

In order to be able to predict position changes after possible on-page optimisation measures, we trained a machine learning model with keyword data and on-page optimisation factors. With the help of this model, we can now automatically analyse thousands of potential keywords and select the ones that we have good chances on reaching interesting rankings for, with just a few simple on-page optimisations.
At the end of this article, we share the entire source code of this machine learning SEO experiment with you, so that you can try it out yourself!
Would you like to read or share this article in a different language? There are German and French translations of this article available.
The rise of machine learning in SEO
Google has been working on implementing machine learning into their products and services for a while now. With the help of machine learning, they are able to achieve things that would be very difficult or even impossible to do without it.
As SEOs, we might be watching this development with a bit of fear. If machine learning is applied to search algorithms, these algorithms get more and more complex and more difficult to understand, which makes our jobs significantly harder.
But why don’t we just use machine learning for SEO, in order to keep up with Google? If SEO gets harder because of machine learning, the best way to tackle this challenge is by using machine learning ourselves, right?
In this post, we will show you, with the help of a practical example, how you can use machine learning to improve your search engine optimisation efforts.
The case – Identifying keywords with high ranking potential by predicting position changes after optimisations
As SEOs, whenever we want to find keyword data, there are lots of great tools at our disposal. The challenge is not finding keywords, but analysing and prioritising them. Let’s start by looking at the keyword data SEMrush gives us for our example website www.barf-alarm.de. We are interested in keywords we are already ranking for, that have high search volumes.
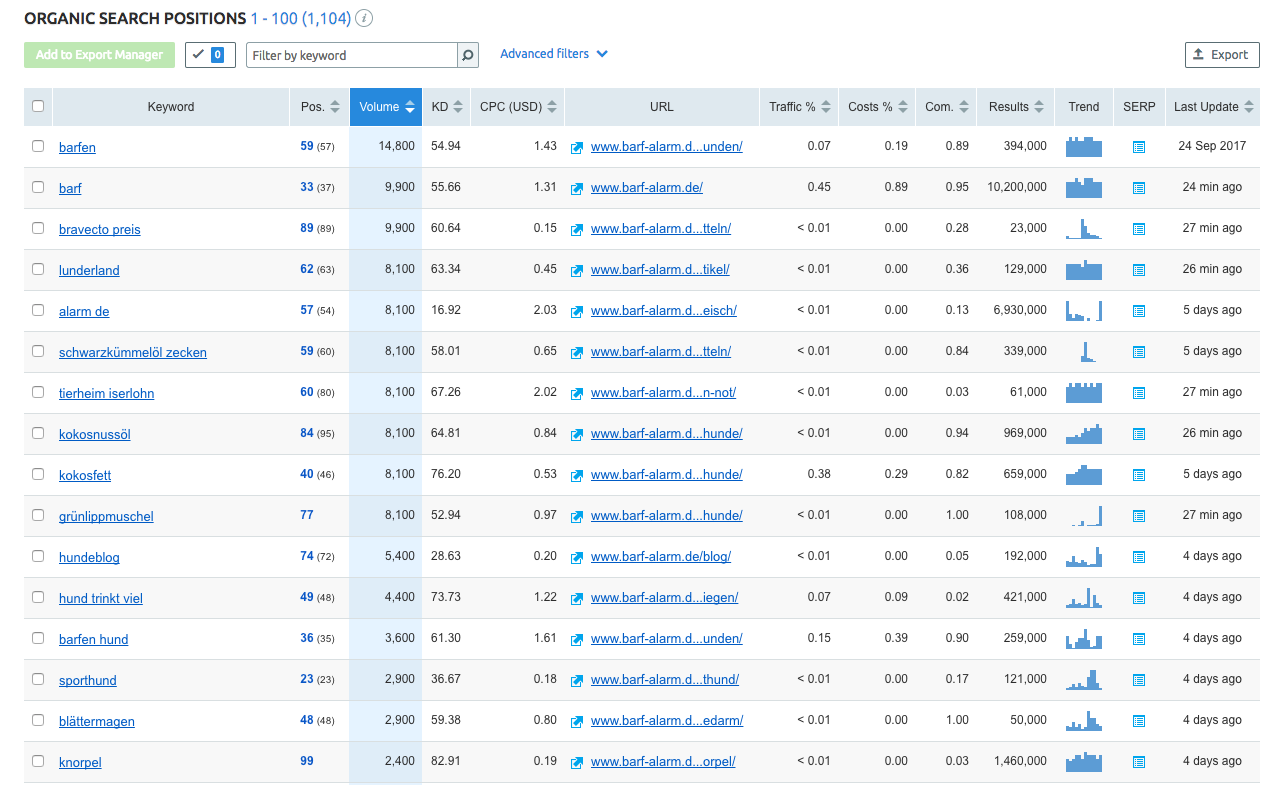
As you can see in the screenshot, SEMrush already provides us with a high number of keywords (more than 1100) for the very nichey topic of the example website.
By adding keywords that our competitors rank for, but we don’t, we can easily extend this keyword set to more than 3600 keywords:

This is still not a very big number of keywords compared to analyses for bigger websites or broader topics, but it is already an amount that would be very challenging to analyse manually. Still, we need to filter these keywords in order to find out which ones are relevant and which ones we have chances of getting a top 10 position for by optimising certain pages on our website.
Let’s do it the machine learning way! Our goal is to identify for which of the 3600 keywords that we have collected, a top 10 position is possible.
Using machine learning to identify ranking potential – step by step
Step 1: Thinking about how we would do this task manually
If we wanted to filter our list of 3600 keywords down to a handful of keywords with high ranking potential manually, we would probably look at metrics like search volume and CPC in order to get a feeling for the competitive situation of every keyword. High search volumes and high CPCs usually indicate high competition for a keyword, which makes it more difficult to achieve good rankings.
We can also analyse our competitors. If a very similar competitor is ranking in the top 10 for a keyword we are targeting, it is likely that we can achieve such a ranking as well.
Last but not least, we can have a look at on-page optimisation factors. If one of our pages is already really well optimised for a certain keyword, but only ranking on page two or three, it is going to be very difficult to improve the rankings further with on-page optimisation measures. If, on the other hand, we don’t have a page that is targeting a keyword or only a page that isn’t very well optimised, it is more likely that we can reach the top 10 for this keyword with on-page optimisation measures.
We can use the same data that we would normally analyse manually to train our machine learning algorithm. Let’s have a look at the next steps to learn how this works.
Step 2: Gathering and transforming the data we need
Now we need to collect the data that we would normally use to perform the manual analyses described above. For this experiment, we use SEMrush’s API to pull data about all of the keywords our example website and its competitors are ranking for:

After collecting this data, we crawl all of the ranking pages of our example website and the competitors’ websites and check if the phrase the page is ranking for is contained in the title, content, URL path or domain of the ranking page. We save the information about this as a number, because the machine learning algorithm we are using only works with numbers and doesn’t accept text as an input. So, for example, if all words of the phrase “barfen fleisch” that a page ranks for are found in the title tag of that page, we save the value “1” in “title_found”. If only one of the words (50% of all words) is found, we save the value “0.5”, and if no words from the phrase are found, we save the value “0”.

Now we also transcribe all domains and keywords to representing numbers, so that we can feed them into our machine learning algorithm. Putting it all together, we now have list of pages ranking for keywords with information on the competitive situation (CPC and search volume) and basic on-page factors.

Step 3: Training the machine learning model
Next, we split our data into training (80%) and test (20%) data. The training data will be needed to train the machine learning algorithm, and the test data to test the results the algorithm delivers. We then choose an algorithm, in this case an MLPClassifier, and train the algorithm. Based on different tests, we believe that a neural network based algorithm works best for this type of application.
This is the part where your machine has to do a lot of hard work and you might have to wait a few minutes. Or hours…
Step 4: Predicting rankings for optimised landing pages
With the model we have generated, we can now make predictions. In our example, we predict the ranking of our website www.barf-alarm.de for the phrase “barf fleisch kaufen”, using the information we have gathered before and the optimisation values of the page (phrase not found in title or URL and only partially found in in content and domain name). Our trained algorithm predicts position 20 for the page, based on the information we just provided:
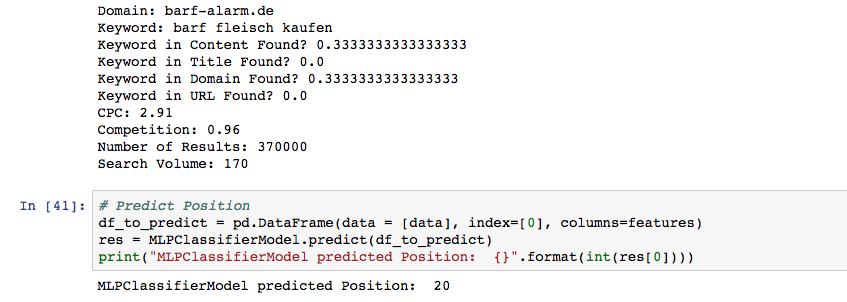
If we look back at our test data, our website actually ranks on position 18 for this phrase. This means that our machine learning algorithm is not 100% accurate yet, but not bad for a start:
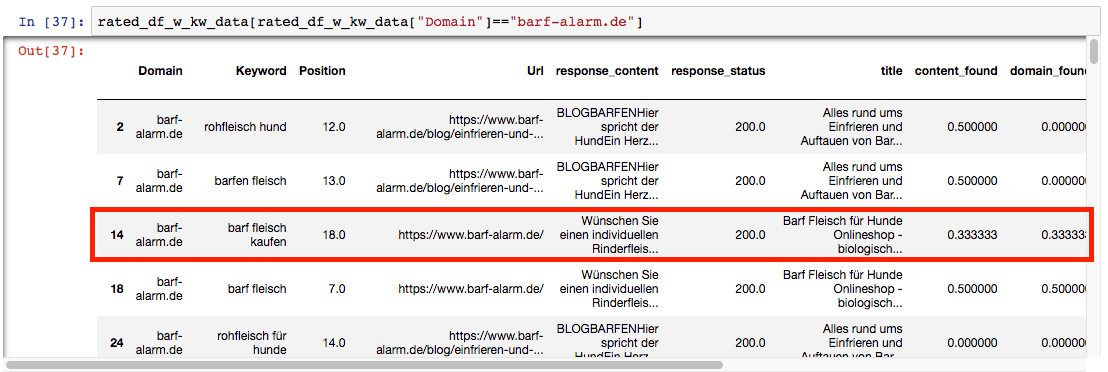
Now, let’s see what our algorithm predicts for an optimised version of this page, so one where the phrase is found in the title and in the content of the page. We want to know if it would make sense to optimise this page, so we ask our algorithm what position it thinks we will rank on if we optimise a page for this phrase. We feed the algorithm with the same data as before, except that the phrase is included in the title and in the content this time.
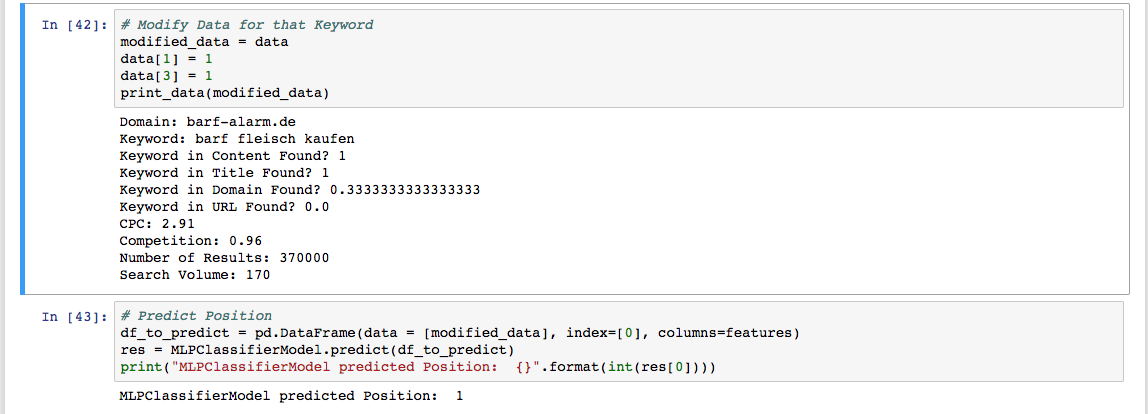
Oh wow, our model predicts position 1 for a page that is optimised for this phrase. We already know that our algorithm is not 100% accurate yet, but it works fine for the purpose of this experiment: Identifying keywords with a high ranking potential. Let’s see if the predictions for other phrases look more realistic!
Step 5: Getting a full result for all potential keywords we have identified
So let’s do what we just did for all of the 3600 keywords we collected in the beginning. Our model generates a list of keywords with current and predicted positions:
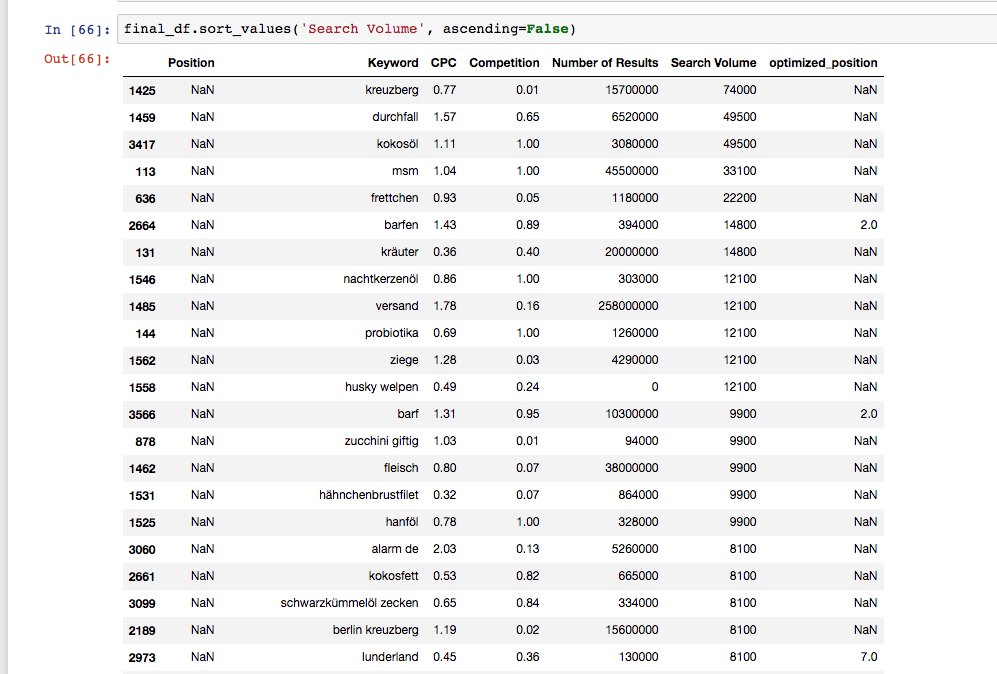
As you can see in the snapshot above, the model does not predict any rankings for irrelevant keywords like “kreuzberg” (a district of Berlin), “durchfall” (diarrea) or “ziege” (goat). This is a sign of quality: We would not expect to be able to rank well for keywords that are not really relevant to our business.
Let’s filter the list a bit more for an even better result. If we apply a filter for predicted rankings under 10, we get a list of keywords for which our algorithm thinks we can rank on page 1 of Google:

This is a great result! We now have a list of about 600 mostly relevant keywords with a high chance of ranking on the first page of Google after some very simple on-page optimisations (including the phrases in title tags and page content). We do not have to check 3600 keywords manually and we can start working on creating optimised pages for 600 keywords our machine learning algorithm selected. There might be some false positives and the ranking predictions are probably a bit too enthusiastic in some cases, but this is a very good starting point for a decent on-page optimisation.
Final considerations
We used some really basic data in this example, especially for optimisation measures. We only looked at a few factors, such as keyword placement in title tags and the content of pages. It would certainly make sense to add some more relevant data, such as external links or TF*IDF analyses. Our example is just a basic demonstration of what is possible with machine learning in SEO.
Also, by extracting more ranking data than we did here and by analysing more competitors and more keywords, your predictions should get better. There is also potential for optimising the parameters of the machine algorithm or using a better algorithm altogether.
Do you want to try this out yourself?
We have provided the full source code of this experiment (Python, Jupyter Notebook) in our open searchVIU Labs Github repository. This way, you can try this experiment for your own website and with your own data.
In our repository, you will also find a simple machine learning example for predicting CTR based on Google Search Console data, which might be interesting for your first steps into machine learning for SEO.
Thanks!
We would like to thank our friends at SEMrush for providing the data we needed for this experiment. If you need an account or credits for the SEMrush API in order to try this out yourself, you can get in contact with Evgeni Sereda at SEMrush.
Also, we would like to thank the organisers of SEO Day, the biggest SEO conference in Germany, for letting us present this experiment for the first time at their event this year.
4 Responses
This is awesome! I will be checking out the provided learning model. I’ve been beginning to research out different use cases for deep learning and SEO. I feel like it’s an area that is definitely going to change the game for SEO and if we don’t adapt with it, we’re going to be in trouble. Thanks for sharing your study.
This is exactly what we’ve been hunting for. While there are a lot of tools on the market now which boast predictive analysis for SERP performance, like BrightEdge or MarketBrew, why not build it yourself if you have the talent to do so? Would have loved to been there when you originally presented this. Great work!
This is awesome, thank you for sharing. I just forked the repo and plan on experimenting with this myself. I’m an R user, so working in Python will be a nice change of pace. It will be interesting to see what I come up with.
Interesting method. I have started my python quest, so this will be helpful. Another way to understand your chances is the Google volatility score, which is a serious alternative to other competition scores