

Wir haben über 200 Domains inklusive aller auf der Startseite verlinkten URLs gecrawlt und die Unterschiede zwischen dem gerenderten HTML und dem Original-Quelltext untersucht. Die Ergebnisse und einige Beispiele findet ihr in diesem Beitrag.
Unterschiede zwischen den beiden HTML-Versionen können, gerade bei größeren Webseiten, eine Rolle bei der Indexierung spielen und sollten daher bei der Optimierung berücksichtigt werden.
96% der gecrawlten Domains haben Unterschiede zwischen dem gerenderten HTML und dem Original-Quelltext.
96% der gecrawlten Domains haben Unterschiede in SEO-relevanten Bereichen wie Text, internen Links, Title- oder Meta-Tags. Dabei wies jedoch häufig nicht jede Unterseite der Domains Unterschiede zwischen den beiden Versionen auf – insgesamt waren 56% der gecrawlten URLs betroffen.
Bei 81 (ca. 35%) der gecrawlten Domains weisen nur Unterseiten und nicht die Startseite Unterschiede zwischen dem gerenderten HTML und dem Original-Quelltext auf.
Unterschiede nach Bereichen
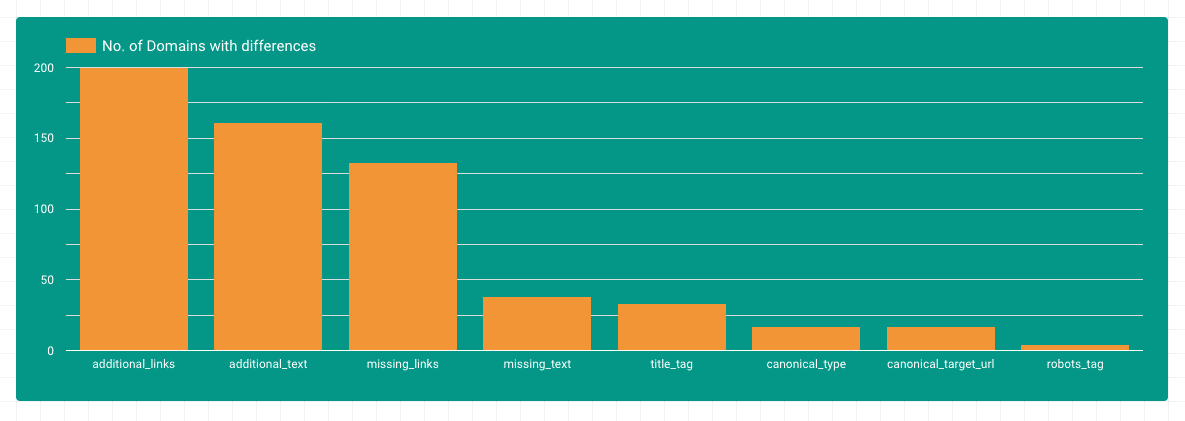
Die meisten Unterschiede gab es in den Bereichen zusätzlicher Text und zusätzliche Inhalte. Das macht auch Sinn, da dynamische Inhalte über Javascript in das DOM geladen werden. Auffällig ist auch, dass es viele Domains gibt, bei denen Links durch Javascript aus dem DOM entfernt werden. Unterschiede in Title-, Canonical- oder Robots-Tags sind bei weniger Domains zu finden.
Interne Verlinkung & JavaScript-Rendering
Auf fast allen gecrawlten Seiten gab es zusätzliche Links im JS-gerenderten HTML. Wenn man sich die Top-Seiten anschaut, werden teilweise fast 3.000 Links je Unterseite hinzugefügt. Hier kann man davon ausgehen, dass die gesamte Hauptnavigation hauptsächlich im Javascript-gerenderten HTML verfügbar ist.

Würde Google diese Links nicht berücksichtigen, würden viele Strukturen und Unterseiten im Index fehlen. Daher macht es Sinn, dass Google schon seit längerer Zeit die meisten Seiten rendert und immer mehr Bemühungen anstellt, wirklich alle gecrawlten Seiten auch zu rendern und die per JS eingefügten Links zu werten. Schon 2017 hat John Müller auf die Frage geantwortet, ob ein Link der per JavaScript hinzugefügt wird, genau so PageRank vererbt wie ein Link im normalen HTML:
A link is a link, regardless of how it comes to the page. It wouldn’t really work otherwise.
John Müller, https://s.viu.one/013fc
Wir haben einige Fälle gefunden, bei denen Links, die der User sieht, nicht im gerenderten HTML für Google auftauchen.
Ein Grund dafür ist, dass bestimmte Links erst bei einem Mouseover-Event in das gerenderte HTML geschrieben werden. Im Original-Quelltext und im gerenderten HTML (ohne Interaktion) sind die Links nicht vorhanden. Soweit bekannt führt der Googlebot aktuell keine Mouseover-Events aus – Daher ist diese Art von Links für Google nicht „sichtbar“.
Ein Beispiel hierfür aus unserem Crawl ist auf rebuy.de zu finden – In diesem kurzen Video kann man gut nachvollziehen, dass die Links erst nach dem Mouseover-Event auftauchen (Beispiel iPhone XS Max aus dem Hauptmenü):
Wenn man also sichergehen will, dass Links bereits im gerenderten HTML vorhanden sind, sollte man sich das gerenderte HTML vor jeglicher Nutzer-Interaktion anschauen.
Ein weiterer Grund für im durch Google gerenderten HTML fehlende Links kann sein, dass Requests durch die robots.txt-Datei geblockt werden, die zum Rendern der Navigation benötigt werden. Das können Requests nach JavaScript-Assets sein, ohne die die Navigation nicht funktioniert, oder auch Ajax-Quellen, die für die Navigation benötigt werden.
Ein Beispiel aus unserem Crawl ist auf klingel.de zu finden – Hier wird zum laden des Hauptmenüs auf Unterseiten ein Ajax-Request an den Server gesendet, der die Kategorien zurückliefert. Sobald dieser geblockt ist, funktioniert die Navigation nicht mehr:
Testen kann man das z.B. mit der Chrome Extension Asset Swapper – Einfach den entsprechenden Request auf einen 404 laufen lassen.
Auf der Startseite sind bei klingel.de die Links auch ohne den Ajax-Call vorhanden – Hier werden die Daten für die Navigation direkt im HTML-Quelltext mit übergeben.
Und dann gibt es noch die Fälle, bei denen Links aus dem gerenderten HTML entfernt werden.
Hier wird das Link-Element aus dem DOM komplett gelöscht – und nicht nur ausgeblendet.

Bei mediamarkt.de beispielsweise werden Links der Hauptnavigation, die im Original-HTML vorhanden waren, auf Unterseiten gelöscht:
Google wird die Links im Original-HTML in diesem Fall finden. Wie Google jetzt aber mit dem Signal umgeht, dass ein Link scheinbar für den Nutzer nicht relevant ist und gelöscht wird, ist aktuell nicht bekannt. Man kann aber davon ausgehen, dass Google diese Information in irgendeiner Weise berücksichtigt.
Ob die Strukturen aus den Beispielen für die interne Verlinkung ggf. genau so gewollt sind, ist schwer zu sagen. Wichtig ist nur, dass man solche Einflüsse bei der Optimierung berücksichtigt.
Zusätzliche Inhalte
Im Bereich der Inhalte gibt es viele Domains, die im gerenderten HTML zusätzliche Inhalte enthalten.

Bei einigen davon ist es hauptsächlich der Inhalt des Consent-Banners. Im Beispiel von wetter.com wird durch den Consent-Banner sehr viel Datenschutztext per JavaScript geladen. Hier sollte man aufpassen, dass zu viele solcher Inhalte nicht den relevanten Inhalt verwässern, falls Google die Boilerplate nicht sauber erkennt.
In den von uns untersuchten Beispielen, bei denen relevanter Text nachgeladen wird, wurde dieser auch durch Google indexiert.
Änderungen in Title Tags
Schaut man sich die Domains an, die unterschiedliche Title Tags, haben fällt lidl.de ins Auge:

Hier wird der Title-Tag per JavaScript optimiert. Wenn man sich die Ergebnisse in Google ansieht, kann man erkennen, dass Google hier dieTitel-Tags aus dem gerenderten HTML übernimmt.

Bing verwendet hingegen den Title-Tag aus dem Original-Quelltext:

Wenn man also Title-Tags per JavaScript ändert oder setzt, sollte man sich bewusst sein, dass andere Suchmaschinen evtl. noch nicht so weit sind. Auch wenn man große Webseiten hat kann es sein, dass Google nicht alle Unterseiten rendert und für einzelne Seiten dann den Title-Tag aus dem Original-Quelltext verwendet.
Geänderte Canonical- & Robots-Tags
Bei Canonical- und Robots-Tags gab es in unserer Studie nur wenige Domains, die Unterschiede zwischen dem gerenderten HTML und dem Original-Quelltext aufwiesen.
Auffällig war, das saturn.de auf der Privacy-Seite im gerenderten HTML ein „noindex“ hat und im Original-Quelltext gar keinen Robots-Meta-Tag. Die Seite wird bei Google im Index aber gelistet. In dem Fall scheint Google den „noindex“ aus dem gerenderten HTML nicht zu berücksichtigen.
Vorsicht ist auch geboten, wenn durch ein JavaScript der Head-Bereich verändert oder frühzeitig geschlossen wird. Dadurch kann der Canonical-Tag ausserhalb des Heads stehen, wodurch er nicht mehr berücksichtigt wird, falls der Tag nur im gerenderten HTML vorkommt.
Fazit
Kaum eine Webseite kommt heute noch ohne komplexes JavaScript aus, was auch direkte Auswirkungen auf die Art & Weise hat, wie Google eine Webseite sieht.
Zusammengefasst kann man sagen, dass das Thema JavaScript-Rendering noch einen weitere Ebenean Komplexität in die Arbeit eines SEOs bringt. Speziell bei der internen Verlinkung sind dort verschieden Fallstricke drin, die sich nur sehr langsam bemerkbar machen. Aber auch die anderen Bereiche sollte man im Auge behalten. Ggf. kann man die Möglichkeiten, die das JS-Rendering mitbringt, auch zur Optimierung (z.B. der Title Tags) nutzen.
Zugriff auf die kompletten Daten
Gerne könnt ihr Zugriff auf die kompletten Daten als Datastudio Report haben.
Einfach hier eintragen und du erhälts den Link zum Data Studio Dashboard per eMail.