

Auf der I/O 2018 hielten John Mueller und Tom Greenaway von Google einen hervorragenden Vortrag über SEO für JavaScript-Websites. Während des Vortrags erwähnte Tom Greenaway, dass Google nicht nach kanonischen Tags im gerenderten HTML einer Seite sucht. John Mueller bestätigte diese Aussage später mehrfach auf Twitter. Die Ankündigung machte uns neugierig, denn wir hatten zuvor Tests durchgeführt, die uns glauben ließen, dass kanonische Tags, die mit JavaScript über den Google Tag Manager injiziert werden, NICHT funktionieren. Nach der I/O-Ankündigung beschlossen wir, einen neuen Test durchzuführen. Hier sind die Ergebnisse.
Bitte beachte, dass es bei diesem Experiment nicht darum geht, ob du GTM oder JavaScript verwenden solltest, um kritische Elemente in eine Seite einzubauen oder nicht. Das Problem, auf das dieser Test abzielt, ist die Frage, wie Google mit Websites umgeht, die von clientseitigem JavaScript abhängen - eine Frage, die im Zeitalter der beliebten JavaScript-Frameworks äußerst wichtig ist.
Du bist in Eile? Springe direkt zum TL;DR Abschnitt!
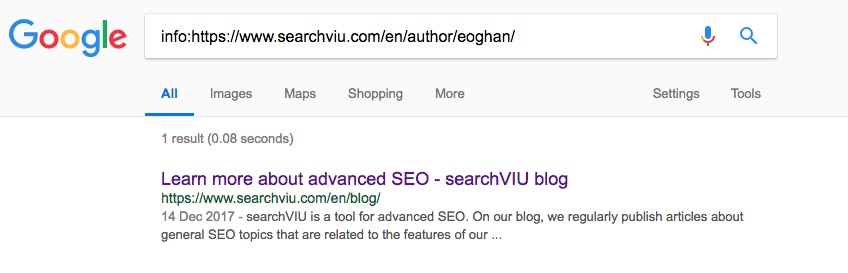 Die Kanonisierung erfolgte, nachdem wir mit dem Google Tag Manager ein kanonisches Tag mit JS injiziert hatten, und keine anderen Autoren- oder Kategorieseiten auf unserer Website waren jemals auf ähnliche Weise kanonisiert worden (mit oder ohne JS-injizierte kanonische Tags). War das wirklich nur ein Zufall?
Die Kanonisierung erfolgte, nachdem wir mit dem Google Tag Manager ein kanonisches Tag mit JS injiziert hatten, und keine anderen Autoren- oder Kategorieseiten auf unserer Website waren jemals auf ähnliche Weise kanonisiert worden (mit oder ohne JS-injizierte kanonische Tags). War das wirklich nur ein Zufall?
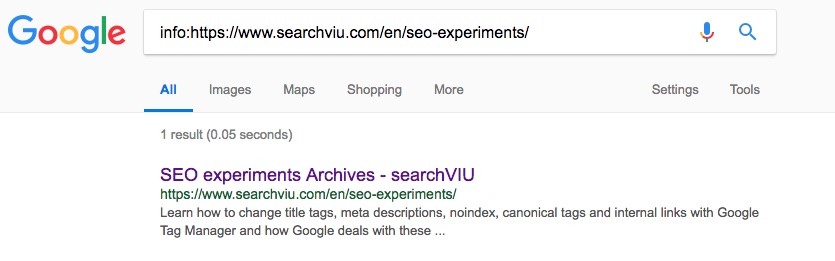 Englische Kategorieseite “SEO für Website-Relaunches”:
Englische Kategorieseite “SEO für Website-Relaunches”:
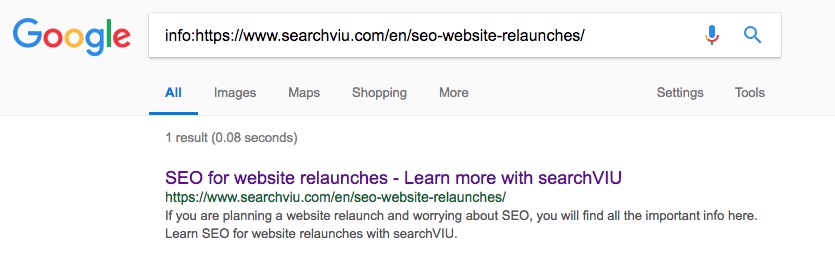 Deutsche Kategorieseite “SEO für Website-Relaunches”:
Deutsche Kategorieseite “SEO für Website-Relaunches”:
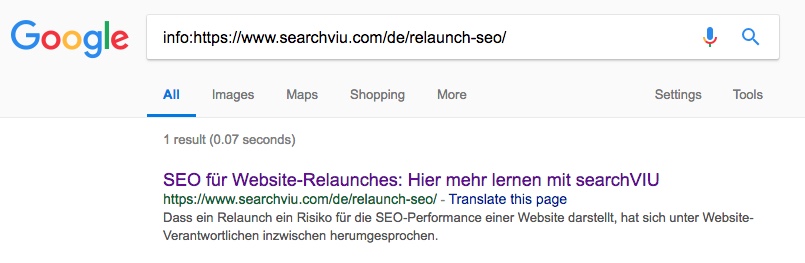 Michaels deutsche Autorenseite:
Michaels deutsche Autorenseite:
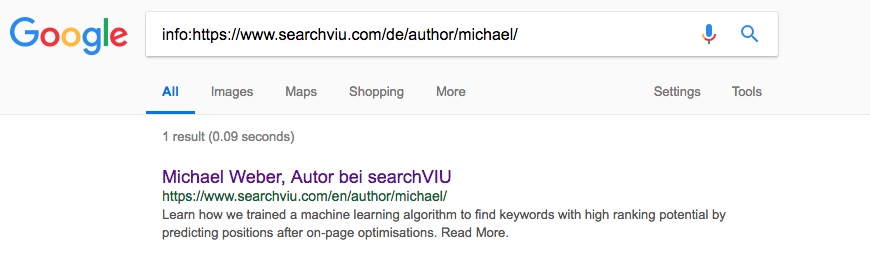 Beachte, dass die letzte Test-URL oben, Michaels deutsche Autorenseite, zum Zeitpunkt der Einrichtung des kanonischen Tags auf seine englische Autorenseite kanonisiert war, ein Problem, das wir oft bei verschiedenen Sprachversionen von Seiten sehen, die keine korrekten hreflang-Anmerkungen haben. Zum Zeitpunkt des Screenshots fehlten die hreflang-Anmerkungen, die jetzt auf der Seite zu finden sind. Keine der anderen drei Seiten war zum Zeitpunkt der Screenshots kanonisiert und unseres Wissens nach waren sie auch zu keinem Zeitpunkt in der Vergangenheit kanonisiert worden.
Beachte, dass die letzte Test-URL oben, Michaels deutsche Autorenseite, zum Zeitpunkt der Einrichtung des kanonischen Tags auf seine englische Autorenseite kanonisiert war, ein Problem, das wir oft bei verschiedenen Sprachversionen von Seiten sehen, die keine korrekten hreflang-Anmerkungen haben. Zum Zeitpunkt des Screenshots fehlten die hreflang-Anmerkungen, die jetzt auf der Seite zu finden sind. Keine der anderen drei Seiten war zum Zeitpunkt der Screenshots kanonisiert und unseres Wissens nach waren sie auch zu keinem Zeitpunkt in der Vergangenheit kanonisiert worden.
imgeduldig. Aus unserer Erfahrung mit früheren Tests wussten wir, dass dies Zeit braucht, da solche Änderungen mehrere Monate dauern können, bis sie wirksam werden. Das liegt daran, dass Google Seiten nicht so oft rendert, wie sie ohne Rendering neu gecrawlt werden, und je weniger wichtig eine Seite ist, desto seltener wird sie neu gecrawlt und noch seltener gerendert. Wenn du ein SEO-relevantes Element wie ein kanonisches Tag, eine hreflang-Anmerkung oder ein “noindex” in das gerenderte HTML einfügst, es aber nicht in das HTML-Quelldokument einfügst, musst du dich darauf einstellen, dass du lange warten musst, bis du Ergebnisse siehst.
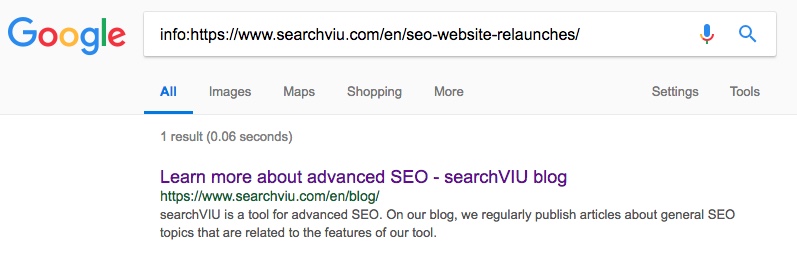 Als Nächstes wurde die englische Kategorieseite “SEO-Experimente” kanonisch gemacht. Dies dauerte deutlich länger und wir bemerkten die Veränderung am 3. Juni, 23 Tage nach dem Einfügen des kanonischen Tags:
Als Nächstes wurde die englische Kategorieseite “SEO-Experimente” kanonisch gemacht. Dies dauerte deutlich länger und wir bemerkten die Veränderung am 3. Juni, 23 Tage nach dem Einfügen des kanonischen Tags:
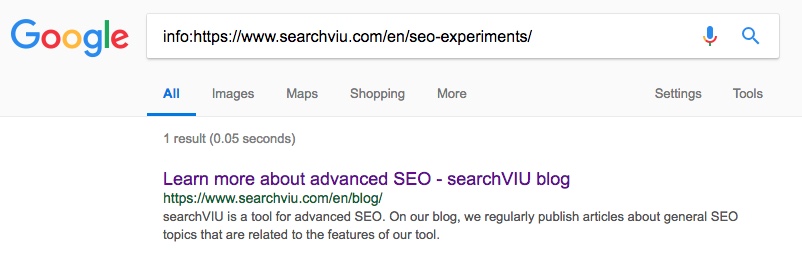 Am 4. Juni, 24 Tage nach dem Einfügen des kanonischen Tags mit JavaScript, wurde die deutsche Kategorieseite “SEO für Website-Relaunches” auf die Hauptblogseite unserer deutschen Website-Version kanonisiert:
Am 4. Juni, 24 Tage nach dem Einfügen des kanonischen Tags mit JavaScript, wurde die deutsche Kategorieseite “SEO für Website-Relaunches” auf die Hauptblogseite unserer deutschen Website-Version kanonisiert:
 Unsere vierte Test-URL, Michaels deutsche Autorenseite, ist zum Zeitpunkt des Verfassens dieses Artikels (25 Tage nach dem Einfügen des kanonischen Tags) noch nicht kanonisiert worden, aber wir sind sehr zuversichtlich, dass auch diese Seite innerhalb des nächsten Monats oder so auf das Ziel des von JS eingefügten kanonischen Tags kanonisiert werden wird:
Unsere vierte Test-URL, Michaels deutsche Autorenseite, ist zum Zeitpunkt des Verfassens dieses Artikels (25 Tage nach dem Einfügen des kanonischen Tags) noch nicht kanonisiert worden, aber wir sind sehr zuversichtlich, dass auch diese Seite innerhalb des nächsten Monats oder so auf das Ziel des von JS eingefügten kanonischen Tags kanonisiert werden wird:
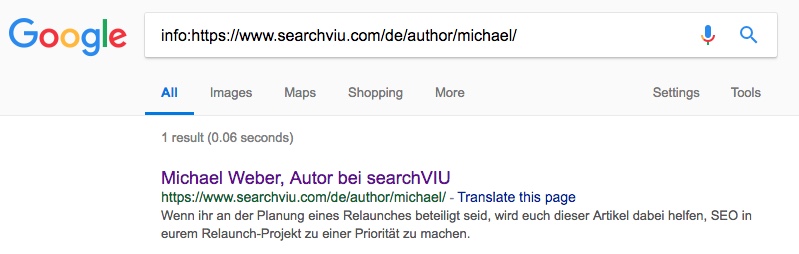 Update (13. Juni 2018): Diese URL ist jetzt kanonisiert worden, 34 Tage nach dem Einfügen des kanonischen Tags.
Was denkst du, wenn du dir diese Daten ansiehst? Ist es ein Zufall, dass drei unserer vier Test-URLs auf die Ziele der kanonischen Tags, die wir mit JavaScript injiziert haben, kanonisiert worden sind? Oder verwendet Google immer noch JS-injizierte kanonische Tags, obwohl sie offiziell erklärt haben, dass dies nicht der Fall ist? Und wenn ja, warum haben sie gesagt, dass sie es nicht tun?
Bevor wir voreilige Schlüsse ziehen, sollten wir über einige andere Dinge sprechen, die du über diesen Test wissen solltest.
Update (13. Juni 2018): Diese URL ist jetzt kanonisiert worden, 34 Tage nach dem Einfügen des kanonischen Tags.
Was denkst du, wenn du dir diese Daten ansiehst? Ist es ein Zufall, dass drei unserer vier Test-URLs auf die Ziele der kanonischen Tags, die wir mit JavaScript injiziert haben, kanonisiert worden sind? Oder verwendet Google immer noch JS-injizierte kanonische Tags, obwohl sie offiziell erklärt haben, dass dies nicht der Fall ist? Und wenn ja, warum haben sie gesagt, dass sie es nicht tun?
Bevor wir voreilige Schlüsse ziehen, sollten wir über einige andere Dinge sprechen, die du über diesen Test wissen solltest.
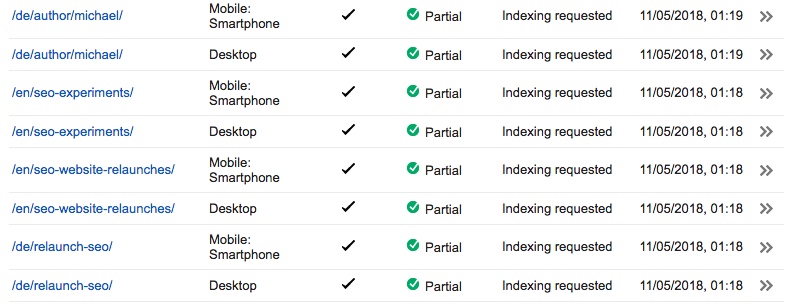 Am 22. Mai forderten wir Crawling und Indexierung für unsere Hauptblogseiten und alle verlinkten Seiten an, da alle unsere Test-URLs direkt von den Hauptblogseiten verlinkt sind. Am 1. Juni führten wir einen weiteren “Fetch and render > Request indexing” für die drei verbleibenden Test-URLs durch, die zu diesem Zeitpunkt noch nicht kanonisiert worden waren.
Wir wissen, dass “Fetch and render > Request indexing” normalerweise eine fast sofortige Wirkung hat, wenn du damit eine neue URL übermittelst. Es scheint aber keinen Einfluss auf das Rendern einer Seite zu haben, zumindest nicht immer. Unser Antrag vom 1. Juni könnte die Kanonisierung von zwei unserer Test-URLs am 3. und 4. Juni ausgelöst haben, aber der Antrag vom 11. Mai hatte sicherlich keine unmittelbare Auswirkung. Ein weiterer Faktor könnte sein, dass Google eine Seite mehr als einmal darstellen muss, bevor es entscheidet, ein eingefügtes kanonisches Tag zu übernehmen.
Am 22. Mai forderten wir Crawling und Indexierung für unsere Hauptblogseiten und alle verlinkten Seiten an, da alle unsere Test-URLs direkt von den Hauptblogseiten verlinkt sind. Am 1. Juni führten wir einen weiteren “Fetch and render > Request indexing” für die drei verbleibenden Test-URLs durch, die zu diesem Zeitpunkt noch nicht kanonisiert worden waren.
Wir wissen, dass “Fetch and render > Request indexing” normalerweise eine fast sofortige Wirkung hat, wenn du damit eine neue URL übermittelst. Es scheint aber keinen Einfluss auf das Rendern einer Seite zu haben, zumindest nicht immer. Unser Antrag vom 1. Juni könnte die Kanonisierung von zwei unserer Test-URLs am 3. und 4. Juni ausgelöst haben, aber der Antrag vom 11. Mai hatte sicherlich keine unmittelbare Auswirkung. Ein weiterer Faktor könnte sein, dass Google eine Seite mehr als einmal darstellen muss, bevor es entscheidet, ein eingefügtes kanonisches Tag zu übernehmen.
 Die beiden Test-URLs, die am 3. und 4. Juni kanonisiert wurden, werden immer noch als “Eingereicht und indexiert” angezeigt, weil die Daten, die GSC anzeigt, nicht aktuell sind, aber ich erwarte, dass sie in den nächsten Tagen als “Eingereichte URL nicht als kanonisch ausgewählt” angezeigt werden.
Wenn Google ein kanonisches Tag auf einer Seite findet und es respektiert, sollten wir erwarten, dass der Status der URL im neuen Indexbericht “Alternate page with proper canonical tag” lautet. Was ist hier los?
Ich habe eine einfache Theorie, um dies zu erklären: Der Indexabdeckungsbericht der Google Search Console verhält sich genau so, wie es Tom Greenaway und John Mueller auf und nach der I/O angekündigt haben: Er ignoriert kanonische Tags, die nicht im HTML-Quelldokument enthalten sind. Er spiegelt also das Verhalten wider, das Google offiziell kommuniziert, und nicht das, das die Ergebnisse dieses Tests offenbaren.
Die Google Search Console hat Informationen darüber, welche URLs indexiert werden, und sie hat eine Reihe von Regeln, die sie setzt voraus. Google für die Indizierung verwendet. Dann verwendet es dieses Regelwerk, um Berichte zu erstellen. Wenn sich das Regelwerk, das GSC für die Erstellung seiner Berichte verwendet, von den Regeln unterscheidet, die Google tatsächlich für die Indizierung verwendet, zeigen die Berichte falsche Informationen.
Das scheint bei den JS-injected canonical tags der Fall zu sein: Google verwendet sie, um Seiten kanonisch zu machen, aber GSC glaubt, dass es das nicht tut. Deshalb werden diese URLs am Ende als “Übermittelte URL nicht als kanonisch ausgewählt” statt als “Alternative Seite mit richtigem kanonischen Tag” markiert. Und das könnte auch erklären, warum John Mueller 100% davon überzeugt ist, dass Google keine JS-injected canonical Tags verwendet:
Ich bin mir sicher, dass John Mueller genau weiß, wie der GSC funktioniert, und ich bin mir auch sicher, dass das GSC-Team genaue Informationen liefern will. Aber wenn es innerhalb von Google ein Missverständnis oder einfach nur einen Fehler gibt (JS-injected canonical tags sollten nicht verwendet werden, werden es aber), dann können selbst offizielle Aussagen und Berichte von Google falsch sein.
Die beiden Test-URLs, die am 3. und 4. Juni kanonisiert wurden, werden immer noch als “Eingereicht und indexiert” angezeigt, weil die Daten, die GSC anzeigt, nicht aktuell sind, aber ich erwarte, dass sie in den nächsten Tagen als “Eingereichte URL nicht als kanonisch ausgewählt” angezeigt werden.
Wenn Google ein kanonisches Tag auf einer Seite findet und es respektiert, sollten wir erwarten, dass der Status der URL im neuen Indexbericht “Alternate page with proper canonical tag” lautet. Was ist hier los?
Ich habe eine einfache Theorie, um dies zu erklären: Der Indexabdeckungsbericht der Google Search Console verhält sich genau so, wie es Tom Greenaway und John Mueller auf und nach der I/O angekündigt haben: Er ignoriert kanonische Tags, die nicht im HTML-Quelldokument enthalten sind. Er spiegelt also das Verhalten wider, das Google offiziell kommuniziert, und nicht das, das die Ergebnisse dieses Tests offenbaren.
Die Google Search Console hat Informationen darüber, welche URLs indexiert werden, und sie hat eine Reihe von Regeln, die sie setzt voraus. Google für die Indizierung verwendet. Dann verwendet es dieses Regelwerk, um Berichte zu erstellen. Wenn sich das Regelwerk, das GSC für die Erstellung seiner Berichte verwendet, von den Regeln unterscheidet, die Google tatsächlich für die Indizierung verwendet, zeigen die Berichte falsche Informationen.
Das scheint bei den JS-injected canonical tags der Fall zu sein: Google verwendet sie, um Seiten kanonisch zu machen, aber GSC glaubt, dass es das nicht tut. Deshalb werden diese URLs am Ende als “Übermittelte URL nicht als kanonisch ausgewählt” statt als “Alternative Seite mit richtigem kanonischen Tag” markiert. Und das könnte auch erklären, warum John Mueller 100% davon überzeugt ist, dass Google keine JS-injected canonical Tags verwendet:
Ich bin mir sicher, dass John Mueller genau weiß, wie der GSC funktioniert, und ich bin mir auch sicher, dass das GSC-Team genaue Informationen liefern will. Aber wenn es innerhalb von Google ein Missverständnis oder einfach nur einen Fehler gibt (JS-injected canonical tags sollten nicht verwendet werden, werden es aber), dann können selbst offizielle Aussagen und Berichte von Google falsch sein.
Rückblick auf unseren Test “Kanonische Tags über GTM” vom letzten Jahr
Die Ankündigung von Google hat uns überrascht, denn unsere früheren Tests hatte angedeutet, dass kanonische Tags und andere SEO-relevante Elemente immer aus dem gerenderten HTML gezogen werden, sobald sie verfügbar sind, und nicht mehr aus dem HTML-Quelldokument. Hatte Google die Art und Weise geändert, wie sie mit JS-injizierten kanonischen Tags umgehen? Oder war unsere Interpretation der früheren Testergebnisse falsch? Kanonisches Tag Testergebnis vom letzten Jahr basierte auf nur einer URL. Wir hatten also ziemlich schwache Beweise für die Behauptung, dass Google kanonische Tags verwendet, die mit JS injiziert werden. Das Ergebnis unseres Tests könnte einfach nur ein großer Zufall gewesen sein: Google könnte sich aus anderen Gründen dazu entschieden haben, unsere Test-URL mit dem Ziel unseres JS-injizierten kanonischen Tags zu kanonisieren. Das ist ein allgemeines Problem, wenn du testest, ob kanonische Tags funktionieren oder nicht: Du kannst canonical Tags wirklich nur zwischen sehr ähnlichen Seiten verwenden, die wahrscheinlich sowieso kanonisiert werden. Andernfalls riskierst du, dass deine kanonischen Tags gänzlich ignoriert werden. Andererseits kannst du, wenn deine Seiten mit kanonischen Tags kanonisiert werden, nicht 100% sicher sein, dass dies wirklich auf die kanonischen Tags zurückzuführen ist. Hinweis: Wenn du denkst: “Warum prüfen sie nicht einfach die neuen GSC-Indexabdeckungsberichte?”, dann habe bitte Geduld und lies weiter. Wir kommen schon noch dazu. Bei unserem Test im letzten Jahr haben wir ein kanonisches Tag in meine Autorenseite auf der englischen Version dieses Blogs eingefügt, das auf die Hauptseite des Blogs verweist. Seitdem ist die Autorenseite auf die Hauptblogseite kanonisiert, was sich mit Hilfe eines info: Suchoperator für die URL in Google (Screenshot vom 11. Mai 2018):
Die Kanonisierung erfolgte, nachdem wir mit dem Google Tag Manager ein kanonisches Tag mit JS injiziert hatten, und keine anderen Autoren- oder Kategorieseiten auf unserer Website waren jemals auf ähnliche Weise kanonisiert worden (mit oder ohne JS-injizierte kanonische Tags). War das wirklich nur ein Zufall?
Einrichten unseres neuen Tests nach der E/A
Nach Googles Ankündigung auf der I/O wollten wir genau dieses Ergebnis für weitere URLs replizieren. Also haben wir JS und GTM verwendet, um kanonische Tags, die auf die Hauptblogseite zeigen, in vier weitere Kategorie- und Autorenseiten auf unserem Blog einzufügen. Wir haben auch darauf geachtet, zwei ähnliche Seiten (meine deutsche Autorenseite und Michaels englische Autorenseite) unberührt zu lassen, um eine Kontrollgruppe von URLs zu haben, die keine kanonischen Tags erhalten, die auf andere Seiten verweisen, und die daher von Google nicht kanonisiert werden sollten. Wenn eine unserer Kontroll-URLs auf die Hauptblogseite kanonisiert wurde, ohne dass wir ein kanonisches Tag eingefügt haben, könnte das bedeuten, dass die Test-URLs aus anderen Gründen als den von JS eingefügten kanonischen Tags kanonisiert wurden. Hier sind die vier neuen Test-URLs, für die wir am 11. Mai, einen Tag nach Googles I/O-Ankündigung, JS-injizierte kanonische Tags eingerichtet haben (alle Screenshots wurden am 11. Mai aufgenommen). Englisch “SEO Experimente” Kategorieseite:
Englische Kategorieseite “SEO für Website-Relaunches”:
Deutsche Kategorieseite “SEO für Website-Relaunches”:
Michaels deutsche Autorenseite:
Beachte, dass die letzte Test-URL oben, Michaels deutsche Autorenseite, zum Zeitpunkt der Einrichtung des kanonischen Tags auf seine englische Autorenseite kanonisiert war, ein Problem, das wir oft bei verschiedenen Sprachversionen von Seiten sehen, die keine korrekten hreflang-Anmerkungen haben. Zum Zeitpunkt des Screenshots fehlten die hreflang-Anmerkungen, die jetzt auf der Seite zu finden sind. Keine der anderen drei Seiten war zum Zeitpunkt der Screenshots kanonisiert und unseres Wissens nach waren sie auch zu keinem Zeitpunkt in der Vergangenheit kanonisiert worden.
Warten auf die Ergebnisse
Nachdem wir die kanonischen Tags eingefügt hatten, warteten wirGoogle beginnt, unsere Test-URLs zu kanonisieren
Die erste unserer Testseiten, die auf das Ziel unseres JS-injizierten canonical Tags kanonisiert wurde, war unsere englische Kategorieseite “SEO für Website-Relaunches”. Wir bemerkten die Änderung am 21. Mai, 10 Tage nach der Einfügung des canonical Tags. Hier ist ein aktueller Screenshot der entsprechenden info: Suchoperator Ergebnis:
Als Nächstes wurde die englische Kategorieseite “SEO-Experimente” kanonisch gemacht. Dies dauerte deutlich länger und wir bemerkten die Veränderung am 3. Juni, 23 Tage nach dem Einfügen des kanonischen Tags:
Am 4. Juni, 24 Tage nach dem Einfügen des kanonischen Tags mit JavaScript, wurde die deutsche Kategorieseite “SEO für Website-Relaunches” auf die Hauptblogseite unserer deutschen Website-Version kanonisiert:
Unsere vierte Test-URL, Michaels deutsche Autorenseite, ist zum Zeitpunkt des Verfassens dieses Artikels (25 Tage nach dem Einfügen des kanonischen Tags) noch nicht kanonisiert worden, aber wir sind sehr zuversichtlich, dass auch diese Seite innerhalb des nächsten Monats oder so auf das Ziel des von JS eingefügten kanonischen Tags kanonisiert werden wird:
Update (13. Juni 2018): Diese URL ist jetzt kanonisiert worden, 34 Tage nach dem Einfügen des kanonischen Tags.
Was denkst du, wenn du dir diese Daten ansiehst? Ist es ein Zufall, dass drei unserer vier Test-URLs auf die Ziele der kanonischen Tags, die wir mit JavaScript injiziert haben, kanonisiert worden sind? Oder verwendet Google immer noch JS-injizierte kanonische Tags, obwohl sie offiziell erklärt haben, dass dies nicht der Fall ist? Und wenn ja, warum haben sie gesagt, dass sie es nicht tun?
Bevor wir voreilige Schlüsse ziehen, sollten wir über einige andere Dinge sprechen, die du über diesen Test wissen solltest.
“Fetch and render > Request indexing” in GSC scheint die Dinge nicht zu beschleunigen
Nachdem wir am 11. Mai die kanonischen Tags eingefügt hatten, führten wir für alle unsere Test-URLs einen “Fetch and render > Request indexing” durch:
Am 22. Mai forderten wir Crawling und Indexierung für unsere Hauptblogseiten und alle verlinkten Seiten an, da alle unsere Test-URLs direkt von den Hauptblogseiten verlinkt sind. Am 1. Juni führten wir einen weiteren “Fetch and render > Request indexing” für die drei verbleibenden Test-URLs durch, die zu diesem Zeitpunkt noch nicht kanonisiert worden waren.
Wir wissen, dass “Fetch and render > Request indexing” normalerweise eine fast sofortige Wirkung hat, wenn du damit eine neue URL übermittelst. Es scheint aber keinen Einfluss auf das Rendern einer Seite zu haben, zumindest nicht immer. Unser Antrag vom 1. Juni könnte die Kanonisierung von zwei unserer Test-URLs am 3. und 4. Juni ausgelöst haben, aber der Antrag vom 11. Mai hatte sicherlich keine unmittelbare Auswirkung. Ein weiterer Faktor könnte sein, dass Google eine Seite mehr als einmal darstellen muss, bevor es entscheidet, ein eingefügtes kanonisches Tag zu übernehmen.
Der neue Search Console Indexabdeckungsbericht sagt nicht die ganze Wahrheit
Zum Zeitpunkt des Verfassens dieser Zeilen werden unsere Test-URL vom letzten Jahr und unsere neue Test-URL, die am 21. Mai kanonisiert wurde, im neuen Indexabdeckungsbericht der Google Search Console als “Eingereichte URL nicht als kanonisch ausgewählt” angezeigt:
Die beiden Test-URLs, die am 3. und 4. Juni kanonisiert wurden, werden immer noch als “Eingereicht und indexiert” angezeigt, weil die Daten, die GSC anzeigt, nicht aktuell sind, aber ich erwarte, dass sie in den nächsten Tagen als “Eingereichte URL nicht als kanonisch ausgewählt” angezeigt werden.
Wenn Google ein kanonisches Tag auf einer Seite findet und es respektiert, sollten wir erwarten, dass der Status der URL im neuen Indexbericht “Alternate page with proper canonical tag” lautet. Was ist hier los?
Ich habe eine einfache Theorie, um dies zu erklären: Der Indexabdeckungsbericht der Google Search Console verhält sich genau so, wie es Tom Greenaway und John Mueller auf und nach der I/O angekündigt haben: Er ignoriert kanonische Tags, die nicht im HTML-Quelldokument enthalten sind. Er spiegelt also das Verhalten wider, das Google offiziell kommuniziert, und nicht das, das die Ergebnisse dieses Tests offenbaren.
Die Google Search Console hat Informationen darüber, welche URLs indexiert werden, und sie hat eine Reihe von Regeln, die sie setzt voraus. Google für die Indizierung verwendet. Dann verwendet es dieses Regelwerk, um Berichte zu erstellen. Wenn sich das Regelwerk, das GSC für die Erstellung seiner Berichte verwendet, von den Regeln unterscheidet, die Google tatsächlich für die Indizierung verwendet, zeigen die Berichte falsche Informationen.
Das scheint bei den JS-injected canonical tags der Fall zu sein: Google verwendet sie, um Seiten kanonisch zu machen, aber GSC glaubt, dass es das nicht tut. Deshalb werden diese URLs am Ende als “Übermittelte URL nicht als kanonisch ausgewählt” statt als “Alternative Seite mit richtigem kanonischen Tag” markiert. Und das könnte auch erklären, warum John Mueller 100% davon überzeugt ist, dass Google keine JS-injected canonical Tags verwendet:
Ich bin mir sicher, dass John Mueller genau weiß, wie der GSC funktioniert, und ich bin mir auch sicher, dass das GSC-Team genaue Informationen liefern will. Aber wenn es innerhalb von Google ein Missverständnis oder einfach nur einen Fehler gibt (JS-injected canonical tags sollten nicht verwendet werden, werden es aber), dann können selbst offizielle Aussagen und Berichte von Google falsch sein.
TL;DR
- Google hat kürzlich bekannt gegeben, dass kanonische Tags nicht verarbeitet werden, wenn sie nur im gerenderten HTML und nicht im HTML-Quelldokument zu finden sind.
- Wir haben dies getestet, indem wir mithilfe von GTM kanonische Tags in vier URLs eingefügt haben, und unsere Testergebnisse legen nahe, dass Google macht diese kanonischen Tags verwenden.
- Es dauerte mehr als drei Wochen, bis einige der getesteten URLs zu den Zielen der JS-injizierten canonical Tags kanonisiert waren.
- Die Funktion “Abrufen und Rendern > Indexierung anfordern” in der Google Search Console scheint nicht dazu beizutragen, das Rendern von Seiten zu beschleunigen.
- Der neue Indexabdeckungsbericht in der Google Search Console ignoriert JS-injizierte kanonische Tags in seinen Berichten und steht damit im Einklang mit den offiziellen Aussagen von Google.
- Der Grund, warum Google eine Ankündigung gemacht hat, die scheinbar falsch ist, könnte ein internes Missverständnis oder ein Fehler sein.
Eine Antwort
Ich weiß, dass dies ein alter Blogartikel ist, aber ich bin immer noch auf der Suche nach der Antwort auf die Frage, ob ich JS verwenden kann, um die kanonischen Tags für Google zu generieren, oder ist das einfach unmöglich?