dashboard by email.